



Motivating example
考虑一个随机变量X,我们的目标是估计E[X]。如果我们得到了一系列采样值{xi}i=1N\{x_i\}_{i=1}^N{xi}i=1N,那么X的期望可以被近似为E[X]≈xˉ:=1N∑i=1Nxi\mathbb{E}[X]\approx\bar{x}:=\frac{1}{N}\sum_{i=1}^Nx_iE[X]≈xˉ:=N1i=1∑Nxi且:xˉ→E[X] as N→∞:\bar{x}\to\mathbb{E}[X]\mathrm{~as~}N\to\infty:xˉ→E[X] as N→∞,这就是蒙特卡洛估计的基本思想。
那么我们要怎么计算xˉ\bar{x}xˉ呢。有两种方式:
- 方式一:收集所有样本数据然后计算平均值
- 缺点:收集样本需要一段时间,只能等待收集完成
- 方式二:通过一种增量和迭代的方式规避这种缺点
下面详细介绍方式二:
假设
wk+1=1k∑i=1kxi,k=1,2,…w_{k+1}=\frac{1}{k}\sum_{i=1}^kx_i,\quad k=1,2,\ldots wk+1=k1i=1∑kxi,k=1,2,…
那么 wk=1k−1∑i=1k−1xi,k=2,3,…w_{k}=\frac{1}{k-1}\sum_{i=1}^{k-1}x_i,\quad k=2,3,\ldotswk=k−11i=1∑k−1xi,k=2,3,…
由此可以得到wk+1w_{k+1}wk+1和wkw_kwk的递推关系:
wk+1=1k∑i=1kxi=1k(∑i=1k−1xi+xk)=1k((k−1)wk+xk)=wk−1k(wk−xk).\begin{aligned}
w_{k+1}=\frac{1}{k}\sum_{i=1}^{k}x_{i} & =\frac{1}{k}\left(\sum_{i=1}^{k-1}x_i+x_k\right) \\
& =\frac{1}{k}((k-1)w_{k}+x_{k})=w_{k}-\frac{1}{k}(w_{k}-x_{k}).
\end{aligned}wk+1=k1i=1∑kxi=k1(i=1∑k−1xi+xk)=k1((k−1)wk+xk)=wk−k1(wk−xk).
因此,我们获得了这样的迭代算法:wk+1=wk−1k(wk−xk).w_{k+1}=w_k-\frac{1}{k}(w_k-x_k).wk+1=wk−k1(wk−xk).
通过这个公式来增量的计算xˉ\bar{x}xˉ:
w1=x1,w2=w1−11(w1−x1)=x1,w3=w2−12(w2−x2)=x1−12(x1−x2)=12(x1+x2),w4=w3−13(w3−x3)=13(x1+x2+x3),wk+1=1k∑i=1kxi.\begin{aligned}
w_{1} & =x_{1}, \\
w_{2} & =w_1-\frac{1}{1}(w_1-x_1)=x_1, \\
w_{3} & =w_{2}-\frac{1}{2}(w_{2}-x_{2})=x_{1}-\frac{1}{2}(x_{1}-x_{2})=\frac{1}{2}(x_{1}+x_{2}), \\
w_{4} & =w_3-\frac{1}{3}(w_3-x_3)=\frac{1}{3}(x_1+x_2+x_3), \\
w_{k+1} & =\frac{1}{k}\sum_{i=1}^kx_i.
\end{aligned}w1w2w3w4wk+1=x1,=w1−11(w1−x1)=x1,=w2−21(w2−x2)=x1−21(x1−x2)=21(x1+x2),=w3−31(w3−x3)=31(x1+x2+x3),=k1i=1∑kxi.
关于这个算法:
- 优点是,当获得一个采样值之后,期望的估计值可以马上计算得到,接着期望估计值可以马上被利用于其他目的
- 由于采样不充分(wk≠E(X)w_k ≠ E(X)wk=E(X))导致期望估计值在初期并不准确,但是聊胜于无,且随着采样值的增多,这个估计值会逐渐趋于准确(wk→E[X] 当 k→∞w_k\to\mathbb{E}[X]\mathrm{~当~}k\to\inftywk→E[X] 当 k→∞)
更进一步,考虑一个通用表示方式,将1k\frac{1}{k}k1换αk\alpha_kαk(αk>0\alpha_k>0αk>0)得到
wk+1=wk−αk(wk−xk)w_{k+1}=w_k-\alpha_k(w_k-x_k) wk+1=wk−αk(wk−xk)
只要{αk\alpha_kαk}满足一些条件,我们仍然可以通过这个公式得到均值E(X)
这个算法是一个特殊的SA算法(Stochastic approximation),也是一个特殊的随机梯度下降(stochastic gradient descent algorithm)算法。
RM算法(Robbins-Monro algorithm)
假设我们要找到g(w)=0g(w)=0g(w)=0的根,其中w∈R,g:Rw \in R, g: Rw∈R,g:R,即定义域和值域都是R。
很多问题都可以转化为上面的求根问题。比如,假设J(w)是要最小化的目标函数。然后这个最优化问题可以转化为计算它导数为0方程的求解:g(w)=∇wJ(w)=0g(w)=\nabla_wJ(w)=0g(w)=∇wJ(w)=0
那么怎么计算g(w)=0的问题呢?
如果g的表达式或者导数已知,那么很多数学算法都可以求解。
如果g的表达式未知呢?比如g是一个人工神经网络。此时RM算法可以解决这个问题。
RM算法
wk+1=wk−akg~(wk,ηk),k=1,2,3,…w_{k+1}=w_k-a_k\tilde{g}(w_k,\eta_k),\quad k=1,2,3,\ldotswk+1=wk−akg~(wk,ηk),k=1,2,3,…
- wkw_kwk是根的第k个估计值
- g~(wk,ηk)=g(wk)+ηk\tilde{g}(w_k,\eta_k)=g(w_k)+\eta_kg~(wk,ηk)=g(wk)+ηk是第k个含噪声的观测值。因为我们在采样时得到的不是准确的g(w),包含一定噪声
- aka_kak是一个正系数
g(w)是一个黑盒函数,即我们不知道它具体的表达式,但是可以采样到输入和输出数据。因此这个算法将依赖于采样到的数据:
- 输入序列{wkw_kwk}
- 包含噪声的输出序列:{g~(wk,ηk)}\{\tilde{g}(w_k,\eta_k)\}{g~(wk,ηk)}
RM算法举例
使用RM算法解决g(w)=w-10
取w1=20,ak≡0.5,ηk=0w_1=20,a_k\equiv0.5,\eta_k=0w1=20,ak≡0.5,ηk=0(这个例子不考虑观测噪声)
w1=20⟹g(w1)=10w2=w1−a1g(w1)=20−0.5∗10=15⟹g(w2)=5w3=w2−a2g(w2)=15−0.5∗5=12.5⟹g(w3)=2.5:wk→10\begin{aligned}
& \mathrm w_{1}=20\Longrightarrow g(w_{1})=10 \\
& \mathrm w_2 =w_{1}-a_{1}g(w_{1})=20-0.5*10=15\Longrightarrow g(w_{2})=5 \\
& w_3=w_2-a_2g(w_2)=15-0.5*5=12.5\Longrightarrow g(w_3)=2.5 \\
& \mathrm{:} \\ & w_{k}\to10
\end{aligned}w1=20⟹g(w1)=10w2=w1−a1g(w1)=20−0.5∗10=15⟹g(w2)=5w3=w2−a2g(w2)=15−0.5∗5=12.5⟹g(w3)=2.5:wk→10
收敛性
RM收敛性举例分析
以g(w)=tanh(w-1)为例,可以看到g(w)=0的根w*=1。
如果使用RM算法计算:
设置w1=3,ak=1/k,ηk≡0w_1=3,a_k=1/k,\eta_k\equiv0w1=3,ak=1/k,ηk≡0(没有噪声为了简化计算)
那么RM算法的公式为wk+1=wk−akg(wk)w_{k+1}=w_k-a_kg(w_k)wk+1=wk−akg(wk),因为g~(wk,ηk)=g(wk) 当 ηk=0\tilde{g}(w_k,\eta_k)=g(w_k)\mathrm{~当~}\eta_k=0g~(wk,ηk)=g(wk) 当 ηk=0
通过机器仿真得到:

可以看到wkw_kwk向根w*=1收敛,wk+1w_{k+1}wk+1比wkw_kwk离w更近。
分析:
当wk>w∗w_k>w^*wk>w∗,有g(wk)>0g(w_k)>0g(wk)>0,那么wk+1=wk−akg(wk)<wkw_{k+1}=w_k-a_kg(w_k)<w_kwk+1=wk−akg(wk)<wk,则wk+1w_{k+1}wk+1比wkw_kwk离w更近
当wk<w∗w_k<w^*wk<w∗,有g(wk)<0g(w_k)<0g(wk)<0,那么wk+1=wk−akg(wk)>wkw_{k+1}=w_k-a_kg(w_k)>w_kwk+1=wk−akg(wk)>wk,则wk+1w_{k+1}wk+1比wkw_kwk离w*更近
RM收敛条件
在RM算法中,求解g(w)=0,设真实根为w∗w^*w∗,如果
1)0<c1≤∇wg(w)≤c2for allw;2)∑k=1∞ak=∞and∑k=1∞ak2<∞;3)E[ηk∣Hk]=0 and E[ηk2∣Hk]<∞,其中Hk={wk,wk−1,…}\begin{gathered}
1)0<c_1\leq\nabla_wg(w)\leq c_2\mathrm{for~all}w; \\
2)\sum_{k=1}^{\infty}a_{k}=\infty\mathrm{and}\sum_{k=1}^{\infty}a_{k}^{2}<\infty; \\
\mathrm{3)}\mathbb{E}[\eta_k|\mathcal{H}_k]=0\mathrm{~and~}\mathbb{E}[\eta_k^2|\mathcal{H}_k]<\infty ,其中\mathcal{H}_k=\{w_k,w_{k-1},\ldots\}
\end{gathered}1)0<c1≤∇wg(w)≤c2for allw;2)k=1∑∞ak=∞andk=1∑∞ak2<∞;3)E[ηk∣Hk]=0 and E[ηk2∣Hk]<∞,其中Hk={wk,wk−1,…}
那么wkw_kwk收敛于w∗w^*w∗
解释一下这三个条件:
- 0<c1≤∇wg(w)≤c2 for all w0<c_1\leq\nabla_wg(w)\leq c_2\text{ for all }w0<c1≤∇wg(w)≤c2 for all w
- g的导数必须是正数
- g严格单调增加
- 这确保了g(w)=0的根存在且唯一
- ∑k=1∞ak=∞且∑k=1∞ak2<∞\sum_{k=1}^{\infty}a_{k}=\infty\mathrm{且}\sum_{k=1}^{\infty}a_{k}^{2}<\infty∑k=1∞ak=∞且∑k=1∞ak2<∞
- ∑k=1∞ak2<∞\sum_{k=1}^{\infty}a_{k}^{2}<\infty∑k=1∞ak2<∞确保当k→∞k \to \inftyk→∞时aka_kak收敛于0
- ∑k=1∞ak=∞\sum_{k=1}^{\infty}a_{k}=\infty∑k=1∞ak=∞确保aka_kak不会收敛过快
- E[ηk∣Hk]=0 and E[ηk2∣Hk]<∞\mathbb{E}[\eta_k|\mathcal{H}_k]=0\mathrm{~and~}\mathbb{E}[\eta_k^2|\mathcal{H}_k]<\inftyE[ηk∣Hk]=0 and E[ηk2∣Hk]<∞
- {ηk\eta_kηk}是一个idd随机序列,满足E[ηk]=0且E[ηk2]<∞\mathbb{E}[\eta_{k}]=0\mathrm{且}\mathbb{E}[\eta_{k}^{2}]<\inftyE[ηk]=0且E[ηk2]<∞,观察值误差ηk\eta_kηk并不需要是高斯分布
- idd,独立同分布,Independent and Identically Distributed,简称idd
再详细解释一下第二个条件
∑k=1∞ak2<∞∑k=1∞ak=∞\sum_{k=1}^\infty a_k^2<\infty\quad\sum_{k=1}^\infty a_k=\inftyk=1∑∞ak2<∞k=1∑∞ak=∞
首先,∑k=1∞ak2<∞\sum_{k=1}^\infty a_k^2<\infty∑k=1∞ak2<∞表示随着k→∞k \to \inftyk→∞时,ak→0a_k \to 0ak→0
为什么需要这个条件?
因为wk+1−wk=−akg~(wk,ηk)w_{k+1}-w_k=-a_k\tilde{g}(w_k,\eta_k)wk+1−wk=−akg~(wk,ηk)
- 当k→∞,wk→w∗k \to \infty, w_k\to w^*k→∞,wk→w∗,那么必然有wk+1−wk→0w_{k+1}-w_k \to 0wk+1−wk→0
- 而g~(wk,ηk)\tilde{g}(w_k,\eta_k)g~(wk,ηk)此时被ηk\eta_kηk所影响
- 此时ak→0a_k \to 0ak→0,则akg~(wk,ηk)→0a_k\tilde{g}(w_k,\eta_k) \to 0akg~(wk,ηk)→0
- 因此等式左边也→0,等式右边也→0
再考虑第二个条件,∑k=1∞ak=∞\sum_{k=1}^\infty a_k=\infty∑k=1∞ak=∞表明aka_kak不能太快收敛到0
为什么需要这个条件:
w2−w1=−a1g~(w1,η1)w3−w2=−a2g~(w2,η2)...wk+1−wk=−akg~(wk,ηk)w_2 - w_1=-a_1\tilde{g}(w_1,\eta_1) \\
w_3 - w_2=-a_2\tilde{g}(w_2,\eta_2) \\
... \\
w_{k+1} - w_k=-a_k\tilde{g}(w_k,\eta_k) \\
w2−w1=−a1g~(w1,η1)w3−w2=−a2g~(w2,η2)...wk+1−wk=−akg~(wk,ηk)
将上面的等式相加得到
w1−w∞=∑k=1∞akg~(wk,ηk).w_1-w_\infty=\sum_{k=1}^\infty a_k\tilde{g}(w_k,\eta_k).w1−w∞=k=1∑∞akg~(wk,ηk).
假设w∞=w∗w_{\infty}=w^*w∞=w∗
如果∑k=1∞ak<∞\sum_{k = 1}^{\infty}a_k < \infty∑k=1∞ak<∞(即∑k=1∞ak\sum_{k = 1}^{\infty}a_k∑k=1∞ak收敛 ),那么∑k=1∞akg~(wk,ηk)\sum_{k = 1}^{\infty}a_k\tilde{g}(w_k,\eta_k)∑k=1∞akg~(wk,ηk)可能有界
如果初始猜测值w1w_1w1选取得离w∗w^*w∗任意远, 那么w1−w∞≠∑k=1∞akg~(wk,ηk)w_1 - w_\infty ≠ \sum_{k = 1}^{\infty}a_k\tilde{g}(w_k,\eta_k)w1−w∞=∑k=1∞akg~(wk,ηk)
什么样的{aka_kak}可以满足上面的条件:ak=1ka_k=\frac{1}{k}ak=k1
RM算法在期望估计上的应用
回到最初推导的期望递推式wk+1=wk+αk(xk−wk)w_{k+1}=w_k+\alpha_k(x_k-w_k)wk+1=wk+αk(xk−wk)
- 我们知道,如果αk=1/k\alpha_{k}=1/kαk=1/k,则wk+1=1/k∑i=1kxiw_{k+1}=1/k\sum_{i=1}^{k}x_{i}wk+1=1/k∑i=1kxi
- 那么如果αk\alpha_{k}αk不是1/k呢?结果是仍然可以得到期望,因为这是一种特殊的RM算法
对第二种情况进行分析
(1)考虑一个函数:g(w)≐w−E[X]g(w)\doteq w-\mathbb{E}[X]g(w)≐w−E[X],我们的目标是解g(w)=0的方程,那么得到的根就是E[X]
(2)对X进行采样得到xxx,我们将xxx近似为E[x],则得到g(w)的观察值g~(w,x)≐w−x\tilde{g}(w,x)\doteq w-xg~(w,x)≐w−x
又注意到:
g~(w,η)=w−x=w−x+E[X]−E[X]=(w−E[X])+(E[X]−x)≐g(w)+η,\begin{aligned}
\tilde{g}(w,\eta)=w-x & =w-x+\mathbb{E}[X]-\mathbb{E}[X] \\
& =(w-\mathbb{E}[X])+(\mathbb{E}[X]-x)\doteq g(w)+\eta,
\end{aligned}g~(w,η)=w−x=w−x+E[X]−E[X]=(w−E[X])+(E[X]−x)≐g(w)+η,
即w−xw-xw−x就是g(w)带噪声的观察值g~(w,η)\tilde{g}(w,\eta)g~(w,η)
(3)根据RM算法解决g(x)=0的递推公式
wk+1=wk−αkg~(wk,ηk)=wk−αk(wk−xk)w_{k+1}=w_k-\alpha_k\tilde{g}(w_k,\eta_k)=w_k-\alpha_k(w_k-x_k)wk+1=wk−αkg~(wk,ηk)=wk−αk(wk−xk)
这正是期望估计算法。
随机梯度下降算法(SGD)
算法介绍
SGD是一种特殊的RM算法,期望估计算法是一种特殊的SGD算法。
我们要求解下面的问题,在所有可能的 www 的取值中,找到一个 www ,使得目标函数 J(w)J(w)J(w) 达到最小值,而 J(w)J(w)J(w) 的值是函数 f(w,X)f(w,X)f(w,X) 关于随机变量 XXX 的期望:
minwJ(w)=E[f(w,X)]\min_w\quad J(w)=\mathbb{E}[f(w,X)]wminJ(w)=E[f(w,X)]
- www是待优化的参数,XXX是一个随机变量,上面的期望是关于XXX的期望
- www和XXX可以是标量,也可以是向量。函数f(⋅)f(⋅)f(⋅)是一个标量
- minw\min_{w}minw:表示对变量 www 进行求最小值的操作,即寻找使得目标函数值最小的 www 的取值。这里的 www 可以是标量(一个数值),也可以是向量(多个数值组成的数组)。
- J(w)J(w)J(w):是目标函数,它是关于变量 www 的函数 ,我们的目标就是通过调整 www 的值,让 J(w)J(w)J(w) 尽可能小。
- E[f(w,X)]\mathbb{E}[f(w,X)]E[f(w,X)]:其中 E[⋅]\mathbb{E}[\cdot]E[⋅] 表示期望运算。f(w,X)f(w,X)f(w,X) 是一个函数,XXX 可以是标量或向量,f(w,X)f(w,X)f(w,X) 的输出结果是一个标量。整个 E[f(w,X)]\mathbb{E}[f(w,X)]E[f(w,X)] 表示对函数 f(w,X)f(w,X)f(w,X) 关于随机变量 XXX 取期望,也就是在 XXX 所有可能取值的情况下,按照其概率分布对 f(w,X)f(w,X)f(w,X) 进行加权平均。
求解方式1:梯度下降(GD)
可以把求J(w)最小值的问题转化成J(w)导数=0的方程求解问题,则可以使用RM算法:
wk+1=wk−αk∇wE[f(wk,X)]=wk−αkE[∇wf(wk,X)]w_{k+1}=w_k-\alpha_k\nabla_w\mathbb{E}[f(w_k,X)]=w_k-\alpha_k\mathbb{E}[\nabla_wf(w_k,X)]wk+1=wk−αk∇wE[f(wk,X)]=wk−αkE[∇wf(wk,X)]
缺点:期望值很难获得
求解方式2:批量梯度下降(BGD)
E[∇wf(wk,X)]≈1n∑i=1n∇wf(wk,xi)wk+1=wk−αk1n∑i=1n∇wf(wk,xi)\mathbb{E}[\nabla_wf(w_k,X)]\approx\frac{1}{n}\sum_{i=1}^n\nabla_wf(w_k,x_i) \\
w_{k+1}=w_k-\alpha_k\frac{1}{n}\sum_{i=1}^n\nabla_wf(w_k,x_i)E[∇wf(wk,X)]≈n1i=1∑n∇wf(wk,xi)wk+1=wk−αkn1i=1∑n∇wf(wk,xi)
缺点:每个迭代中,对于每个wkw_kwk都需要很多样本
求解方式3:随机梯度下降(SGD)
wk+1=wk−αk∇wf(wk,xk)w_{k+1}=w_k-\alpha_k\nabla_wf(w_k,x_k)wk+1=wk−αk∇wf(wk,xk)
- 对比梯度下降算法,使用随机梯度∇wf(wk,xk)\nabla_wf(w_k,x_k)∇wf(wk,xk)替代了E[∇wf(wk,X)\mathbb{E}[\nabla_wf(w_k,X)E[∇wf(wk,X)
- 对比批量梯度下降算法,就是让n=1
例子和应用
考虑这样一个例子:
minwJ(w)=E[f(w,X)]=E[12∥w−X∥2]\min_w\quad J(w)=\mathbb{E}[f(w,X)]=\mathbb{E}\left[\frac{1}{2}\|w-X\|^2\right]wminJ(w)=E[f(w,X)]=E[21∥w−X∥2]
其中f(w,X)=∥w−X∥2/2∇wf(w,X)=w−Xf(w,X)=\|w-X\|^2/2\quad\nabla_wf(w,X)=w-Xf(w,X)=∥w−X∥2/2∇wf(w,X)=w−X
- 使用GD算法求解:
wk+1=wk−αk∇wJ(wk)=wk−αkE[∇wf(wk,X)]=wk−αkE[wk−X].\begin{aligned} w_{k+1} & =w_k-\alpha_k\nabla_wJ(w_k) \\ & =w_k-\alpha_k\mathbb{E}[\nabla_wf(w_k,X)] \\ & =w_k-\alpha_k\mathbb{E}[w_k-X]. \end{aligned}wk+1=wk−αk∇wJ(wk)=wk−αkE[∇wf(wk,X)]=wk−αkE[wk−X]. - 使用SGD算法求解:
wk+1=wk−αk∇wf(wk,xk)=wk−αk(wk−xk)w_{k+1}=w_k-\alpha_k\nabla_wf(w_k,x_k)=w_k-\alpha_k(w_k-x_k)wk+1=wk−αk∇wf(wk,xk)=wk−αk(wk−xk)- 可以看到,这和期望估计算法表达式一样
- 期望估计算法就是一种特殊的SGD算法
梯度下降算法收敛性分析
从GD到SGD:
wk+1=wk−αkE[∇wf(wk,X)]↓wk+1=wk−αk∇wf(wk,xk)w_{k+1}=w_{k}-\alpha_{k}\mathbb{E}[\nabla_{w}f(w_{k},X)] \\
\downarrow \\
w_{k+1}=w_k-\alpha_k\nabla_wf(w_k,x_k)wk+1=wk−αkE[∇wf(wk,X)]↓wk+1=wk−αk∇wf(wk,xk)
因为∇wf(wk,xk)≠E[∇wf(w,X)]\nabla_wf(w_k,x_k)\neq\mathbb{E}[\nabla_wf(w,X)]∇wf(wk,xk)=E[∇wf(w,X)],则∇wf(wk,xk)\nabla_wf(w_k,x_k)∇wf(wk,xk)可以被看成一个E[∇wf(w,X)]\mathbb{E}[\nabla_wf(w,X)]E[∇wf(w,X)]的带噪声的测量值:
∇wf(wk,xk)=E[∇wf(w,X)]+∇wf(wk,xk)−E[∇wf(w,X)]⏟η\nabla_wf(w_k,x_k)=\mathbb{E}[\nabla_wf(w,X)]+\underbrace{\nabla_wf(w_k,x_k)-\mathbb{E}[\nabla_wf(w,X)]}_\eta∇wf(wk,xk)=E[∇wf(w,X)]+η∇wf(wk,xk)−E[∇wf(w,X)]
那么使用SGD算法,能够保证随着k→∞k \to \inftyk→∞时,有wk→w∗w_k \to w^*wk→w∗吗?
答案,是。我们下面证明SGD是一种特殊的RM算法,而RM算法的收敛性已经证明,从而证明SGD会收敛向方程的解。
SGD的目标是最小化函数J(w)=E[f(w,X)]J(w)=\mathbb{E}[f(w,X)]J(w)=E[f(w,X)]
当函数取得最小值时,导数一定为0,因此这个问题可以转换成求解J(w)导数=0的根:
∇wJ(w)=E[∇wf(w,X)]=0\nabla_wJ(w)=\mathbb{E}[\nabla_wf(w,X)]=0∇wJ(w)=E[∇wf(w,X)]=0
令:
g(w)=∇wJ(w)=E[∇wf(w,X)].g(w)=\nabla_wJ(w)=\mathbb{E}[\nabla_wf(w,X)].g(w)=∇wJ(w)=E[∇wf(w,X)].
那么,SGD的目标就变成的找到g(w)=0的根。
我们可以通过采样测量得到∇wf(w,x)\nabla_wf(w,x)∇wf(w,x),即带噪声的g(w):
g~(w,η)=∇wf(w,x)=E[∇wf(w,X)]⏟g(w)+∇wf(w,x)−E[∇wf(w,X)]⏟η\begin{aligned}
\tilde{g}(w,\eta) & =\nabla_wf(w,x) \\
& =\underbrace{\mathbb{E}[\nabla_wf(w,X)]}_{g(w)}+\underbrace{\nabla_wf(w,x)-\mathbb{E}[\nabla_wf(w,X)]}_{\eta}
\end{aligned}g~(w,η)=∇wf(w,x)=g(w)E[∇wf(w,X)]+η∇wf(w,x)−E[∇wf(w,X)]
那么使用RM算法求解g(w)=0就是:
wk+1=wk−akg~(wk,ηk)=wk−ak∇wf(wk,xk)w_{k+1}=w_k-a_k\tilde{g}(w_k,\eta_k)=w_k-a_k\nabla_wf(w_k,x_k)wk+1=wk−akg~(wk,ηk)=wk−ak∇wf(wk,xk)
可以看到这就是SGD算法,因此SGD就是一种特殊的RM算法。那么SGD算法应该满足:
1)0<c1≤∇w2f(w,X)≤c2;2)∑k=1∞ak=∞and∑k=1∞ak2<∞;3){xk}k=1∞是iid;\begin{aligned}
& 1)0<c_{1}\leq\nabla_{w}^{2}f(w,X)\leq c_{2}; \\
& 2)\sum_{k=1}^{\infty}a_{k}=\infty\mathrm{and}\sum_{k=1}^{\infty}a_{k}^{2}<\infty; \\
& 3)\{x_k\}_{k=1}^{\infty}是iid;
\end{aligned}1)0<c1≤∇w2f(w,X)≤c2;2)k=1∑∞ak=∞andk=1∑∞ak2<∞;3){xk}k=1∞是iid;
就可以保证wkw_kwk收敛到∇wE[f(w,X)]=0\nabla_w\mathbb{E}[f(w,X)]=0∇wE[f(w,X)]=0的根
随机梯度下降收敛模式
随机梯度与批量梯度的相对误差
问题:由于随机梯度是随机的,因此其近似值并不精确,那么随机梯度下降(SGD)的收敛过程是缓慢的还是具有随机性的呢?
为了回答这个问题,我们考虑随机梯度和批量梯度之间的相对误差:
δk≐∣∇wf(wk,xk)−E[∇wf(wk,X)]∣∣E[∇wf(wk,X)]∣
\delta_k \doteq \frac{|\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w_k, X)]|}{|\mathbb{E}[\nabla_w f(w_k, X)]|}
δk≐∣E[∇wf(wk,X)]∣∣∇wf(wk,xk)−E[∇wf(wk,X)]∣
由于E[∇wf(w∗,X)]=0\mathbb{E}[\nabla_w f(w^*, X)] = 0E[∇wf(w∗,X)]=0,我们进一步得到:
δk=∣∇wf(wk,xk)−E[∇wf(wk,X)]∣∣E[∇wf(wk,X)]−E[∇wf(w∗,X)]∣=∣∇wf(wk,xk)−E[∇wf(wk,X)]∣∣E[∇w2f(w~k,X)(wk−w∗)]∣
\delta_k = \frac{|\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w_k, X)]|}{|\mathbb{E}[\nabla_w f(w_k, X)] - \mathbb{E}[\nabla_w f(w^*, X)]|} = \frac{|\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w_k, X)]|}{|\mathbb{E}[\nabla_w^2 f(\tilde{w}_k, X)(w_k - w^*)]|}
δk=∣E[∇wf(wk,X)]−E[∇wf(w∗,X)]∣∣∇wf(wk,xk)−E[∇wf(wk,X)]∣=∣E[∇w2f(w~k,X)(wk−w∗)]∣∣∇wf(wk,xk)−E[∇wf(wk,X)]∣
其中,最后一个等式是由中值定理得出的,并且w~k∈[wk,w∗]\tilde{w}_k \in [w_k, w^*]w~k∈[wk,w∗] 。
假设函数 fff 是严格凸函数:
∇w2f≥c>0\nabla_w^2 f \geq c > 0∇w2f≥c>0
在数学中,凸函数的二阶偏导数严格大于0。
这里用 ∇w2f\nabla_w^2 f∇w2f 表示关于 www 的二阶导数,也叫海森矩阵 ,当 www 是标量时就是二阶导数,当 www 是向量时是海森矩阵。
然后,δk\delta_kδk的分母变为:
∣E[∇w2f(w~k,X)(wk−w∗)]∣=∣E[∇w2f(w~k,X)](wk−w∗)∣=∣E[∇w2f(w~k,X)]∣∣(wk−w∗)∣≥c∣wk−w∗∣
\begin{align*}
|\mathbb{E}[\nabla_w^2 f(\tilde{w}_k, X)(w_k - w^*)]| &= |\mathbb{E}[\nabla_w^2 f(\tilde{w}_k, X)](w_k - w^*)| \\
&= |\mathbb{E}[\nabla_w^2 f(\tilde{w}_k, X)]||(w_k - w^*)| \geq c|w_k - w^*|
\end{align*}
∣E[∇w2f(w~k,X)(wk−w∗)]∣=∣E[∇w2f(w~k,X)](wk−w∗)∣=∣E[∇w2f(w~k,X)]∣∣(wk−w∗)∣≥c∣wk−w∗∣
将上述不等式代入δk\delta_kδk的表达式中,可得:
δk≤∣∇wf(wk,xk)−E[∇wf(wk,X)]∣c∣wk−w∗∣
\delta_k \leq \frac{|\nabla_w f(w_k, x_k) - \mathbb{E}[\nabla_w f(w_k, X)]|}{c|w_k - w^*|}
δk≤c∣wk−w∗∣∣∇wf(wk,xk)−E[∇wf(wk,X)]∣
上面的给出的不等式可以拆解为:
δk≤∣∇wf(wk,xk)⏞stochastic gradient−E[∇wf(wk,X)]⏞true gradient∣c∣wk−w∗∣⏟distance to the optimal solution\delta_k \leq \frac{|\overbrace{\nabla_w f(w_k, x_k)}^{\text{stochastic gradient}} - \overbrace{\mathbb{E}[\nabla_w f(w_k, X)]}^{\text{true gradient}}|}{\underbrace{c|w_k - w^*|}_{\text{distance to the optimal solution}}}δk≤distance to the optimal solutionc∣wk−w∗∣∣∇wf(wk,xk)stochastic gradient−E[∇wf(wk,X)]true gradient∣
- ∇wf(wk,xk)\nabla_w f(w_k, x_k)∇wf(wk,xk)是随机梯度(stochastic gradient),它是基于样本xkx_kxk计算得到的梯度;
- E[∇wf(wk,X)]\mathbb{E}[\nabla_w f(w_k, X)]E[∇wf(wk,X)]是真实梯度(true gradient),是对所有可能的样本XXX取期望后的梯度;
- c∣wk−w∗∣c|w_k - w^*|c∣wk−w∗∣表示当前参数wkw_kwk与最优解w∗w^*w∗之间的距离。δk\delta_kδk是相对误差。
对SGD收敛模式的分析
- 相对误差δk\delta_kδk与∣wk−w∗∣|w_k - w^*|∣wk−w∗∣成反比关系。
- 也就是说,当当前参数wkw_kwk离最优解w∗w^*w∗越远时,∣wk−w∗∣|w_k - w^*|∣wk−w∗∣的值越大
- 根据反比例关系,δk\delta_kδk的值就越小;反之,当wkw_kwk越接近w∗w^*w∗时,∣wk−w∗∣|w_k - w^*|∣wk−w∗∣的值越小,δk\delta_kδk的值就越大。
- 当∣wk−w∗∣|w_k - w^*|∣wk−w∗∣较大时,相对误差δk\delta_kδk较小
- 这意味着在远离最优解的区域,随机梯度(基于样本计算的梯度)与真实梯度(对所有样本取期望后的梯度)的差异较小,此时随机梯度下降(SGD)算法的表现类似于梯度下降(GD)算法
- 因为在这种情况下,基于样本的梯度能够较好地近似真实梯度,就如同梯度下降算法那样直接沿着梯度方向进行优化。
- 当wkw_kwk接近最优解w∗w^*w∗时,相对误差δk\delta_kδk可能会变得很大。
- 这是因为此时∣wk−w∗∣|w_k - w^*|∣wk−w∗∣的值很小,根据前面提到的反比例关系,δk\delta_kδk会增大。
- 由于相对误差增大,说明基于样本计算的随机梯度与真实梯度之间的差异变大,导致在最优解附近,随机梯度下降算法的收敛过程会表现出更多的随机性,即参数更新的方向和步长可能会有较大的波动,不像在远离最优解时那样稳定。
考虑一个示例
设定:X∈R2X \in \mathbb{R}^2X∈R2 表示平面上的一个随机位置。它的分布在以原点为中心、边长为(20) 的正方形区域内服从均匀分布。其真实均值为E[X]=0\mathbb{E}[X]=0E[X]=0。均值估计是基于100100100个独立同分布(i.i.d,即independent and identically - distributed )的样本{xi}i=1100\{x_i\}_{i = 1}^{100}{xi}i=1100 。
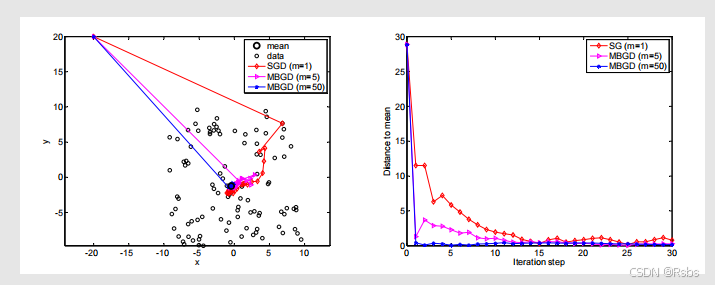
左边子图展示了数据点、均值以及不同方法的迭代路径
右边子图展示了不同方法在迭代过程中与均值的距离变化
- 尽管对均值的初始猜测值与真实值相差很远,但随机梯度下降(SGD )的估计值能够快速接近真实值附近。
- 当估计值接近真实值时,它会表现出一定的随机性,但仍会逐渐趋近于真实值。
随机梯度下降应用于确定性问题
我们上面介绍的随机梯度下降(SGD)的表达式涉及随机变量和期望。
人们常常会遇到一种不涉及任何随机变量的确定性的随机梯度下降表达式。
考虑如下优化问题:
minwJ(w)=1n∑i=1nf(w,xi)\min_{w} J(w)=\frac{1}{n}\sum_{i = 1}^{n}f(w,x_i)minwJ(w)=n1∑i=1nf(w,xi)
- f(w,xi)f(w,x_i)f(w,xi) 是一个带参数的函数。
- www 是待优化的参数。
- {xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n 是一组实数,其中 xix_ixi 不一定是任何随机变量的样本。
用于求解该问题的梯度下降算法为:
wk+1=wk−αk∇wJ(wk)=wk−αk1n∑i=1n∇wf(wk,xi)w_{k + 1}=w_{k}-\alpha_{k}\nabla_{w}J(w_{k})=w_{k}-\alpha_{k}\frac{1}{n}\sum_{i = 1}^{n}\nabla_{w}f(w_{k},x_{i})wk+1=wk−αk∇wJ(wk)=wk−αkn1∑i=1n∇wf(wk,xi)
假设这组数据量很大,且我们每次只能获取一个数值。在这种情况下,我们可以使用以下迭代算法:
wk+1=wk−αk∇wf(wk,xk)w_{k + 1}=w_{k}-\alpha_{k}\nabla_{w}f(w_{k},x_{k})wk+1=wk−αk∇wf(wk,xk)
问题:
- 这个算法是随机梯度下降(SGD)算法吗?它不涉及任何随机变量或期望值。
- 我们应该如何使用这组有限的数值{xi}i=1n\{x_{i}\}_{i = 1}^{n}{xi}i=1n 呢?我们是应该按照某种顺序对这些数值进行排序,然后逐个使用它们 ,还是应该从这组数值中随机抽取一个数值呢?
引入随机变量转化问题
为了回答前面提出的问题,我们可以手动引入一个随机变量,将确定性的表达式转化为随机梯度下降(SGD)的随机表达式。
具体来说,假设XXX是一个定义在集合{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n上的随机变量,并且假设它的概率分布是均匀分布,即p(X=xi)=1/np(X = x_i) = 1/np(X=xi)=1/n。
确定性问题转化为随机问题
通过引入上述随机变量,原本的确定性优化问题minwJ(w)=1n∑i=1nf(w,xi)\min_{w} J(w)=\frac{1}{n}\sum_{i = 1}^{n}f(w,x_i)minwJ(w)=n1∑i=1nf(w,xi)
就变成了一个随机优化问题minwJ(w)=1n∑i=1nf(w,xi)=E[f(w,X)]\min_{w} J(w)=\frac{1}{n}\sum_{i = 1}^{n}f(w,x_i)=\mathbb{E}[f(w,X)]minwJ(w)=n1∑i=1nf(w,xi)=E[f(w,X)] 。
这里的最后一个等式是严格成立的,并非近似,因此,这种算法就是随机梯度下降(SGD)算法。
算法收敛条件
如果xkx_kxk是从{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n中均匀且独立地采样得到的,那么估计值会收敛。由于是随机采样,xkx_kxk可能会多次取到{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n中的同一个数值。
总结来说,通过引入合适的随机变量和概率分布,能够将一个看似非随机的优化算法转化为随机梯度下降算法,并且明确了在特定采样条件下算法的收敛性。
BGD,MBGD,SGD
假设给定随机变量 XXX 的一组随机样本{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n,我们想要最小化J(w)=E[f(w,X)]J(w)=\mathbb{E}[f(w,X)]J(w)=E[f(w,X)] 。解决这个问题的批量梯度下降(BGD)、随机梯度下降(SGD)、小批量梯度下降(MBGD)算法分别如下:
wk+1=wk−αk1n∑i=1n∇wf(wk,xi)(BGD) w_{k + 1}=w_{k}-\alpha_{k}\frac{1}{n}\sum_{i = 1}^{n}\nabla_{w}f(w_{k},x_{i}) \quad \text{(BGD)} wk+1=wk−αkn1i=1∑n∇wf(wk,xi)(BGD)
wk+1=wk−αk1m∑j∈Ik∇wf(wk,xj)(MBGD) w_{k + 1}=w_{k}-\alpha_{k}\frac{1}{m}\sum_{j \in \mathcal{I}_{k}}\nabla_{w}f(w_{k},x_{j}) \quad \text{(MBGD)} wk+1=wk−αkm1j∈Ik∑∇wf(wk,xj)(MBGD)
wk+1=wk−αk∇wf(wk,xk)(SGD) w_{k + 1}=w_{k}-\alpha_{k}\nabla_{w}f(w_{k},x_{k}) \quad \text{(SGD)} wk+1=wk−αk∇wf(wk,xk)(SGD)
- 在批量梯度下降(BGD)算法中,每次迭代都使用所有的样本。当 nnn 很大时,(1/n)∑i=1n∇wf(wk,xi)(1 / n)\sum_{i = 1}^{n}\nabla_{w}f(w_{k},x_{i})(1/n)∑i=1n∇wf(wk,xi) 接近真实梯度E[∇wf(wk,X)]\mathbb{E}[\nabla_{w}f(w_{k},X)]E[∇wf(wk,X)]。
- 在小批量梯度下降(MBGD)算法中,Ik\mathcal{I}_{k}Ik 是{1,…,n}\{1, \ldots, n\}{1,…,n} 的一个子集,其大小为∣Ik∣=m|\mathcal{I}_{k}| = m∣Ik∣=m 。集合Ik\mathcal{I}_{k}Ik 是通过 mmm 次独立同分布采样得到的。
- 在随机梯度下降(SGD)算法中,xkx_{k}xk 是在时刻 kkk 从{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n 中随机采样得到的。
比较小批量梯度下降(MBGD)与批量梯度下降(BGD)和随机梯度下降(SGD):
- 与随机梯度下降(SGD)相比,小批量梯度下降(MBGD)的随机性更小,因为它使用更多的样本,而不像随机梯度下降那样每次只使用一个样本。
- 与批量梯度下降(BGD)相比,小批量梯度下降(MBGD)不需要在每次迭代中使用所有样本,这使得它更加灵活和高效。
- 如果 m=1m = 1m=1(mmm 是小批量样本的数量 ),小批量梯度下降(MBGD)就变成了随机梯度下降(SGD)。
- 严格来说,如果 m=nm = nm=n(nnn 是样本总数 ),小批量梯度下降(MBGD)并不会变成批量梯度下降(BGD)。因为小批量梯度下降使用的是随机选取的 nnn 个样本,而批量梯度下降使用的是全部 nnn 个样本。具体而言,小批量梯度下降可能会多次使用样本集合{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n中的某个值,而批量梯度下降对每个样本仅使用一次。
BGD、MBGD、SGD举例说明
给定一组数{xi}i=1n\{x_i\}_{i = 1}^{n}{xi}i=1n,我们的目标是计算均值xˉ=∑i=1nxi/n\bar{x}=\sum_{i = 1}^{n}x_i / nxˉ=∑i=1nxi/n。这个问题可以等价地表述为如下优化问题:
minwJ(w)=12n∑i=1n∥w−xi∥2
\min_{w} J(w)=\frac{1}{2n}\sum_{i = 1}^{n}\left \| w - x_i \right \|^2
wminJ(w)=2n1i=1∑n∥w−xi∥2
求解该问题的三种算法分别是:
批量梯度下降(BGD):wk+1=wk−αk1n∑i=1n(wk−xi)=wk−αk(wk−xˉ)
w_{k + 1}=w_{k}-\alpha_{k}\frac{1}{n}\sum_{i = 1}^{n}(w_{k}-x_{i})=w_{k}-\alpha_{k}(w_{k}-\bar{x})wk+1=wk−αkn1i=1∑n(wk−xi)=wk−αk(wk−xˉ)
小批量梯度下降(MBGD):wk+1=wk−αk1m∑j∈Ik(wk−xj)=wk−αk(wk−xˉk(m))
w_{k + 1}=w_{k}-\alpha_{k}\frac{1}{m}\sum_{j \in \mathcal{I}_{k}}(w_{k}-x_{j})=w_{k}-\alpha_{k}\left ( w_{k}-\bar{x}_{k}^{(m)} \right )wk+1=wk−αkm1j∈Ik∑(wk−xj)=wk−αk(wk−xˉk(m))
随机梯度下降(SGD):wk+1=wk−αk(wk−xk)
w_{k + 1}=w_{k}-\alpha_{k}(w_{k}-x_{k})wk+1=wk−αk(wk−xk)
其中xˉk(m)=∑j∈Ikxj/m\bar{x}_{k}^{(m)}=\sum_{j \in \mathcal{I}_{k}}x_{j}/mxˉk(m)=∑j∈Ikxj/m。
此外,如果αk=1/k\alpha_{k}=1/kαk=1/k,上述方程的解如下:
批量梯度下降(BGD):
wk+1=1k∑j=1kxˉ=xˉ
w_{k + 1}=\frac{1}{k}\sum_{j = 1}^{k}\bar{x}=\bar{x}
wk+1=k1j=1∑kxˉ=xˉ
小批量梯度下降(MBGD):
wk+1=1k∑j=1kxˉj(m)
w_{k + 1}=\frac{1}{k}\sum_{j = 1}^{k}\bar{x}_{j}^{(m)}
wk+1=k1j=1∑kxˉj(m)
随机梯度下降(SGD):
wk+1=1k∑j=1kxj
w_{k + 1}=\frac{1}{k}\sum_{j = 1}^{k}x_{j}
wk+1=k1j=1∑kxj
- 批量梯度下降(BGD)在每一步的估计值恰好就是最优解w∗=xˉw^{*}=\bar{x}w∗=xˉ。
- 小批量梯度下降(MBGD)的估计值比随机梯度下降(SGD)更快趋近于均值,因为xˉk(m)\bar{x}_{k}^{(m)}xˉk(m)已经是一个平均值。
令αk=1/k\alpha_{k}=1/kαk=1/k。给定100个数据点,使用不同的小批量大小会导致不同的收敛速度。
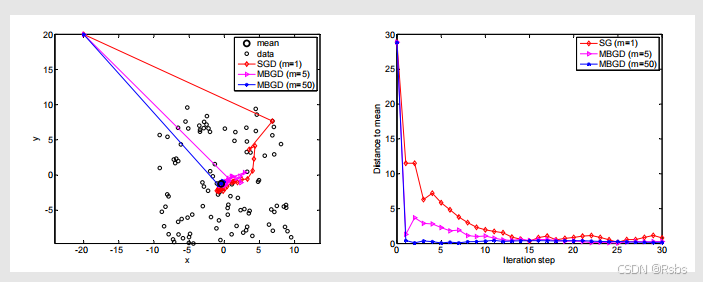
左侧展示了数据点、均值以及不同算法的迭代路径;
右侧展示了不同算法在迭代过程中与均值的距离变化情况,其中红线表示随机梯度下降(m=1m = 1m=1 ),粉线表示小批量梯度下降(m=5m = 5m=5 ),蓝线表示小批量梯度下降(m=50m = 50m=50 )。
总结
- 均值估计:使用({x_k}) 来计算(\mathbb{E}[X])((X) 的期望)
wk+1=wk−1k(wk−xk) w_{k + 1}=w_{k}-\frac{1}{k}(w_{k}-x_{k}) wk+1=wk−k1(wk−xk) - RM算法:使用({\tilde{g}(w_k, \eta_k)}) 来求解(g(w)=0)
wk+1=wk−akg~(wk,ηk) w_{k + 1}=w_{k}-a_k\tilde{g}(w_{k}, \eta_{k}) wk+1=wk−akg~(wk,ηk) - 随机梯度下降(SGD)算法:使用{∇wf(wk,xk)}\{\nabla_w f(w_k, x_k)\}{∇wf(wk,xk)} 来最小化J(w)=E[f(w,X)]J(w)=\mathbb{E}[f(w, X)]J(w)=E[f(w,X)]
wk+1=wk−αk∇wf(wk,xk) w_{k + 1}=w_{k}-\alpha_{k}\nabla_{w}f(w_{k}, x_{k}) wk+1=wk−αk∇wf(wk,xk)

















 1378
1378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









