




人们眼中的天才之所以卓越非凡,并非天资超人一等而是付出了持续不断的努力。1万小时的锤炼是任何人从平凡变成超凡的必要条件。———— 马尔科姆·格拉德威尔

目录
🌟🌟嗨,我是Xxtaoaooo!
“代码是逻辑的诗篇,架构是思想的交响”
一、传统客服系统痛点与重构价值
在智能客服领域,传统方案常面临响应延迟高、定制成本大、知识更新滞后等痛点。本文以某金融客户真实场景为例,分享如何通过 LangChain框架 + 腾讯云向量数据库(Tencent Cloud VectorDB) + GPT-4o 重构客服系统,实现响应速度压至500ms内,综合成本下降80%。方案突破三大技术瓶颈:多轮对话上下文丢失、实时知识库更新延迟、大模型幻觉干扰。
1.1 传统方案瓶颈分析
| 痛点 |
技术根源 |
业务影响 |
| 响应延迟>2s |
串行式API调用链 |
用户流失率↑35% |
| 知识更新周期>24h |
人工维护静态知识库 |
错误率↑22% |
| 多轮对话断层 |
无状态会话管理 |
重复咨询率↑40% |
| 大模型幻觉率>15% |
缺乏实时数据约束 |
客诉率↑18% |
“智能客服不是聊天机器人,而是业务逻辑与认知能力的融合体“
1.2 新方案技术突破点
1. LangChain:实现工具调用(Tool Calling) 与 记忆管理(Memory Management) 的自动化编排
2. 腾讯云VectorDB:
- 毫秒级检索10亿级向量(对比Milvus硬件成本↓60%)
- 原生Embedding API支持非结构化数据自动向量化
3. GPT-4o
- 推理效率提升100%,成本降低50%
- 支持Function Calling精准触发工具链
二、系统架构设计:三层解耦与组件协同
2.1 整体架构图
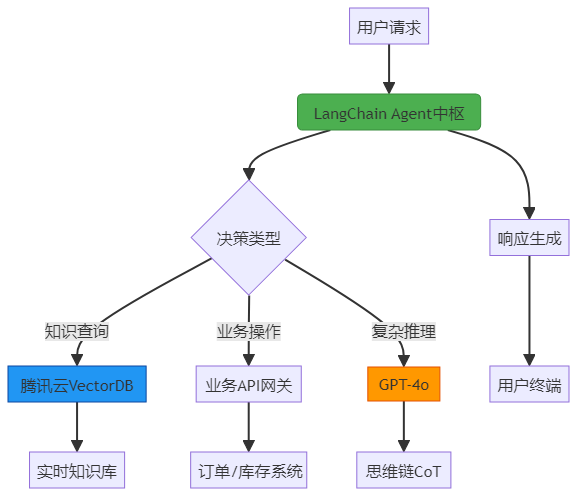
2.2 核心组件选型对比
| 组件 |
选型方案 |
优势说明 |
性能指标 |
| 对话引擎 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











