




 本文介绍了一种新的事件预测方法,通过构建叙事事件演化图(NEEG),结合缩放图神经网络(SGNN),有效处理大规模稠密有向图上的事件交互,提升事件预测准确性。
本文介绍了一种新的事件预测方法,通过构建叙事事件演化图(NEEG),结合缩放图神经网络(SGNN),有效处理大规模稠密有向图上的事件交互,提升事件预测准确性。
Script Event Prediction(脚本事件预测)
(1)定义
由Chambers和Jurafsky提出:
通过给定的事件上下文,从候选列表中选择最合理的后续事件
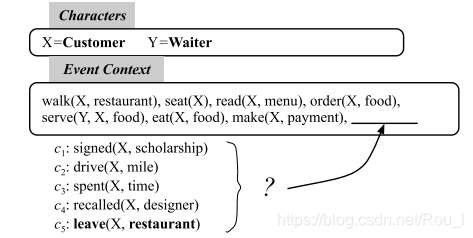
(2)已有工作
{ 基 于 事 件 对 基 于 事 件 链 \begin{cases} 基于事件对\\ 基于事件链\\ \end{cases} {基于事件对基于事件链
(3)本文工作
①事件演化表示

在事件对于事件链表中,显示E(talk)与C(serve)之间有着更强的联系,从而会选择错误答案E。使用图结构,使得事件B,C,D之间构成了强连接的组件,故在E与D之间会选择D
事件演化图(EEG) 用于存储事件演化原则和模式。其形式上是一个有向循环图,节点是事件,边代表事件之间的关系,如时间和因果关系。
本文提出叙事事件演化图(NEEG)。
②后续事件推导
{ C N N ( D u v e n a u d 2015 ) : 运 用 于 端 到 端 学 习 , 输 入 可 以 是 任 意 大 小 和 形 状 的 图 C N N − v a r i a n t ( K i p f a n d W e l l i n g 2017 ) : 选 择 了 一 阶 局 部 近 似 作 为 卷 积 结 构 , 对 图 边 的 数 量 进 行 线 性 扩 展 。 G N N ( G o r i 2005 ) : 解 决 图 问 题 最 为 有 效 的 方 法 , 问 题 : 学 习 需 要 收 敛 , 对 图 中 长 距 离 传 播 困 难 。 G N N + g a t e d r e c u r r e n t u n i t s ( L i 2016 ) : 改 进 G N N , 但 仅 适 用 于 小 图 。 S G N N ( 本 文 工 作 ) : 采 用 分 而 治 之 思 想 , 每 次 只 处 理 相 关 节 点 , 可 以 处 理 大 规 模 图 。 \begin{cases} CNN(Duvenaud \ 2015):运用于端到端学习,输入可以是任意大小和形状的图\\ CNN-variant(Kipf \ and \ Welling \ 2017):选择了一阶局部近似作为卷积结构,对图边的数量进行线性扩展。\\ GNN(Gori \ 2005):解决图问题最为有效的方法,问题:学习需要收敛,对图中长距离传播困难。\\ GNN+gated \ recurrent \ units(Li \ 2016):改进GNN,但仅适用于小图。\\ SGNN(本文工作):采用分而治之思想,每次只处理相关节点,可以处理大规模图。\\ \end{cases} ⎩⎪⎪⎪⎪⎪⎪⎨⎪⎪⎪⎪⎪⎪⎧CNN(Duvenaud 2015):运用于端到端学习,输入可以是任意大小和形状的图CNN−variant(Kipf and Welling 2017):选择了一阶局部近似作为卷积结构,对图边的数量进行线性扩展。GNN(Gori 2005):解决图问题最为有效的方法,问题:学习需要收敛,对图中长距离传播困难。GNN+gated recurrent units(Li 2016):改进GNN,但仅适用于小图。SGNN(本文工作):采用分而治之思想,每次只处理相关节点,可以处理大规模图。
创新点
①第一个提出事件图概念
②提出放缩神经网络,在大规模稠密有向图上有效
我们提出了一个缩放图神经网络,它可以在大规模稠密有向图上建模事件交互,并学习更好的事件表示来进行预测。
(4)模型
{
从
新
闻
专
线
语
料
库
中
抽
取
事
件
链
基
于
抽
取
的
事
件
链
构
建
N
E
E
G
\begin{cases} 从新闻专线语料库中抽取事件链\\ 基于抽取的事件链构建NEEG\\ \end{cases}
{从新闻专线语料库中抽取事件链基于抽取的事件链构建NEEG
语料库和事件链抽取方法同(Granroth-Wilding and Clark,2016)
叙述事件链
S
=
{
s
1
,
s
2
,
s
2
,
…
,
s
N
}
S=\{s_1,s_2,s_2,\dots,s_N\}
S={s1,s2,s2,…,sN},其中
s
i
=
{
T
,
e
1
,
e
2
,
e
3
,
…
,
e
m
}
s_i=\{T,e_1,e_2,e_3,\dots,e_m\}
si={T,e1,e2,e3,…,em}。为克服事件的稀疏性问题,使用事件
e
i
e_i
ei的抽象形式
(
v
i
,
r
i
)
(v_i,r_i)
(vi,ri)表示事件,
v
i
v_i
vi由非引理的谓词动词表示,
r
i
r_i
ri是
v
i
v_i
vi与链实体
T
T
T的句法依存关系
w
(
ν
j
∣
ν
i
)
=
c
o
u
n
t
(
ν
i
,
ν
j
)
Σ
k
c
o
u
n
t
(
ν
i
,
ν
j
)
w(\nu_j|\nu_i)=\frac{count(\nu_i,\nu_j)}{\Sigma_kcount(\nu_i,\nu_j)}
w(νj∣νi)=Σkcount(νi,νj)count(νi,νj)
c
o
u
n
t
(
ν
i
,
ν
j
)
count(\nu_i,\nu_j)
count(νi,νj)是二元模型出现在训练事件链中的频率
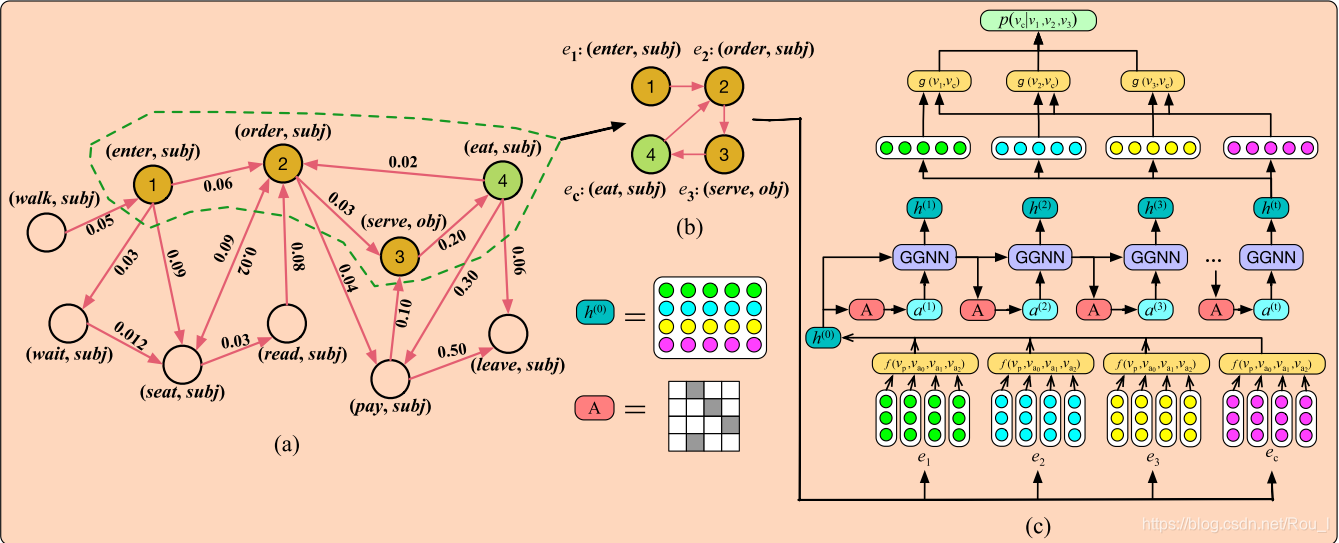
GGNN(gated graph neural network):
在GNN的基础之上加入时间和门控循环单元的反向传播
缺点:GGNN需要将整个图作为输入,因此它不能有效地处理具有数十万个节点的大规模图
→
\rightarrow
→分治
故,在每一个训练样本中,只有一个带有上下文和候选事件节点的子图。
(5)事件表示
使用预先训练好的动词以及元素的词嵌入表征事件,对于包含一个以上单词的元素,仅仅使用解析器识别的首字。词典外的单词以及缺失的元素使用零向量表示。
事件
e
i
=
{
p
(
a
0
,
a
i
,
a
2
)
}
e_i=\{p(a_0,a_i,a_2)\}
ei={p(a0,ai,a2)},动词和事件元素的词嵌入为
v
p
,
v
a
0
,
v
a
1
,
v
a
2
∈
R
d
v_p,v_{a_0},v_{a_1},v_{a_2}\in\R^d
vp,va0,va1,va2∈Rd,其中d表示词嵌入的维数
三种广泛使用的语义合成方法:
平均值:使用所有动词以及事件元素的平均值向量作为整个事件的表示
非线性变换:
v
e
=
t
a
n
h
(
W
p
⋅
v
p
+
W
0
⋅
v
a
0
+
W
1
⋅
v
a
1
+
W
2
⋅
v
a
2
+
b
)
v_e=tanh(W_p\cdot v_p+W_0\cdot v_{a_0}+W_1\cdot v_{a_1}+W_2\cdot v_{a_2}+b)
ve=tanh(Wp⋅vp+W0⋅va0+W1⋅va1+W2⋅va2+b)
其中W,b都是参数
连接:将所有的动词和事件元素连接起来一同表示一个事件
与GGNN相结合
h
(
0
)
=
{
v
e
1
,
v
e
2
,
…
,
v
e
n
,
v
e
c
1
,
v
e
c
2
…
,
v
e
c
k
}
h^{(0)}=\{v_{e_1},v_{e_2},\dots,v_{e_n},v_{e_{c_{1}}},v_{e_{c_{2}}}\dots,v_{e_{c_{k}}}\}
h(0)={ve1,ve2,…,ven,vec1,vec2…,veck}
A
∈
R
(
n
+
k
)
×
(
n
+
k
)
A\in\R^{(n+k)\times(n+k)}
A∈R(n+k)×(n+k)为子图的连接矩阵,其中
A
[
i
,
j
]
=
{
w
(
v
j
∣
v
i
)
,
当
v
i
→
v
j
∈
E
0
,
其
他
A[i,j]= \begin{cases} w(v_j|v_i),当v_i\rightarrow v_j\in E\\ 0,其他 \end{cases}
A[i,j]={w(vj∣vi),当vi→vj∈E0,其他
(6)选择后续事件得分函数
attention机制
u
i
j
=
t
a
n
h
(
W
h
h
i
(
t
)
+
W
c
h
c
j
(
t
)
+
b
u
)
u_{ij}=tanh(W_hh_i^{(t)}+W_ch_{c_j}^{(t)}+b_u)
uij=tanh(Whhi(t)+Wchcj(t)+bu)
α
i
j
=
e
x
p
(
u
i
j
)
Σ
k
e
x
p
(
u
k
j
)
\alpha_{ij}=\frac{exp(u_{ij})}{\Sigma_kexp(u_{kj})}
αij=Σkexp(ukj)exp(uij)
s
i
j
=
α
i
j
g
(
h
i
(
t
)
,
h
c
j
(
t
)
)
s_{ij}=\alpha_{ij}g(h_i^{(t)},h_{c_j}^{(t)})
sij=αijg(hi(t),hcj(t))
(7)模型目标函数
L
(
Θ
)
=
Σ
I
=
1
N
Σ
j
=
1
k
(
m
a
x
(
0
,
m
a
r
g
i
n
−
s
I
y
+
s
I
j
)
)
+
λ
2
∣
∣
Θ
∣
∣
2
L(\Theta)=\Sigma_{I=1}^N\Sigma_{j=1}^k(max(0,margin-s_{I_y}+s_{I_j}))+\frac{\lambda}{2}||\Theta||^2
L(Θ)=ΣI=1NΣj=1k(max(0,margin−sIy+sIj))+2λ∣∣Θ∣∣2
其中
s
I
j
s_{I_j}
sIj为第
I
I
I个事件与第
j
j
j个候选事件之间的相似性得分,
y
y
y是正确后续事件的索引
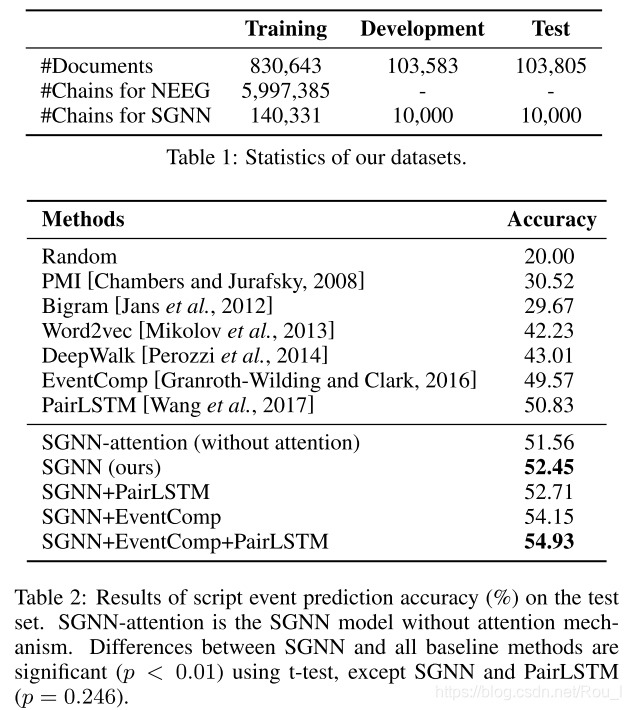
(8)实验

















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









