




 本文介绍了LaMa模型的backbone结构,包括快速傅里叶卷积及其组成部分,重点讨论了FFC中的局部与全局通道划分比例。复现代码支持高级训练技巧,并分享了预训练和自定义数据集的训练策略。
本文介绍了LaMa模型的backbone结构,包括快速傅里叶卷积及其组成部分,重点讨论了FFC中的局部与全局通道划分比例。复现代码支持高级训练技巧,并分享了预训练和自定义数据集的训练策略。
本次复现的论文是图像修复领域较火的Lama模型中的backbone,LaMa的backbone用在图像分类任务上也能有很好的效果。
原论文:https://arxiv.org/abs/2109.07161
源代码(用于图像修复的代码):https://github.com/saic-mdal/lama
复现的代码(用于图像分类代码):https://github.com/RooKichenn/General-lama-backbone(支持apex混合精度训练、mixup/cutmix、resume)
文章目录
一、LaMa整体结构
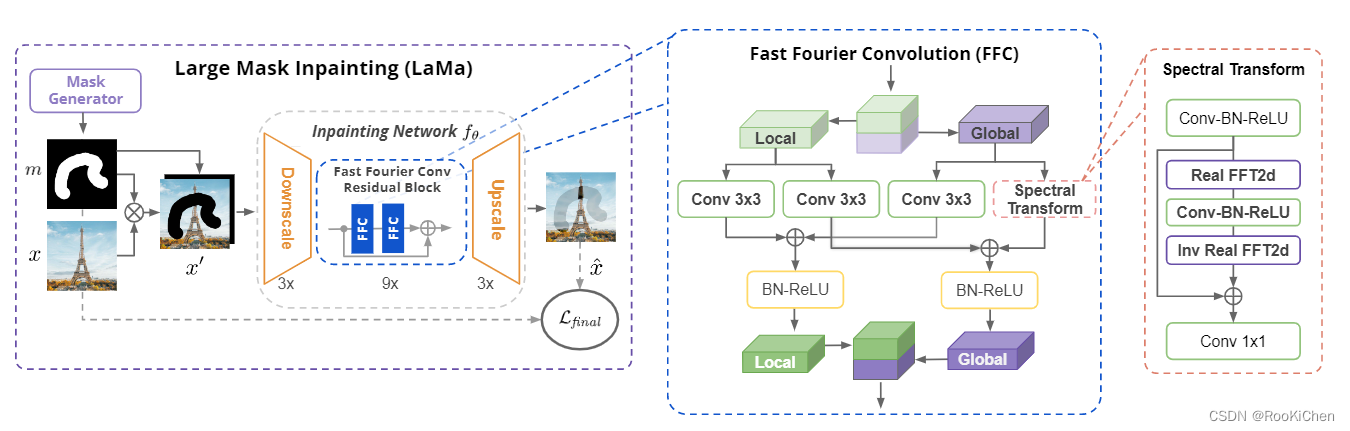
从图中可以看出,输入到网络的x'是由真实图像x和掩码m在通道方向上进行拼接构成的,公式为x'=stack(x⊙m, m),拼接完成后,x.shape(3, 224, 224) -->x'.shape(4, 224, 224),进行下采样,在第一层下采样时用了一个7x7的快速傅里叶卷积(FFC),LaMa的backbone整体使用的都是FFC进行卷积,第一层使用大卷积核是为了获得全局的感受野,后两层下采样也是使用的FFC,但是卷积核为3x3,经过下采样后,图像缩小了8倍,但是一般图像分类的模型都是下采样32倍,所以可以添加两个下采样模块,就是在原论文的基础上再下采样4倍,就变成了整体下采样32倍(我复现的是下采样8倍,32倍的还没试过)。下采样完成后,将特征图送入FFC ResNet Blocks,在FFC ResNet Blocks中特征图尺寸是不会变化的,主要目的就是为了让模型学习特征映射,后面的上采样我们不需要,我们只需有backbone,所以不做过多讲解,具体可以去阅读原论文。
二、 快速傅里叶卷积(FFC)
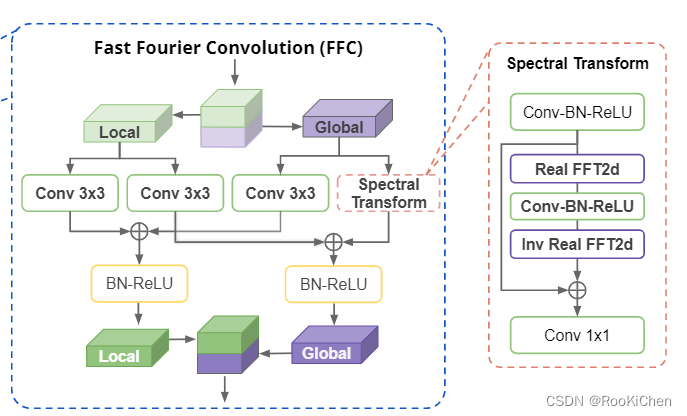
传统的卷积在网络的前几层并不能获得很大的感受野,这将浪费很多计算空间来对感受野进行建模,而且较小的感受野缺失全局的信息,于是作者使用了快速傅里叶卷积来获得全局的感受野。快速傅
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









