



 Imply CEO杨仿今在访谈中分享了大数据的发展历程,从数据仓库到数据湖的转变,以及AI时代数据分析向实时动态工作流程的发展。他还讨论了Druid作为实时数据分析工具的优势,强调了事件流在数字业务中的重要性,并分享了从开源项目到创业公司的经验与挑战。
Imply CEO杨仿今在访谈中分享了大数据的发展历程,从数据仓库到数据湖的转变,以及AI时代数据分析向实时动态工作流程的发展。他还讨论了Druid作为实时数据分析工具的优势,强调了事件流在数字业务中的重要性,并分享了从开源项目到创业公司的经验与挑战。
Robin.ly 是立足硅谷的视频内容平台,服务全球工程师和研究人员,通过与知名人工智能科学家、创业者、投资人和领导者的深度对话和现场交流活动,传播行业动态和商业技能,打造人才全方位竞争力。点击上方蓝字关注Robinly公众号。
本期Robin.ly创业专访特邀Imply的共同创始人、CEO杨仿今分享他从开源项目到数据分析公司的创业历程,以及对AI时代数据分析发展方向的见解。
Imply成立于2015年,专注于大规模事件流(event stream)的高性能数据分析。杨仿今同时也是Apache Druid的核心开发者,Druid是一个开源数据存储系统,旨在快速摄取大量的事件数据并提供低延迟查询。此前,杨仿今曾任Metamarkets(被Snapchat收购)和Cisco的工程主管,毕业于加拿大滑铁卢大学计算机工程专业。

杨仿今在硅谷接受Robin.ly专访
以下为精彩内容节选

长按二维码或点击“阅读原文”
访问Robin.ly观看完整英文访谈视频
1
大数据的发展历程及在AI时代的变化
Alex: 你见证了大数据领域许多关键的技术革命。能不能带我们回顾一下过去5到10年的一些重要事件?
杨仿今在硅谷接受Robin.ly访谈讲述大数据发展历程
Fangjin:
我认为数据分析的发展经历了这样一个过程:第一代技术是数据仓库。几十年前,甲骨文,Teradata,惠普和许多其他供应商的数据仓库曾经非常受欢迎。而在过去10年中,情况有了变化。人们开始意识到,数据正在变得越来越复杂,数据量一直在增加。结合另一个热门的开源项目Hadoop生态系统的兴起,以及公共云供应商的出现,数据分析技术已经发生了变化。现在出现了一个中央存储地点,不同类型的引擎可以对中央存储地点中的数据进行查询。这就是所谓的数据湖(Data Lake)架构,它是面向多数据源的信息存储系统,可以运行不同类型的分析,也是Amazon和Google运行数据分析服务的方式,也是人们在深层生态系统中的工作核心。
我认为数据分析现在正在朝着更加实时的动态工作流程转变。所以,现在许多企业都在对数字业务进行投资,将越来越多的业务放在互联网上运行。这意味着,相比先前的各种静态文件,你现在拥有了很多连续的信息流。我相信数据分析正在逐渐向摄取和分析连续信息流的方向发展。Imply就在朝着这个方向努力,我们正在尝试构建一种新型数据库。
这其中涉及到的一个重要的概念是事件流。事件流(Event Stream)是一个行业术语,用于描述数字业务的输出。我认为有三种主要的事件流,包括用户生成的数据——如果我是一个用户,正在使用某种移动产品或数字产品,那么我在这个产品上的种种行为就会生成非常有用的数据;事件流还可以包含应用程序的指标,比如KPI或者性能参数等等;它还可以是低级基础架构数据,如服务器指标和服务器日志,基本上就是人们与不同类型产品交互的输出。所以事件流描述的是一系列行为发生的过程。

杨仿今(右)与Robin.ly创始人Alex Ren(左)
Alex: 我们知道大概从三四年前开始,人工智能逐渐变成了非常热门的领域。那么数据分析如何应对人工智能和机器学习的兴起?能举几个例子吗?
Fangjin:
这的确是个很有意思的现象。人工智能和机器学习的概念已经存在了几十年,最近在投资界得到了越来越多的关注。我觉得我们更应该思考诸如公司到底能不能找到成功的AI解决方案的问题。但我也认为,人工智能和机器学习的确对整个数据生态系统来说意义重大。我把AI和ML分解成算法和计算两个部分来看。有大量的数据需要处理,系统必须执行原始计算以得出一些初步的分析,随后通过更智能的算法获得相应的决策和推荐等等。在Imply,我们建立了一个像计算层一样的基础结构,让更高级别的AI技术实现许多应用,比如大规模数值运算。
比如我们有一个客户是一家大型金融银行。他们将数据分析技术与自己开发的人工智能系统相结合,试图更好的识别出不同产品线中的相同客户,以了解这些客户可能感兴趣的其他产品。在这种情况下,他们正在使用我们的技术更快的获取数据,进行更低级别的计算和更快的大规模数值运算。接着,他们在低级别数据之上构建了自己的高级数据抽象和算法。
2
Druid的优势和特点
Alex: 我们知道还有许多其他的实时数据流工具,比如Flink,Storm和Kafka。相比之下,Druid的优势和特点是什么的?
Fangjin:
确实还有类似的工具。实际上,单一的数据架构很难解决一个特定案例所面临的所有问题。通常人们更倾向于构建数据堆栈(Data Stack),将不同的技术结合起来,其中每种技术都擅长解决特定的问题。
更现代的流分析堆栈包含三个主要部分。其中一个部分负责从某个地方获取数据并将其传输到其他地方,这就是所谓的信息总线。Apache Kafka非常擅长数据传输。
另一个关键部分是数据的清理、转换和处理。原始数据通常要通过多种方式进行转换之后才能使用。工业界将这一过程叫做提取转换加载,简称为ETL。 具有ETL功能的部分就是所谓的流处理器。Apache Flink,Apache Storm,Spark Streaming实际上就是用来对流媒体数据进行ETL操作的。
最后一部分就是,如何从数据中得出结论?如何长期存储这些数据?这些就是数据库和Druid的主要功能。Druid跟Kafka,Flink或Storm的关系并非竞争,而是互补。也就是说,堆栈可以输入到Kafka中,然后通过Flink进行转换,最后将转换后的数据传递给Druid进行进一步查询。这就是一个端到端的堆栈。
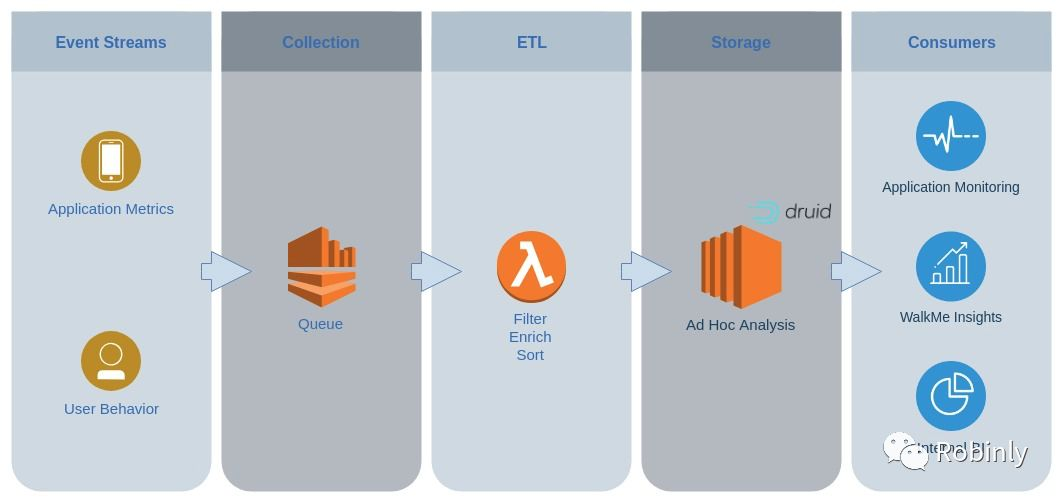 Imply和Druid应用示例:WalkMe (图片来源:https://imply.io/)
Imply和Druid应用示例:WalkMe (图片来源:https://imply.io/)
Alex: 你们有一个产品叫Imply Cloud,是AWS的托管服务。我知道AWS有很多限制,你们是如何应对这些限制的?
Fangjin:
Imply是打包软件,也就是说你可以在内部进行安装,可以在任何基于Linux的环境中安装。但我们的核心产品之一是Imply Cloud,是AWS的托管服务。所谓托管服务,是指帮助客户将我们的软件部署到他们的AWS账户中。因此,客户对他们的数据有全部的所有权,他们可以控制数据运行的硬件,我们的作用就是让相关操作和部署更容易。
所以在这种情况下,AWS的限制对我们来说并不是大问题,它的模型实际上运行得很好。这样做的好处之一就是,客户不再需要对软件进行复杂的管理,其中的很多步骤已经被自动化了。另外,我们也不会查看或者拥有他们的数据,这是另外一个优点。这种模式也是比如Databricks(Apache Spark的母公司),Qubole和其他公司所采用,而且效果非常好。
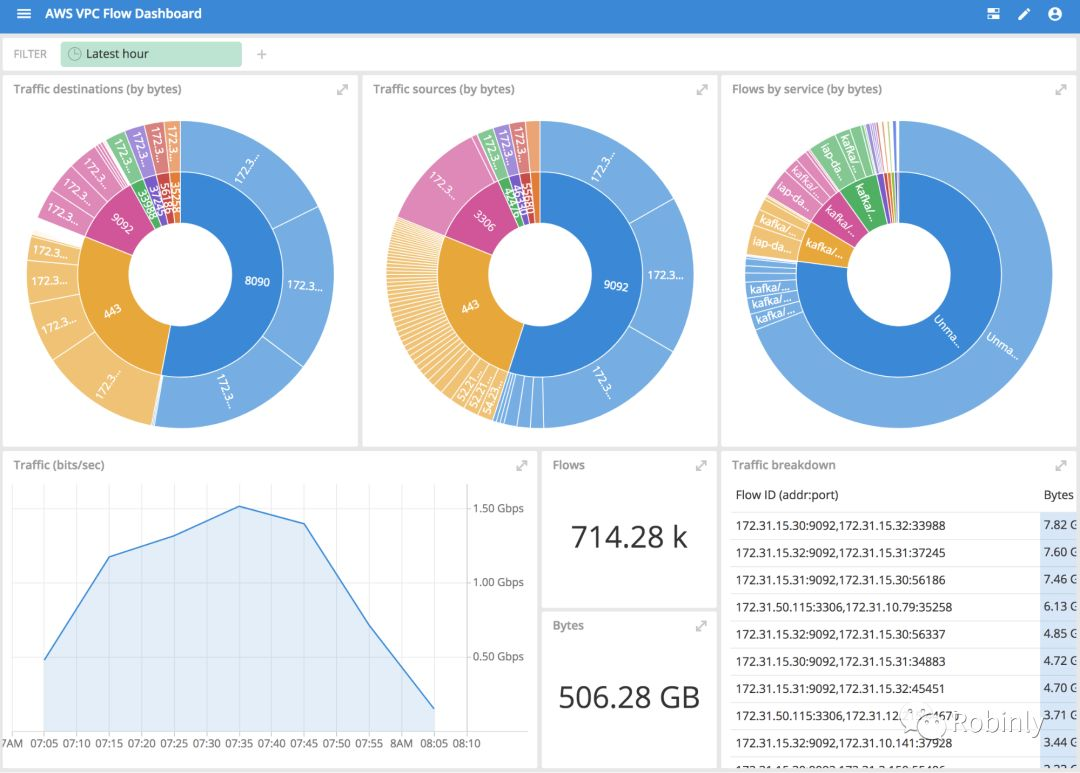
AWS数据可视化界面(图片来源:https://imply.io/)
3
基于开源项目创立公司
Alex: 你之前在Metamarkets工作了四年,在这期间是如何打造Druid的?后来为什么又决定创业?从工程师的角色转变为企业家,你经历了怎样的过渡?
Fangjin:
我在2009年搬到硅谷,加入了Cisco,负责一些研发工作。但我很快意识到大公司并不适合我,我一直怀揣着对初创公司的向往。后来我成为了最早加入Metamarkets的一批员工之一。我和当时的工程副总裁,也是我的面试官之一,一起构建了一些Druid的技术案例。后来我们决定开源这个技术,并逐渐发现这项技术可以解决很多大公司的问题,有着巨大的市场潜力,于是就产生了创办公司的念头。
Druid最新版本界面(图片来源:https://imply.io/)
我在上大学的时候就对创业公司和风险投资之类的概念很感兴趣,会有意识的去搜集这方面的信息。我认识到创办一家公司,我不仅要成为一名优秀的工程师,还要有出色的商业头脑,而同时具备这两个条件是很难的。所以我在早年的职业生涯中一直专注于如何成为一名优秀的工程师,努力打造一个能够让越来越多的公司受益的系统。在创立公司之后,我让自己尽快开始适应这种角色转换,了解什么叫市场推广策略,如何找到技术和产品的市场定位,以及如何进行销售。除此之外,我还会花一些时间社交,向前辈请教创业的经验和教训;同时也博览群书,钻研相关领域的知识。创业是一个生死攸关的过程,如果不知道如何生存,公司就只能关门。我觉得学习知识最好的方法就是实践,纸上谈兵肯定是不行的,只有亲自动手才能知道会遇到什么样的困难,以及如何克服。
Imply是一家B2B的公司。对于任何一家B2B的公司,盈利方式有很多种,但每种都不轻松。我刚开始创业时并没有意识到这一点,还天真的以为拥有非常强大的技术,人们就会买账,但事实并非如此。任何商业领域都存在竞争。有些竞争对手与我们的目标客户有几十年的交情,他们的团队也比我们要大得多。但是我们发现,想要在若干竞争者中脱颖而出,最重要的并不是技术本身,而是要突出我们的技术如何解决问题,能创造什么样的价值,并且有针对性的打造不同的市场推广战略。
4
如何应对挑战和错误
Alex: 在你三年的创业经历中,你遇到的最大的挑战,或者说错误是什么?
杨仿今在robin.ly专访谈创业过程中的挑战和错误
Fangjin:
挑战肯定是很多了,有些创业初期的问题在现在看来可能不是问题。在最开始的几年,吃闭门羹简直是家常便饭,比如有的投资者觉得我们的公司不会成功,不愿意投资;比如潜在客户看不到我们产品的价值,不愿意购买;还比如应聘者觉得我们的公司没有前途,拒绝加入我们。最开始,一次次被拒绝让我感到非常崩溃,但是我现在已经习惯了。面对拒绝,我会告诉自己,今天只是个星期二,继续努力就是了。
如果说犯了什么错误的话,我希望在刚开始的时候能够更加专注。专注对于创业公司非常重要,因为你在创业公司中很容易分心,有各种大大小小的事情要处理。现在看来,在资源有限的情况下,事无巨细亲力亲为只是浪费时间。对每一个初创公司来说,犯错都是不可避免的。但是要坚持你的信念和对市场的判断,多去尝试,犯了错误及时吸取教训就好。
Alex: 对于想要创业的人,你的建议是什么?
杨仿今在robin.ly专访谈创业建议
Fangjin:
我们总是会听到人们描述创业如何艰辛,但是直到你亲自去尝试才会体会到究竟有多难。我认为人们在开始创业之前,应该想清楚自己的动机。比如有人想创业是为了赚钱,想要实现财务自由,但通常情况下很难实现。公司在未来有可能赚得盆满钵满,但在最艰难的创业期间,你很可能会面对资金短缺的问题。如果你的动机是赚钱,又缺乏坚定的信念,在这种情况下你很可能就会支撑不住,半途而废。
还有一些人创业是为了自己当老板,但是你会发现其实你说了不算。你的任何决策要向董事会报告,反倒是人人都成了你的老板。除此之外,你还要想办法吸引和留住人才,打造出色的公司文化。所以我认为这样的动机也很难支撑你走下去。那些最伟大的初创公司一定是挺过了最艰难的时期,创始人拥有足够的耐心,有坚定的信念和排除万难,勇往直前的勇气。其实想要赚钱或者拥有更多自由,还是有很多其他的途径可以尝试的,不一定非要承担创业的压力。(完)
相关阅读
Otter.ai创始人Sam Liang:智能记录你的生活对话

你“在看”吗?

















 1192
1192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









