






 本文深入探讨了正则表达式的基本概念与语法,详细解析了如何使用Python的正则表达式进行字符串的搜索、替换与分割。同时,通过实例演示了如何去除文本中的特殊字符,保留单词间的空格。
本文深入探讨了正则表达式的基本概念与语法,详细解析了如何使用Python的正则表达式进行字符串的搜索、替换与分割。同时,通过实例演示了如何去除文本中的特殊字符,保留单词间的空格。
0. 问题
1.问:如何去除英文文本中的字符、空格、数字等与文本无关的字?
如下面的字符串text,该如何处理?
text = ' Today II[} I ??( 123 $%%L) _+O+V+20!!2[E...4Y23OU ]UU#@U '
解决:
re.sub(r'[\W0-9_]', '', text)

2.如何去在上面要求的基础上,还保留单词之间的空格?
借此梳理总结一下python的正则表达式操作
1.概览
-
什么是正则表达式?
——规则表达式正则表达式 = Regular Expression = regex = regexp = RE
正则表达式使用单个字符串来描述、匹配一系列符合某个句法规则的字符串。
正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式。 就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
-
正则表达式用来做什么?
——模糊匹配(过滤字符串)在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。
许多程序设计语言都支持利用正则表达式进行字符串操作。 -
正则表达式怎么用?
——操纵字符串+特殊符号
2.正则表达式语法
正则表达式包括字符串(包括普通字符)和特殊字符。
-
字符串
绝大部分普通字符,比如 ‘A’, ‘a’, 或者 ‘0’,都是最简单的正则表达式。它们就匹配自身。
-
特殊字符
有些字符,比如 ‘|’ 或者 ‘(’,属于特殊字符。 特殊字符既可以表示它的普通含义, 也可以影响它旁边的正则表达式的解释。
特殊字符如下:
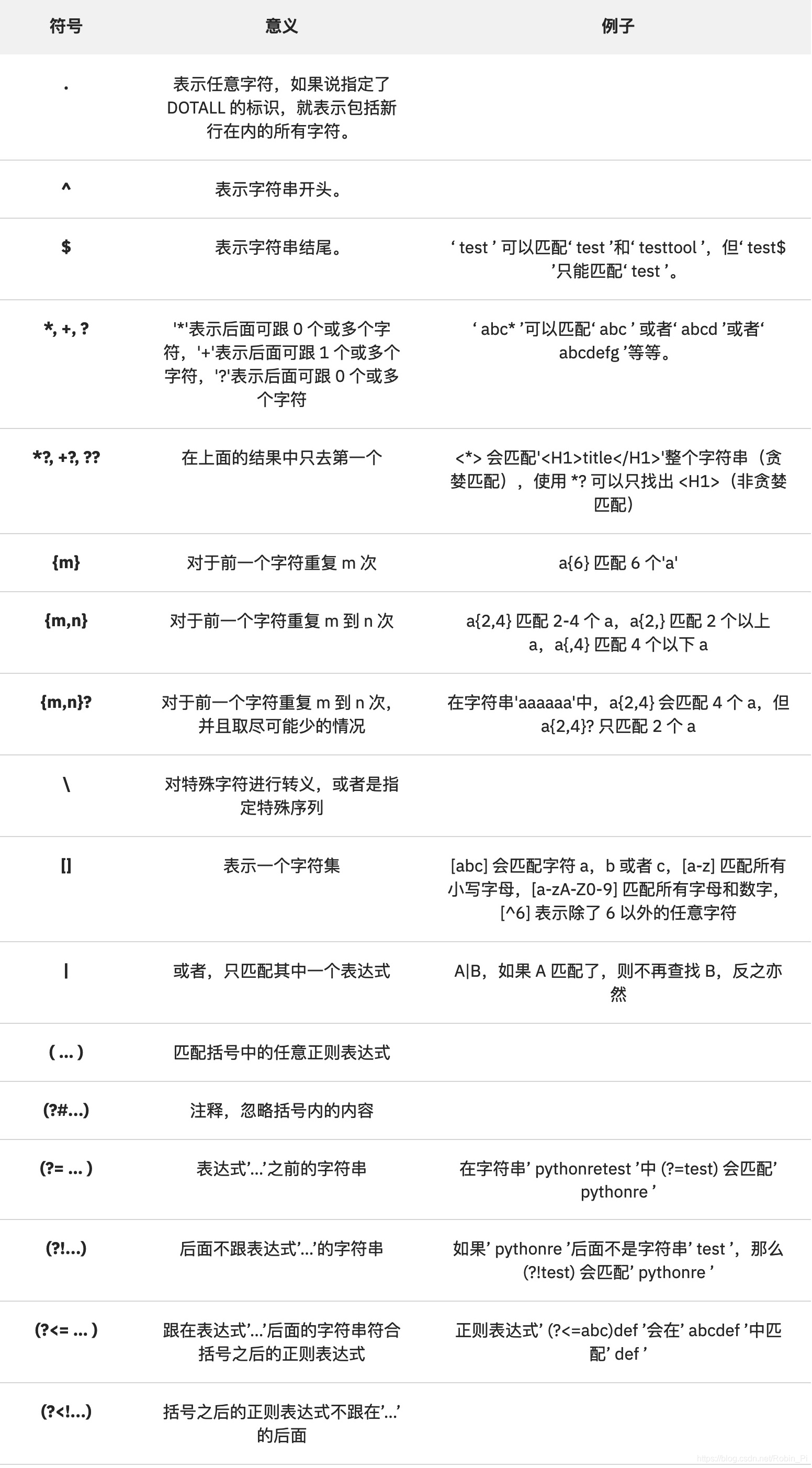 几个值得注意的点:
几个值得注意的点:
① [ ] 表示一个字符集!
比如,想要表示0-9的数字就不需要像0-9这样表达,而是[0-9],类似的还有[A-Z].
print(re.search(r'b[a-z]d', 'I want to be a bird.') ) # 类似 bid 、ba之类的单词(没有找到)
print(re.search(r'b[a-z][a-z]d', 'I want to be a bird.') ) # 类似 bid 、ba之类的单词(找到:bird)
② 原始字符串( r’raw’ ):
用r当前缀,引号括起来的字符串,在它们之中的反斜杠不必做任何特殊处理
反斜杠(’ \ ')
反斜杠表示特殊形式,或者把特殊字符转义成普通字符。
包含’ \ ’的特殊序列的意义:
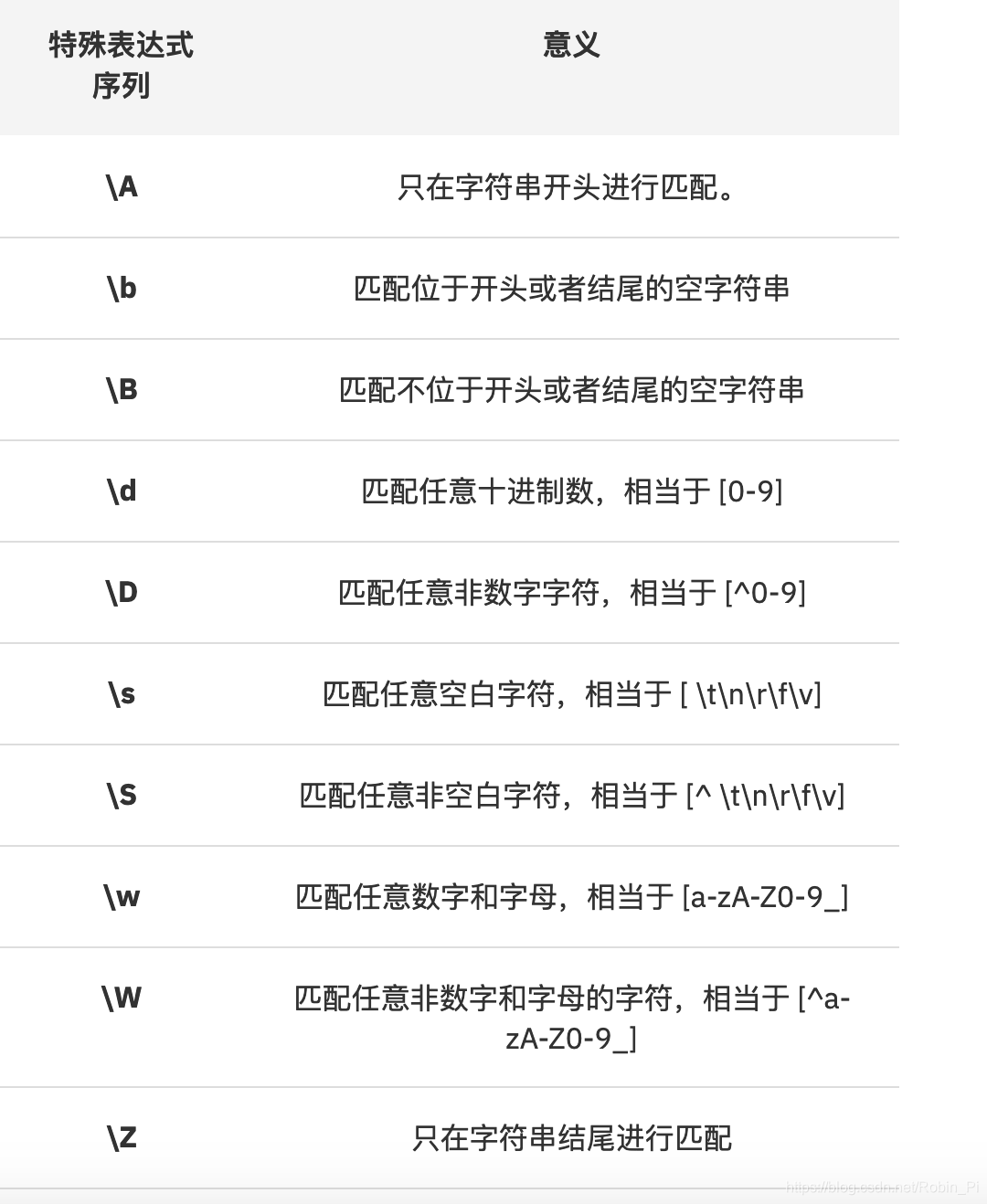 几个常用的:
几个常用的:
-
\s
对于 Unicode (str) 样式:
匹配任何Unicode空白字符(包括 [ \t\n\r\f\v] ,还有很多其他字符。
注:\t:Tab、\n :Next -
\S
匹配任何非空白字符。就是 \s 取非。如果设置了 ASCII 标志,就相当于 [^ \t\n\r\f\v]
-
\w
对于 Unicode (str) 样式:
匹配Unicode词语的字符,包含了可以构成词语的绝大部分字符,也包括数字和下划线。如果设置了 ASCII 标志,就只匹配 [a-zA-Z0-9_] -
\W
匹配任何不是单词字符的字符。 这与 \w 正相反。 如果使用了 ASCII 旗标,这就等价于 [^a-zA-Z0-9_]。
-
\d
匹配任意十进制数,相当于[a-zA-Z0-9]
(通配符:匹配数字) -
\D
匹配任意非十进制数,相当于[^a-zA-Z0-9]
(通配符:匹配字母)
跳出技术细节,回过头我们想一想正则表达式到底是在做什么事情。其实,我们完全可以把对一个字符串的操作当做一个完整的数据处理流程,只不过全部的数据就是简单的字符串而已,而正则正则表达式做的事情,就是对数据的一种过滤和筛选——从原始字符串中选出我们需求的那部分数据的表达集合。
3.字符串的方法
3.1 分割字符串
- split()
将字符串拆分为一个列表,在正则匹配的任何地方将其拆分
这里指的是模块方法re.split(),功能比字符串方法split()更为强大一些
3.2 搜索和替换
- sub()
找到正则匹配的所有子字符串,并用不同的字符串替换它们 - subn()
与 sub() 相同,但返回新字符串和替换次数
注意:在转向 re 模块之前,请考虑是否可以使用更快更简单的字符串方法解决问题。比如,replace()
3.2 应用匹配
match() 和 search()

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









