




本笔记为学习廖雪峰大佬https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000过程中一点自己记录的笔记
Python基础
Python是一个强缩进语言。当以冒号结尾的时候,缩进内容被视为一个代码块。
缩进应为四个空格,养成良好代码习惯。
Python是大小写敏感的语言。
数据类型和变量
·整数
回忆知识:C++中同样的表达方式。0x开头为十六进制、0开头为八进制。
·字符串
Python将字符串内容用" "或' '中表示,不包括引号本身。当表示的字符串中有引号时,为不产生歧义,可以运用转义字符。
例:'I\'m \"OK\"!' 输出结果为 'I'm "OK"!'
转义字符能够把要变成字符串的引号不识别成包含字符串的引号。
回忆知识:转义字符中\n 表示换行,\r表示回车,\\表示\。另有其他的表示方法。
例:
输入代码 print('I\'m learnin\'')
输出结果
输入代码 print('\\\n\\')
输出结果
\
\
为了方便,r' '表示' '内的不转义。
在命令行输入的时候,''' '''可以表示多行内容,...开头时可以接着上一行输入。在py文档中,...不显示。
·布尔值
注意大小写。False和True。
关系运算符表示法:and,or,not。和,或,非。
·空值
空值符号为None。其具有特殊意义,不能等于0.。
·变量
敲黑板啦!!!
C++中,变量的类型是被指定的。这叫做静态语言。
而Python的变量没有限制数据类型,是动态语言。
·常量
python对除法有两种方法:/ 和 // 。前者是真实的运算结果,后者是运算结果求整数。
Python的整数没有大小限制。浮点数也没有,但是超过一定范围会变成inf(无限大)。
字符串和编码
ASCII编码(美国用)是1个字节,而Unicode编码(全球通用)通常是2个字节。
Python的字符串是用Unicode编码的,类型是str。
·字符串
ord()函数能够获取字符的整数表示,chr()函数把编码转换为对应字符。
用bytes表示数据,格式为 b'内容'。
字符串通过encode()函数能够被转换成指定的bytes。decode()则反之,但遇到无法解码的字节会报错,输入error=‘ignore可以忽略错误字节’。
操作格式:
要转换的字符串.encode(' 要转换的bytes类型 ')
要转换的bytes.decode('bytes的类型')
len()可以计算str的字符数,bytes的字节数。
在编辑时要在开头加入代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
来告诉系统和Python是用UTF-8编码的。并且编辑器也要采取UTF-8 without BOM编码
· 格式化(重点)!
百分号
此处借鉴https://www.cnblogs.com/pycode/p/geshihua.html博主的整理。用于字符串内的替换。
格式:%[(name)][flags][width].[precision]typecode,随后在字符串后面打上括号(里面要替换的内容)。
flags 可选,可供选择的值有:
+ 右对齐;正数前加正号,负数前加负号;
- 左对齐;正数前无符号,负数前加负号;
空格 右对齐;正数前加空格,负数前加负号;
0 右对齐;正数前无符号,负数前加负号;用0填充空白处
width 可选,占有宽度。
precision 可选,小数点后保留的位数。
一些常见的typecode:
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
%%表示一个普通的%字符串。
·format()
会用传入的参数替换{0},{1}。
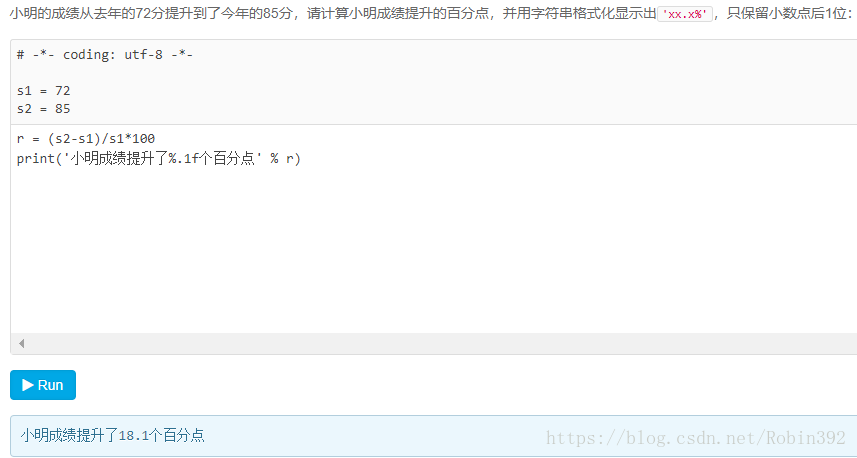
廖雪峰所留例题:
使用list和tuple
·list
list即是数组。通过[ ]括起来。同样是从0开始计数的。
list里面的元素的数据类型可以不同。list可以是其他list的元素,类似C++中N维数组的概念。要调用的时候,就数组[n][m]。
len()函数可以得出数组的元素个数。
数组[-1]表示最后一个元素。同理,-2、-3表示倒数第二个,倒数第三个。
数组还可以加入内容、删除内容。操作方法:
①数组.append(内容) 该方法直接加入到末尾。
②数组.insert(元素序号,内容) 该方法直接加入到指定位置。
③数组.pop() 该方法直接删除数组末尾元素。
④数组.pop(元素序号) 该方法直接删除数组指定元素。
·tuple
tuple与list类似。通过()括起来。但是tuple不能被修改。
只有一个元素的时候,为了避免歧义,tuple的表示要在末尾加一个逗号。如 (1,)
tuple中若含有list的元素,list是可以改变的。但是普通变量不可以。
·函数
可以把函数赋名给一个变量,这样可以通过这个变量名直接调用这个函数。相当于引用。
定义函数的格式:
def 函数名(变量):
函数体
函数遇到return便会结束。没有return则会返回一个none值。可以用return返回多个值,但本质上他是一个tuple,只是返回一个tuple的语法可以省略括号。
·如果要导入其他文件的函数,在当前目录下输入代码:from (文件名) import (函数名)
impor则是导入其他的包。
另外pass语句可以构成一个空函数。
isinstance(变量,(需要检查的类型)) 函数可以进行对变量的参数检查。
关于参数:
默认参数的设置从右往左。当需要赋值的时候,其实也可以赋值后面的默认参数。方法为:
xiaozhu(5,4,age=7) 意思是age不用默认参数了,但是其他默认参数还是老样子。
默认参数必须指向不变的量。
可变参数:
在参数前加一个*,相当于创建了一个list或者是tuple。所以可以传入任意个变量。
同时如果要往函数里面传入一个list里面的多个变量,同样可以在调用的是时候在变量前面加上一个*,这样他就会自动把list里面的元素一个个传进去。
关键字参数:
格式:在参数前面加上**
作用:传入的多个参数创建一个dict。拓展函数的功能。同理,**dict也可以把dict的元素一个个输进去。得到的dict是一份拷贝。含参数名的参数。
命名关键字参数:
命名关键字参数需要一个特殊分隔符*,*后面的参数被视为命名关键字参数。
这么做可以限制后面的关键字参数只能够接受特定的名字。但还是需要传入参数名,也有默认参数。
如果函数定义中已经有了一个可变参数,后面跟着的命名关键字参数就不再需要一个特殊分隔符*。
参数组合:
参数定义的顺序必须是:必选参数、默认参数、可变参数、命名关键字参数和关键字参数。
递归
递归因为函数是在栈上面调用的,所以调用过多会导致栈溢出。
解决方法:尾递归(在解释器做优化的情况下,python还不行)
在函数返回的时候,调用自身本身,并且,return语句不能包含表达式。这样,编译器或者解释器就可以把尾递归做优化,使递归本身无论调用多少次,都只占用一个栈帧,不会出现栈溢出的情况。
高级特性
1. 切片:取指定索引范围
即:[开始索引:结束索引:步长值]
开始索引:同其它语言一样,从0开始。序列从左向右方向中,第一个值的索引为0,最后一个为-1。如果只有开始索引一个负数,则会取到最后一个元素。
结束索引:切片操作符将取到该索引为止,不包含该索引的值。
步长值:默认是一个接着一个切取,如果为2,则表示进行隔一取一操作。步长值为正时表示从左向右取,如果为负,则表示从右向左取。步长值不能为0。
如果第一个索引是0,还可以省略。
甚至什么都不写,只写[:]就可以原样复制一个list。
tuple也是一种list,唯一区别是tuple不可变。因此,tuple也可以用切片操作,只是操作的结果仍是tuple。
字符串'xxx'也可以看成是一种list,每个元素就是一个字符。因此,字符串也可以用切片操作,只是操作结果仍是字符串。
2.迭代
python只要可迭代对象都可以使用for循环。
默认情况下,dict迭代的是key。如果要迭代value,可以用for value in d.values(),如果要同时迭代key和value,可以用for k, v in d.items()。
检查是否是可迭代对象,参考collections模块的Iterable判断。
3.列表生成式
>>> [(x,y,z) for x in range(1,30) for y in range(x,30) for z in range(y,30) if x**2 + y**2 == z**2] [(3, 4, 5), (5, 12, 13), (6, 8, 10), (7, 24, 25), (8, 15, 17), (9, 12, 15), (10, 24, 26), (12, 16, 20), (15, 20, 25), (20, 21, 29)] >>>
可以做到两层循环
for循环后面还可以加上if判断,这样我们就可以筛选出仅偶数的平方:
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]列表生成式也可以使用两个变量来生成list:key和value
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> [k + '=' + v for k, v in d.items()]
['y=B', 'x=A', 'z=C']函数也可以作为前面的表达式。
4.生成器
如果列表元素可以按照某种算法推算出来,我们可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。在Python中,这种一边循环一边计算的机制,称为生成器:generator。它的特殊之处在于,它保存的不是特定元素,而是一种算法。
要创建一个generator,有很多种方法。第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator。
要调用generator的值,就可以调用next()函数,每次调用都会计算出g的下一个元素的值。或者是通过for迭代将其元素给打印出来。
a,b=b,a+b 语句的意思 是 a=b, b=a+b
如果一个函数定义中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。
函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。
5.迭代器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









