




 本文详细介绍了 Redis 的基础知识,包括它的数据类型、安装步骤、缓存策略、一致性哈希算法、持久化策略、内存管理、主从复制、哨兵系统以及集群搭建。内容涵盖 Redis 的核心概念和实现高可用性的重要机制。
本文详细介绍了 Redis 的基础知识,包括它的数据类型、安装步骤、缓存策略、一致性哈希算法、持久化策略、内存管理、主从复制、哨兵系统以及集群搭建。内容涵盖 Redis 的核心概念和实现高可用性的重要机制。
1.redis介绍
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
2.redis安装
- redis官方下载redis-x.x.x.tar.gz
- make 编译
- make install 安装redis
- gcc 安装环境
启动命令 redis-server redis.conf
关闭命令 kill -9 pid or redis-cli -p 6379 shutdown
3.redis基础
1.redis有6中数据类型,分别为String,Hash,List,Set,ZSet,hyperloglog(新)
2.缓存三大问题
2.1) 缓存穿透:访问一个不存在的数据.因为缓存中不存在这个key,最终访问后台数据库.
2.2) 缓存击穿:当缓存key失效/过期/未命中时,高并发访问该key,所有的请求都会访问后台数据库.
2.3) 缓存雪崩:高并发访问,缓存命中较低或者失效时,比如:在同一时间内缓存大量失效.
3.redis分片
一般redis内存大小设定是为512M-1024M,如果用户需要缓存的数据有3G,则可以通过redis分片技术实现内存扩容
服务器部署三台redis
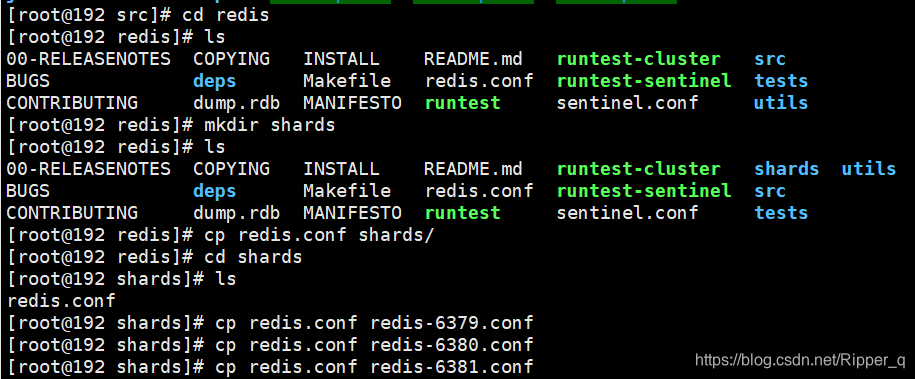
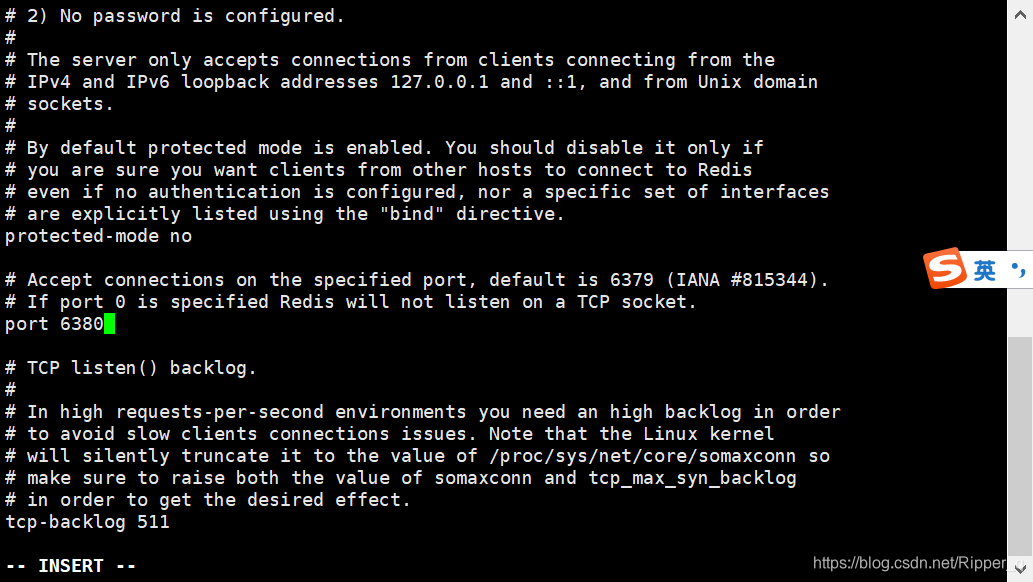
springboot集成redis以及分片技术
jar依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.8.2</version>
</dependency>
</dependencies>
配置文件
server:
port: 8082
redis:
# Redis数据库索引(默认为0)
database: 0
# Redis服务器地址
#host: 52.80.238.130
host: 192.168.80.128
# Redis服务器连接端口
port: 6379
jedis:
pool:
# 最大空闲连接
max-idle: 8
# 最小空闲链接
min-idle: 0
# 最大连接数(负数表示没有限制)
max-active: 8
# 最大阻塞等待时间(负数表示没有限制)
max-wait: 0
# 链接超时时间(毫秒)
timeout: 200
password:
RedisConfig
package redis.config;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
@Configuration
public class RedisConfig {
@Value("${redis.jedis.pool.max-idle}")
private int maxIdle;
@Value("${redis.jedis.pool.max-active}")
private int maxActive;
@Value("${redis.jedis.pool.min-idle}")
private int minIdle;
@Value("${redis.jedis.pool.max-wait}")
private int maxWaitMillis;
@Value("${redis.host}")
private String host;
@Value("${redis.timeout}")
private int timeout;
@Value("${redis.port}")
private int port;
@Bean
public JedisPool redisPoolFactory(){
JedisPoolConfig jedisPoolConfig = new JedisPoolConfig();
jedisPoolConfig.setMaxIdle(maxIdle);
jedisPoolConfig.setMaxWaitMillis(maxWaitMillis);
jedisPoolConfig.setMaxTotal(maxActive);
jedisPoolConfig.setMinIdle(minIdle);
//定义redis分片,可在服务器配置3台redis
//List<JedisShardInfo> shards = new ArrayList<>();
//shards.add(new JedisShardInfo("192.168.123.212", 6379));
//shards.add(new JedisShardInfo("192.168.123.212", 6380));
//shards.add(new JedisShardInfo("192.168.123.212", 6381));
//ShardedJedisPool shardedJedis = new ShardedJedisPool(jedisPoolConfig, shards);
JedisPool jedisPool = new JedisPool(jedisPoolConfig,host,port,timeout,null);
return jedisPool;
}
}
4.Hash一致性算法
4.1) 介绍:一致性哈希算法在1997年由麻省理工学院提出(参见扩展阅读[1]),设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
主要解决了数据一致性问题
按照常用的hash算法来将对应的key哈希到一个具有232次方个桶的空间中,即0~(232)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
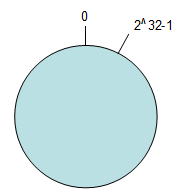
4.2) 均衡性:将关键字的哈希地址均匀地分布在地址空间中,使地址空间得到充分利用,这是设计哈希的一个基本特性。
4.3) 单调性:单调性是指当地址空间增大时,通过哈希函数所得到的关键字的哈希地址也能映射的新的地址空间,而不是仅限于原先的地址空间。或等地址空间减少时,也是只能映射到有效的地址空间中。简单的哈希函数往往不能满足此性质。
4.4) 分散性:哈希经常用在分布式环境中,终端用户通过哈希函数将自己的内容存到不同的缓冲区。此时,终端有可能看不到所有的缓冲,而是只能看到其中的一部分。当终端希望通过哈希过程将内容映射到缓冲上时,由于不同终端所见的缓冲范围有可能不同,从而导致哈希的结果不一致,最终的结果是相同的内容被不同的终端映射到不同的缓冲区中。这种情况显然是应该避免的,因为它导致相同内容被存储到不同缓冲中去,降低了系统存储的效率。分散性的定义就是上述情况发生的严重程度。好的哈希算法应能够尽量避免不一致的情况发生,也就是尽量降低分散性。
4.5) 负载:负载问题实际上是从另一个角度看待分散性问题。既然不同的终端可能将相同的内容映射到不同的缓冲区中,那么对于一个特定的缓冲区而言,也可能被不同的用户映射为不同的内容。与分散性一样,这种情况也是应当避免的,因此好的哈希算法应能够尽量降低缓冲的负荷。
5.Redis Hash一致性算法
5.1) redis保存数据的方式:将内存想像是一个闭环,将内存分为2 ^32个地址。将节点的IP+算法确定哈希值,之后在内存中确认节点位置。当保存数据的时候,根据key进行哈希运算,在闭环上确认位置。根据当前key的位置,顺时针寻找最近的节点进行挂载。
5.2)均衡性:如果遇到节点负载不均时,会自动的启动虚拟节点,进行数据的平衡
5.3) 单调性:如果节点增加,原有节点挂在数据会动态迁移
5.4) 分散性:由于分布式的项目部署,导致项目不能全部获取node节点.一个key对应多个位置
5.5)负载:负载是从另一个角度谈论分散性。一个位置对应多个key。
6 redis持久化策略
6.1) RDB模式:该模式是redis中默认的持久化策略
手动命令
save:立即执行持久化操作,其他的操作都会陷入阻塞
bgsave:在后台运行,不会让其他操作陷入阻塞
特点
持久化的效率最高,记录内存快照,每次保存都是最新的数据
RDB模式占用空间小
RDB模式保存数据是加密的
自动触发,持久化策略
save 900 1 在900秒内有一个set操作,则持久化一次
save 300 10 在300秒内执行10次set操作,则持久化一次
save 60 10000 在60秒内执行10000次set操作,则持久化一次
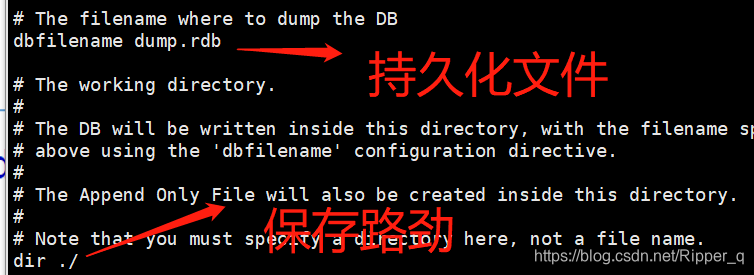
6.2) AOF模式
AOF模式是将用户的全部操作过程,写入文件中,默认是关闭的,如果需要启动,则修改特定的配置文件
启动策略:
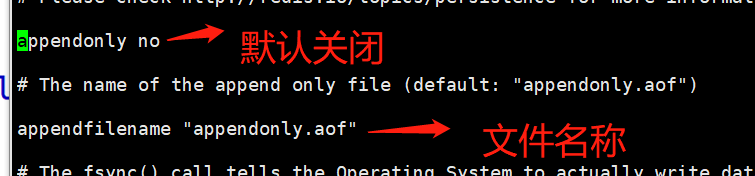
持久化策略
appendfsync always 当用户执行一次set操作,则持久化一次
appendfsync everysec 每秒执行一次持久化
appendfsync no 由操作系统设定(一般不用)
AOF与RDB区别
- 用户默认使用RDB模式,如果开启AOF模式则使用AOF
2)RDB模式的效率高于AOF模式
3)RDB模式记录的是内存快照,AOF模式记录用户全部的操作过程
4)备份策略不同:
RDB模式定期备份,可能会造成数据丢失
AOF模式可以实现数据的实时备份,但是效率较低
5)RDB模式占用磁盘空间下,恢复数据的时间短
AOF模式占用磁盘空间大,恢复数据的时间长
6) RDB模式欸分加密的
AOF模式备份明码保存
7 redis内存策略
7.1) LRU算法
内存管理的一种页面置换算法,对于再内存中但又不用的数据块(内存块)叫做LRU,操作系统会根据哪些数据属于LRU而将其移出内存二腾出来空间来加载另外的数据。
7.2)内存策略
- volatile-lru 设定了超时时间的数据,采用lru算法
- allkeys-lru 所有的key中使用lru算法
- volatile-random 设定了超时时间的随机删除
- allkeys-random 所有key的随机删除
- valatile-ttl 将要过期的数据,提前删除
- Noeviction 不会删除数据,但是会返回错误信息
- Note 由操作系统负责
内存策略修改

8 redis主从
复制文件
cp -r shards sentinel
修改持久化文件名称
dump_6379.rdb,dump_6380.rdb,dump_6381.rdb,
启动三台服务器

redis-cli -p 6379 进入客户端
info replication检查当前节点状态
默认情况下redis节点都是master
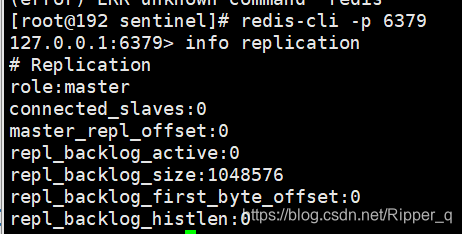
将6380,6381挂载到6379上
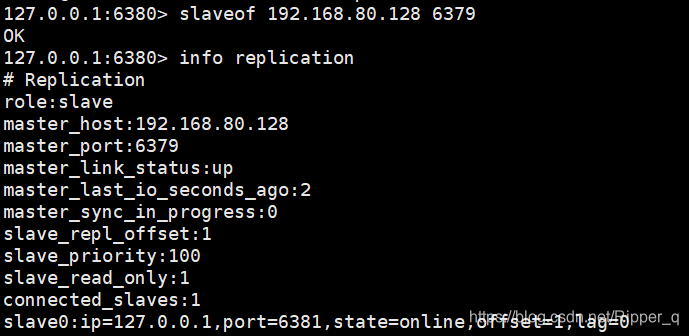
master中set数据,看从机是否有数据
8 哨兵实现高可用
哨兵:监控主机的状态,当主机宕机后,由哨兵负责推选出新的主机,其他机器都会执行slaveof指令
复制哨兵文件
cp sentinel.conf sentinel/
编辑哨兵配置文件
哨兵投票的票数
sentinel monitor mymaster ip 6379 1
修改推选实践

修改推选超时时间

启动哨兵
redis-sentinel sentinel.conf
将6379节点宕机,检查redis哨兵是否会自动推选
多个哨兵实现redis高可用
将原有哨兵复制三份
修改哨兵配置文件
端口
修改哨兵数量

修改序列号,保证不一样

分别启动多台哨兵,检查哨兵的状态,将redis主机宕机,检查哨兵是否自动推选。
//配置多台哨兵
/*Set<String> sentinels = new HashSet<>();
sentinels.add("192.168.123.122:6379");
sentinels.add("192.168.123.122:6380");
sentinels.add("192.168.123.122:6381");
JedisSentinelPool pool = new JedisSentinelPool("mymaster",sentinels,jedisPoolConfig);*/
9 redis集群
创建集群文件夹
mkdir cluster

mkdir 7000 7001 7002 7003 7004 7005 7006 7007 7008

拷贝配置文件
cp redis.conf cluster/7000
修改配置文件
取消I绑定

关闭保护模式
修改端口号
开启后台启动
修改pid文件路劲

修改持久化文件路劲

定义内存策略
启动集群
添加集群配置文件

开启集群超时
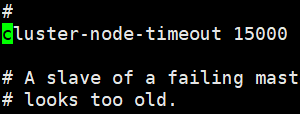
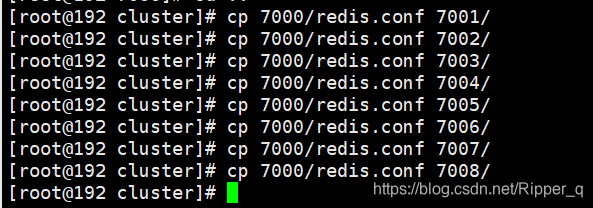
复制多个配置文件
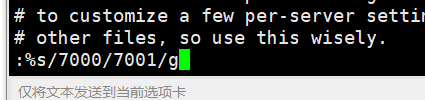
批量修改对应的文件:7001,7002,7003,7004,7005,7006,7007,7008
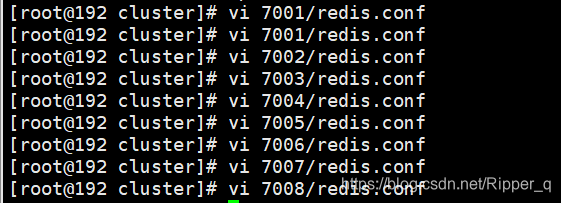
编辑redis启动脚本
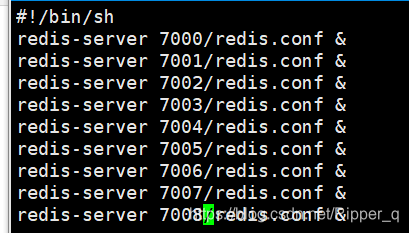
启动redis脚本
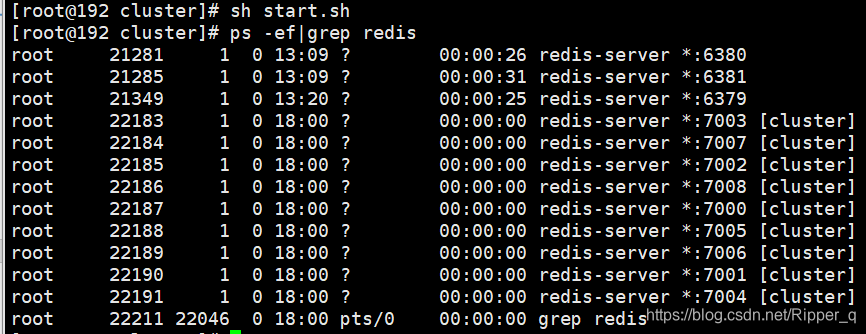
搭建集群
编辑ruby脚本命令
./src/redis-trib.rb create --replicas 2 192.168.80.128:7000 192.168.80.128:7001 192.168.80.128:7002 192.168.80.128:7003 192.168.80.128:7004 192.168.80.128:7005 192.168.80.128:7006 192.168.80.128:7007 192.168.80.128:7008
默认的集群分配,yes即可
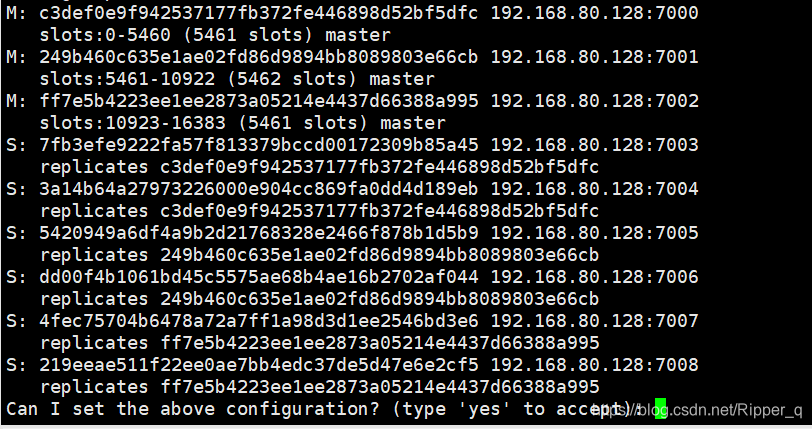
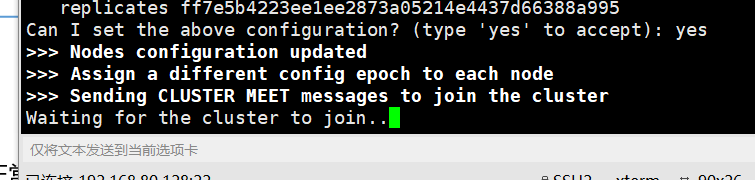
redis集群宕机条件
1,集群中宕机一台主机,且没办法从机替代,集群将宕机
2,当主机没有从机,可向其他主机借用多余的从机,但是其他主机必须给自己留一个
9台redis集群节点宕机5-7次时集群才崩溃
6台redis集群节点宕机2-4台时集群崩溃
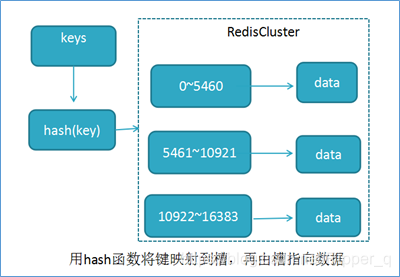
redis hash槽
rediscluster采用此分区,所有的键根据哈希函数(CRC16[key]&16383)映射到0-16384槽内,共16384个槽位,每个接待维护部分槽及槽所映射的键值数据,根据主节点的个数,均衡划分区间.
当向redis集群中插入数据时,首先将key进行计算,之后将计算结果匹配到槽中,之后再将数据set到管理该槽的节点中
代码配置集群
//配置集群
/*Set<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.123.122", 7000));
nodes.add(new HostAndPort("192.168.123.122", 7001));
nodes.add(new HostAndPort("192.168.123.122", 7002));
nodes.add(new HostAndPort("192.168.123.122", 7003));
nodes.add(new HostAndPort("192.168.123.122", 7004));
nodes.add(new HostAndPort("192.168.123.122", 7005));
nodes.add(new HostAndPort("192.168.123.122", 7006));
nodes.add(new HostAndPort("192.168.123.122", 7007));
nodes.add(new HostAndPort("192.168.123.122", 7008));
JedisCluster cluster = new JedisCluster(nodes);*/

















 3555
3555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









