




论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/29146
动机
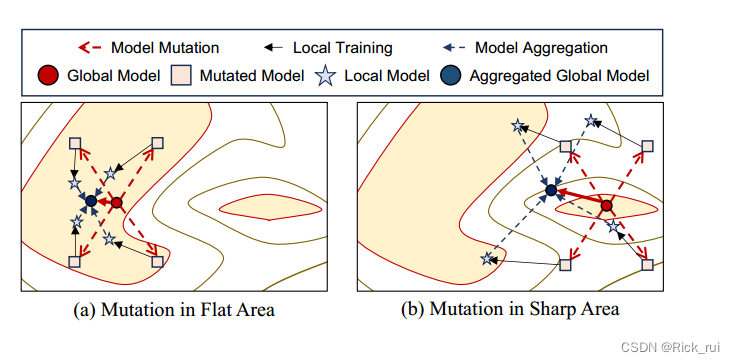
Many previous works observed that the well-generalized solutions are located in flat areas rather than sharp areas of the loss landscapes.
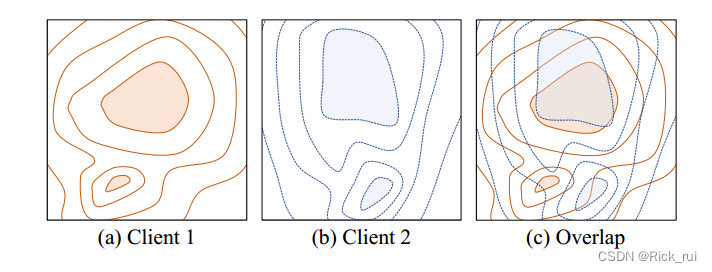
通常,由于每个本地模型的任务是相同的,因此每个客户端的损失情况仍然相似。直观上,与尖锐的最佳区域相比,不同客户端的平坦最佳区域部分重叠的可能性更大。换句话说,当模型收敛到重叠区域时,它可以在大多数客户端中实现高推理性能。
怎么做能达到效果?
FedMut框架
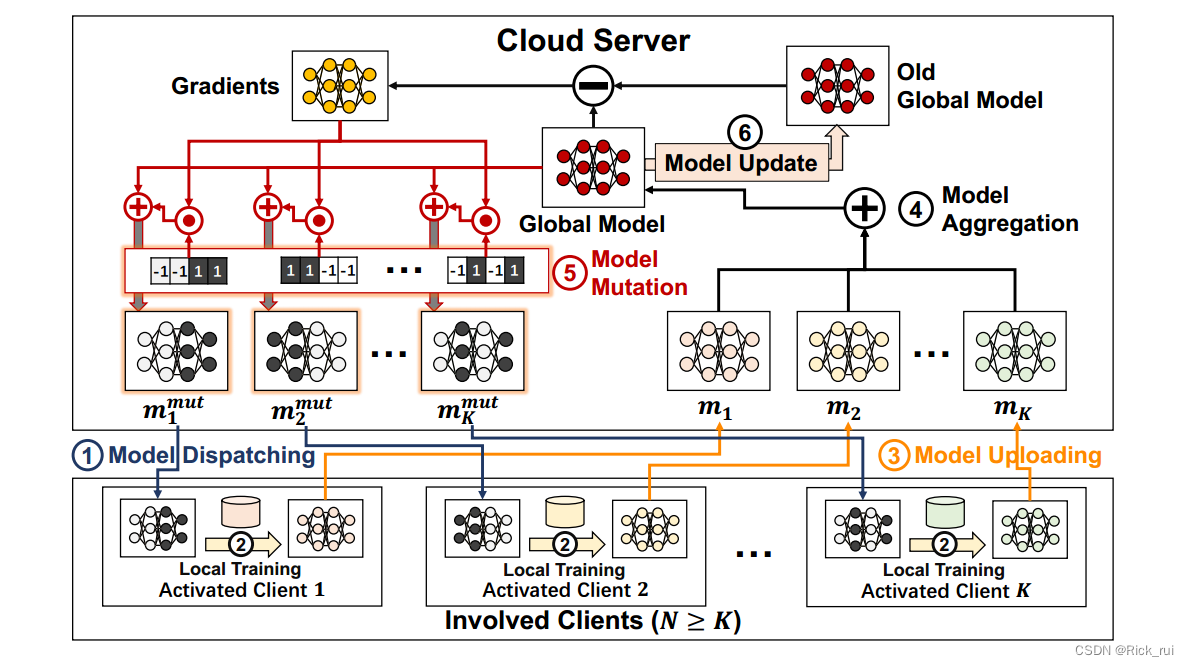
global model :
ω g l b = { l a y e r 1 , l a y e r 2 , . . . , l a y e r L } . \omega_{glb} = \{ layer_1, layer_2,..., layer_L \}. ωglb={
layer1,layer2,...,layerL}.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 746
746

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









