



 本文探讨了高维稀疏解逼近问题,通过优化问题和概率论视角解释了L1正则化为何产生稀疏模型。介绍了L1和L1.5正则化的求解方法,包括软阈值迭代算法和重赋权技巧,并通过实例分析了在不同矩阵条件下L1和L1.5的表现。
本文探讨了高维稀疏解逼近问题,通过优化问题和概率论视角解释了L1正则化为何产生稀疏模型。介绍了L1和L1.5正则化的求解方法,包括软阈值迭代算法和重赋权技巧,并通过实例分析了在不同矩阵条件下L1和L1.5的表现。
一、稀疏解的逼近问题
对于高维稀疏解的逼近问题,可以归结为模型
y=Ax+ϵ y=A x+\epsilon y=Ax+ϵ
其中,A∈RM×NA \in \mathbb{R} ^{M \times N}A∈RM×N是给定或者训练得到的M×NM \times NM×N矩阵,y∈RM\bf y \in \mathbb{R} ^My∈RM是测得的数据,ϵ\epsilonϵ是扰动噪声。我们的目的是根据已知数据y,A,ϵ\bf y ,A,\epsilony,A,ϵ,来反演高维稀疏解x∈RN\bf x \in \mathbb{R} ^Nx∈RN。
机器学习的回归问题中,为了防止过拟合和提高模型泛化性能,对原始损失函数引入额外惩罚项信息,即LpL_pLp正则化
x=argminx∥Ax−y∥2+λ∥x∥Lpp,0≤p≤2
\bold{x}=\arg \min_{\bold{x}} \left \| A \bold{x} -\bold{y}\right \| ^2+\lambda \left \| \bold{x}\right \| _{L_p}^{p} ,0 \le p \le 2
x=argxmin∥Ax−y∥2+λ∥x∥Lpp,0≤p≤2
特别的,当p=0p=0p=0时,
∥x∥L0=∑i=1NIxi≠0,Ixi≠0={1xi≠00xi=0
\left \| \bold x \right \| _{L_0}=\sum_{i=1}^N I_{x_i \ne 0},I_{x_i \ne 0}=
\left\{\begin{matrix}
1 & x_i \ne 0\\
0 & x_i = 0
\end{matrix}\right.
∥x∥L0=i=1∑NIxi=0,Ixi=0={10xi=0xi=0根据不同的问题,选择合适的参数ppp。
L1L_1L1正则化可以使得参数稀疏化,从而过滤掉模型的一些无用特征,提高模型的泛化能力,降低过拟合的可能。L2L_2L2正则化可以使得参数平滑,防止模型过拟合。因此对比而言,L1L_1L1正则化更适合处理高维稀疏数据。
下面以二维为例,从优化问题和概率论角度来讨论为什么L1L_1L1正则化产生稀疏模型。
1.1、优化问题角度
此时模型的求解转化为如下的优化问题
x=argminx∥[a11a12a21a22][x1x2]−[y1y2]∥2+λ∑i=12∣xi∣p
\bold{x}=\arg \min_{x} \left \| \begin{bmatrix}
a_{11} & a_{12}\\
a_{21} & a_{22}
\end{bmatrix}\begin{bmatrix}
x_1\\
x_2
\end{bmatrix}-\begin{bmatrix}
y_1 \\
y_2
\end{bmatrix} \right \| ^2 +\lambda \sum_{i=1}^2 \left | x_i \right | ^p
x=argxmin∥∥∥∥[a11a21a12a22][x1x2]−[y1y2]∥∥∥∥2+λi=1∑2∣xi∣p
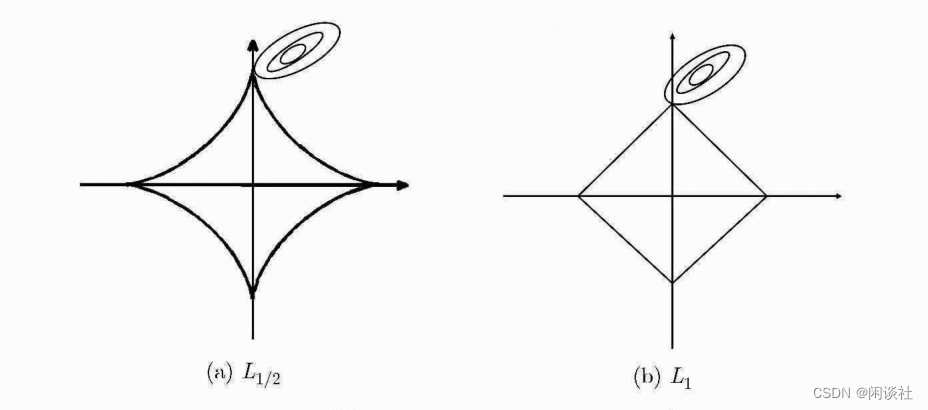
将损失函数f(x)f(x)f(x)投影到x1,x2x_1,x_2x1,x2平面,即等值线(如图彩色线条),并分别画出L1L_1L1正则化项和L2L_2L2正则化项(如图黑色线条)
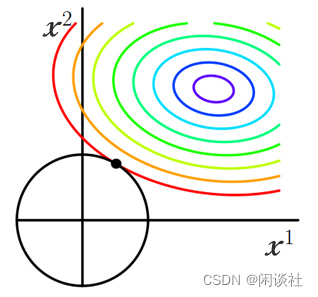
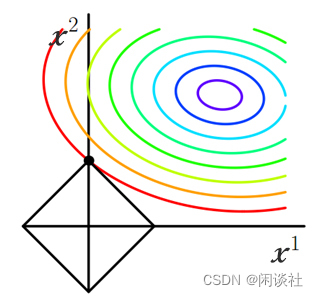
正则化项同拉格朗日乘子的作用一样,起了约束作用。因为当损失函数f(x)f(x)f(x)的等值线与正则化项首次相交的地方就是最优解。从上图可见,L1L_1L1正则化项比L2L_2L2多出4个突出的角,当等值线与这些角相交的机率会大大增加。而在这些角上,某个权值xix_ixi等于0。当维数增加,L1L_1L1突出的角更多,因此更容易产生稀疏模型。
1.2、概率论问题角度}
L1L_1L1正则化相当于为x\bf xx加入了Laplace先验分布,而L2L_2L2正则化项相当于为x\bf xx加入了Gaussian先验分布。
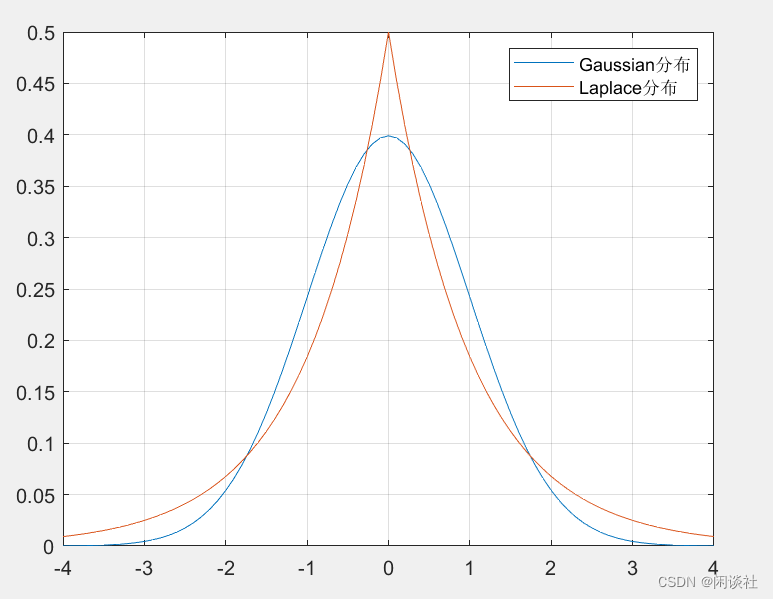
从分布图直观上看,在两端Gaussian分布的概率pG(x)p_G(x)pG(x)小于Laplace分布的概率pL(x)p_L(x)pL(x),且在中间段Gaussian分布等于0和接近0的分布很接近,说明Gaussian分布下的$\bf x $比较均匀。而Laplace分布等于0处的概率远大于其他部分,说明Laplace分布下的x 存在更多的0元素。
二、L1L_{1}L1与L1/2L_{1/2}L1/2正则化的求解
2.2、L1L_1L1的软阈值迭代算法
对于连续可微的无约束优化问题
minx∈Rf(x)
\min _{\bf x \in \mathbb{R} } f(\bf x)
x∈Rminf(x)
且满足Lipschitz连续条件
∥▽f(xk)−▽f(xk−1)∥2≤L(f)∥xk−xk−1∥2
\left \| \bigtriangledown f(\bf x_k)-\bigtriangledown f(\bf x_{k-1}) \right \| _2 \le L(f)\left \| \bf \bf x_k-\bf \bf x_{k-1} \right \| _2
∥▽f(xk)−▽f(xk−1)∥2≤L(f)∥xk−xk−1∥2
根据梯度法,给定初始点x0∈Rx_0 \in Rx0∈R和初始步长t,有
xk=xk−1−t▽f(xk−1)
\bf x_k=\bf x_{k-1}-t \bigtriangledown f(\bf x_{k-1})
xk=xk−1−t▽f(xk−1)
将f(x)f(\bf x)f(x)在xk−1\bf x_{k-1}xk−1处做二阶泰勒展开,并省略高阶项
f(x)=f(xk−1)+⟨x−xk−1,▽f(xk−1)⟩+⟨∥x−xk−1∥22,▽2f(xk−1)⟩2
f(\bf x)=f(\bf x_{k-1})+\left \langle \bf x-\bf x_{k-1}, \bigtriangledown f(\bf x_{k-1})\right \rangle +\frac{ \left \langle \left \|\bf x-\bf x_{k-1} \right \|_2^2 , \bigtriangledown ^2f(\bf x_{k-1})\right \rangle}{2}
f(x)=f(xk−1)+⟨x−xk−1,▽f(xk−1)⟩+2⟨∥x−xk−1∥22,▽2f(xk−1)⟩
结合上述公式,可得
xk=argminx{f(xk−1)+⟨x−xk−1,▽f(xk−1)⟩+∥x−xk−1∥222t}
\bf x_k =\arg \min _{\bf x} \left \{ f(\bf {x_{k-1}})+\left \langle \bf {x}-\bf {x_{k-1}},\bigtriangledown f(x_{k-1}) \right \rangle +\frac{\left \| x-x_{k-1} \right \|_2^2 }{2t} \right \}
xk=argxmin{f(xk−1)+⟨x−xk−1,▽f(xk−1)⟩+2t∥x−xk−1∥22}
忽略常数项,则上式又可写成
xk=argminx(▽f(xk−1))T(x−xk−1)+12t(x−xk−1)T(x−xk−1)=argminx12t[x−(xk−1−2t▽f(xk−1)]T(x−xk−1)
\begin{aligned}
\bf x_k&=\arg \min _{\bf x} (\bigtriangledown \bf f(x_{k-1}))^T(x-x_{k-1})+\frac{1}{2t}(x-x_{k-1})^T(x-x_{k-1}) \\
&=\arg \min _{\bf x} \bf \frac{1}{2t} \left [ x-(x_{k-1}-2t\bigtriangledown f(x_{k-1}) \right ]^T(x-x_{k-1})
\end{aligned}
xk=argxmin(▽f(xk−1))T(x−xk−1)+2t1(x−xk−1)T(x−xk−1)=argxmin2t1[x−(xk−1−2t▽f(xk−1)]T(x−xk−1)
可见有两个零点,取中点得到函数的最小值
xk=12[xk−1−2t▽f(xk−1)+xk−1]=xk−1−t▽f(xk−1)
\begin{aligned}
\bf x_k&=\bf \frac{1}{2}\left [ x_{k-1}-2t\bigtriangledown f(x_{k-1})+x_{k-1} \right ] \\
&=\bf x_{k-1}-t\bigtriangledown f(x_{k-1})
\end{aligned}
xk=21[xk−1−2t▽f(xk−1)+xk−1]=xk−1−t▽f(xk−1)
将上述的梯度法思想用到L1L_1L1正则化问题,得到迭代公式
xk=argminx{f(xk−1)+⟨x−xk−1,▽f(xk−1)⟩+∥x−xk−1∥222t+λ∥x∥1}
\bf x_k =\arg \min _{\bf x} \left \{ f(\bf {x_{k-1}})+\left \langle \bf {x}-\bf {x_{k-1}},\bigtriangledown f(x_{k-1}) \right \rangle +\frac{\left \| x-x_{k-1} \right \|_2^2 }{2t }+\lambda \left \| x \right \|_1 \right \}
xk=argxmin{f(xk−1)+⟨x−xk−1,▽f(xk−1)⟩+2t∥x−xk−1∥22+λ∥x∥1}
忽略常数项,则上式又可写成
xk=argminx{∥x−(xk−1−t▽f(xk−1))∥222t+λ∥x∥1}
\bf x_k =\arg \min _{\bf x} \left \{\frac{\left \| x-(x_{k-1}-t\bigtriangledown f(x_{k-1}) )\right \|_2^2 }{2t }+\lambda \left \| x \right \|_1 \right \}
xk=argxmin{2t∥x−(xk−1−t▽f(xk−1))∥22+λ∥x∥1}
考虑一般的优化问题
xk=argminx{∥x−s∥222t+λ∥x∥1}=argminx∑i=1n12t(xi−si)2+λ∣xi∣
\begin{aligned}
\bf x_k &=\bf \arg \min_x \left \{\frac{\left \| x-s\right \|_2^2 }{2t }+\lambda \left \| x \right \|_1 \right \} \\
&= \arg \min_x \sum _{i=1}^n \frac{1}{2t}(x_i-s_i)^2+\lambda \left | x_i \right |
\end{aligned}
xk=argxmin{2t∥x−s∥22+λ∥x∥1}=argxmini=1∑n2t1(xi−si)2+λ∣xi∣
令g(xi)=12t(xi−si)2+λ∣xi∣g(x_i)=\frac{1}{2t}(x_i-s_i)^2+\lambda \left | x_i \right |g(xi)=2t1(xi−si)2+λ∣xi∣,对g(xi)g(x_i)g(xi)求导并令其等于0,
dgdxi=1t(xi−si)+sgn(xi)=0⟹xi=si−λt⋅sgn(xi)
\begin{aligned}
&\frac{\mathrm{d}g }{\mathrm{d}x_i} =\frac{1}{t}(x_i-s_i)+sgn(x_i)=0 \\
&\Longrightarrow x_i=s_i-\lambda t·sgn(x_i)
\end{aligned}
dxidg=t1(xi−si)+sgn(xi)=0⟹xi=si−λt⋅sgn(xi)
即当xi>0x_i>0xi>0时,xi=si−tλx_i=s_i-t\lambdaxi=si−tλ;当xi=0x_i=0xi=0时,xi=si=0x_i=s_i=0xi=si=0;xi《0x_i《0xi《0时,xi=si+tλx_i=s_i +t\lambdaxi=si+tλ.\
所以,{xi=si−tλ if si>tλxi=0 if −tλ≤si≤tλxi=si+tλ if si<−tλ
\begin{cases}
x_i=s_i-t\lambda & \text{ if } s_i>t\lambda \\
x_i=0 & \text{ if } -t\lambda \le s_i \le t\lambda \\
x_i=s_i+t\lambda & \text{ if } s_i<-t\lambda
\end{cases}
⎩⎪⎨⎪⎧xi=si−tλxi=0xi=si+tλ if si>tλ if −tλ≤si≤tλ if si<−tλ
上式可进一步化简,得
xi=max(∣si∣−λt,0)⋅sgn(si)=Pλt(s)
x_i=\max( \left | s_i \right | -\lambda t,0)·sgn(s_i)=P_{\lambda t}(s)
xi=max(∣si∣−λt,0)⋅sgn(si)=Pλt(s)
即
xk=Pλt(s)
\bf x_k=P_{\lambda t}(s)
xk=Pλt(s)
综上所述,方程的解可写为
xk=Pλt(xk−1−t▽f(xk−1))
\bf x_k=P_{\lambda t}(x_{k-1}-t\bigtriangledown f(x_{k-1}))
xk=Pλt(xk−1−t▽f(xk−1))
其中,PλtP_{\lambda t}Pλt为软阈值算子,步长ttt可取1L(▽f)\frac{1}{L(\bigtriangledown f)}L(▽f)1。
2.1、L1/2L_{1/2}L1/2正则化算法
2008年,徐宗本在《 L1/2L_{1/2}L1/2正则化》中证明,L1/2L_{1/2}L1/2正则化子比L1L_{1}L1正则化子具有更好的稀疏性和稳健性。
文献中为了求解L1/2L_{1/2}L1/2正则化问题,提出重赋权迭代求解思想,将L1/2L_{1/2}L1/2正则化问题转化为L1L_{1}L1正则化问题
xk+1=argminx∥y−Ax∥22+λ∑i=1N∣xi∣∣xi,k∣
x_{k+1}=\arg \min _x \left \| y-Ax \right \| _2^2+\lambda \sum_{i=1}^N \frac{\left | x_{i} \right |}{\sqrt{\left | x_{i,k} \right | } }
xk+1=argxmin∥y−Ax∥22+λi=1∑N∣xi,k∣∣xi∣
因为xix_ixi可能出现0,为了保证算法可实施,可采用1∣xi,k∣+ϵ\frac{1}{\sqrt{\left | x_{i,k} \right |}+\epsilon}∣xi,k∣+ϵ1替代1∣xi,k∣\frac{1}{\sqrt{\left | x_{i,k} \right |}}∣xi,k∣1,即
xk+1=argminx∥y−Ax∥22+λ∑i=1N∣xi∣∣xi,k∣+ϵ
x_{k+1}=\arg \min _x \left \| y-Ax \right \| _2^2+\lambda \sum_{i=1}^N \frac{\left | x_{i} \right |}{\sqrt{\left | x_{i,k} \right | } +\epsilon}
xk+1=argxmin∥y−Ax∥22+λi=1∑N∣xi,k∣+ϵ∣xi∣
三、算例
3.1、例1——高斯分布矩阵
数据源:
1、随机产生250×500250 \times 500250×500的高斯信号矩阵A,矩阵条件数为 5.5415
2、 随机产生500×1500 \times 1500×1的高斯分布数据x\bf xx,再随机令其中20个元素非零,其余为零。。由Ax=yA \bf x=yAx=y,可3、得到数据y\bf yy
对得到的数据y\bf yy,施加1%1\%1%的随机噪声
计算结果:
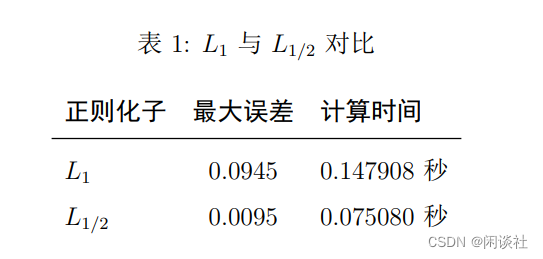
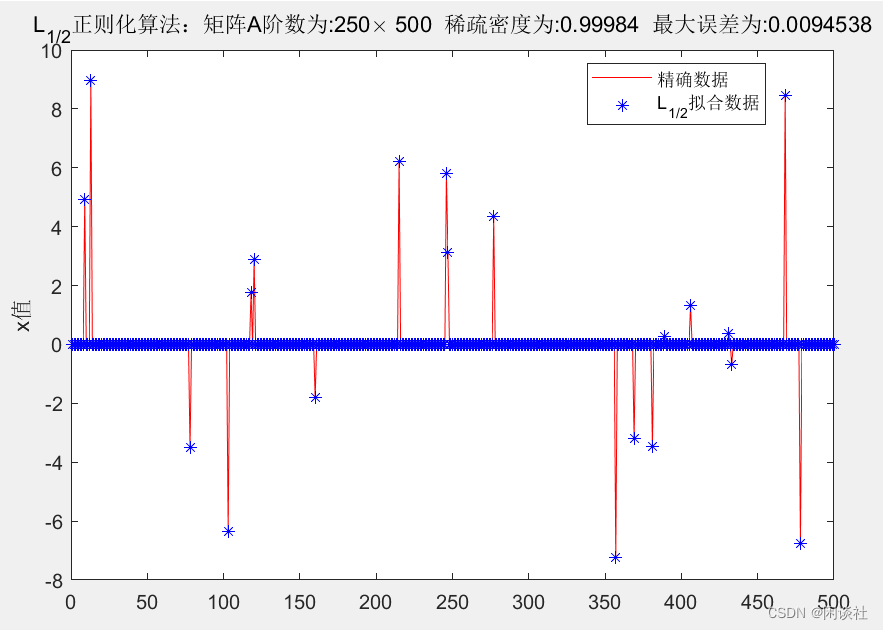
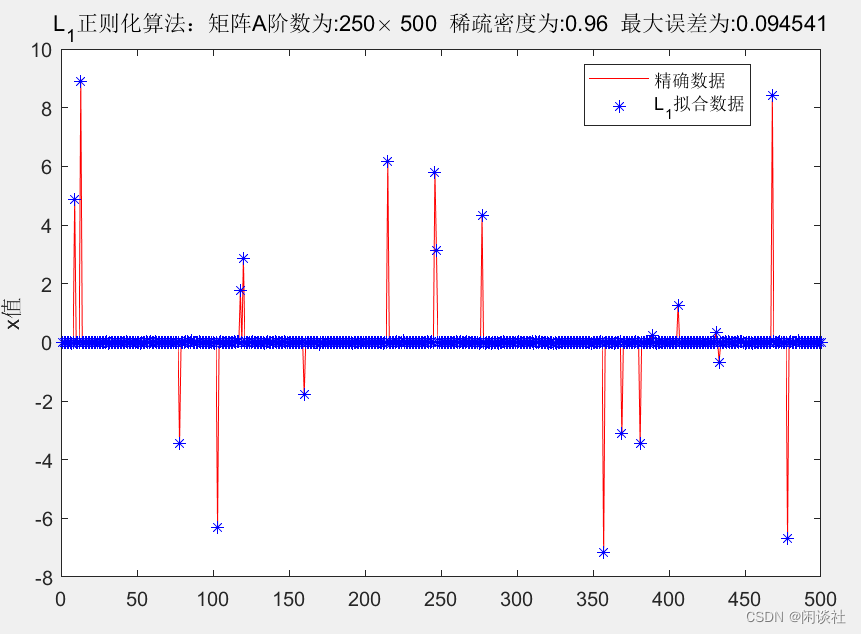
3.2、例2-积分方程
数据源:
1、考虑一个卷积型积分方程例子:
∫01K(x,t)g(t)dt=f(x),0≤x≤1
\int_0^1K(x,t)g(t) \mathrm{d} t=f(x),0\le x\le1
∫01K(x,t)g(t)dt=f(x),0≤x≤1
其中核函数K(x,t)=extK(x,t)=e^{xt}K(x,t)=ext。当核函数矩阵为20×2020 \times 2020×20时,其条件数为2463.
2、 随机产生20×120 \times 120×1的高斯分布数据x\bf xx,再随机令其中5个元素非零,其余为零。由Kx=yK \bf x=yKx=y,可得到数据y\bf yy
3、对得到的数据y\bf yy,施加1%1\%1%的随机噪声
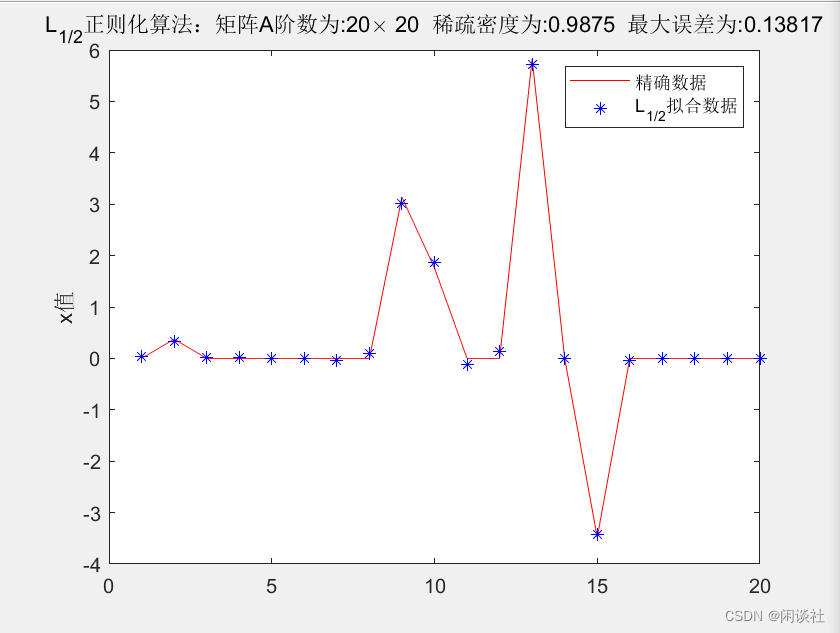
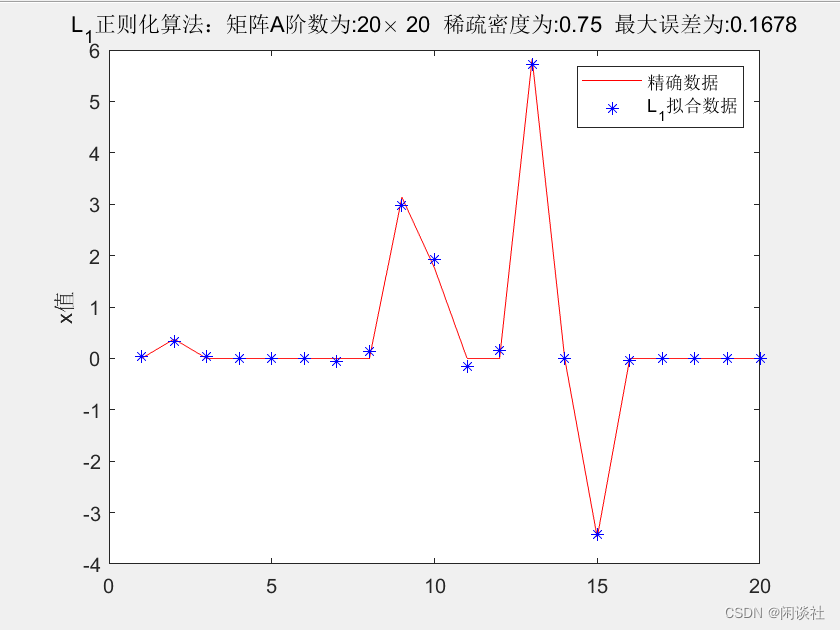
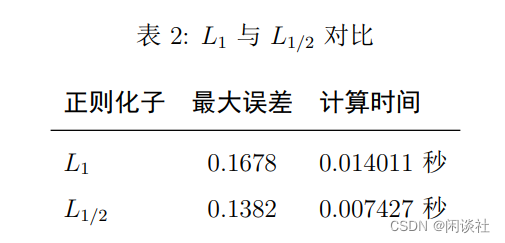
3.3、例3-Hilbert矩阵
数据源:
1、 产生500×500500 \times 500500×500的Hilbert矩阵A,矩阵条件数为6.8337×10206.8337 \times 10^{20}6.8337×1020
2、随机产生500×1500 \times 1500×1的高斯分布数据x\bf xx,再随机令其中20个元素非零,其余为零。由Ax=yA \bf x=yAx=y,可得到数据y\bf yy
3、对得到的数据y\bf yy,施加1%1\%1%的随机噪声

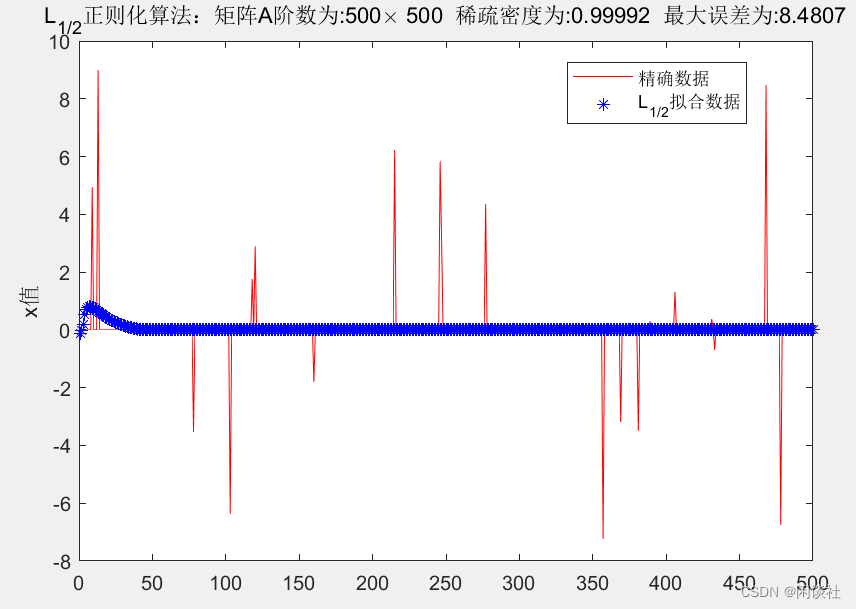
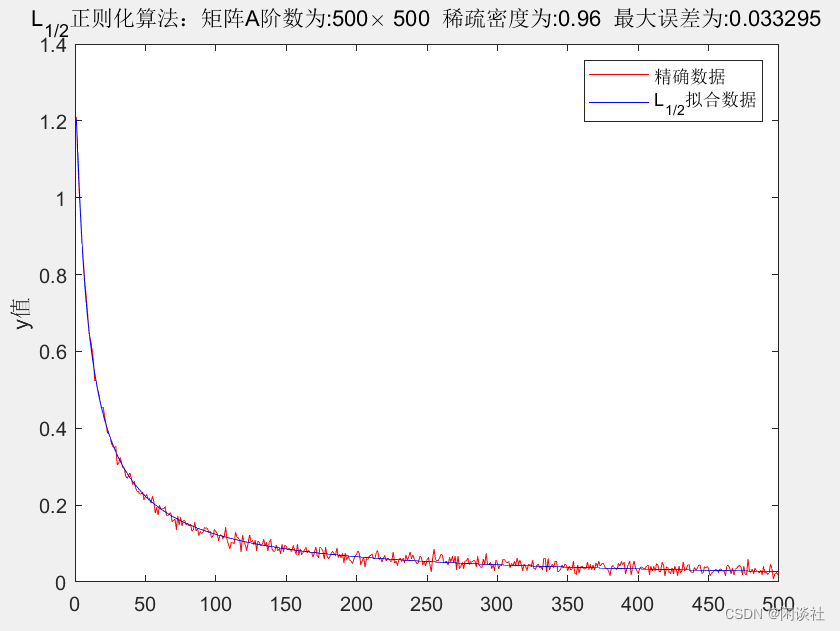
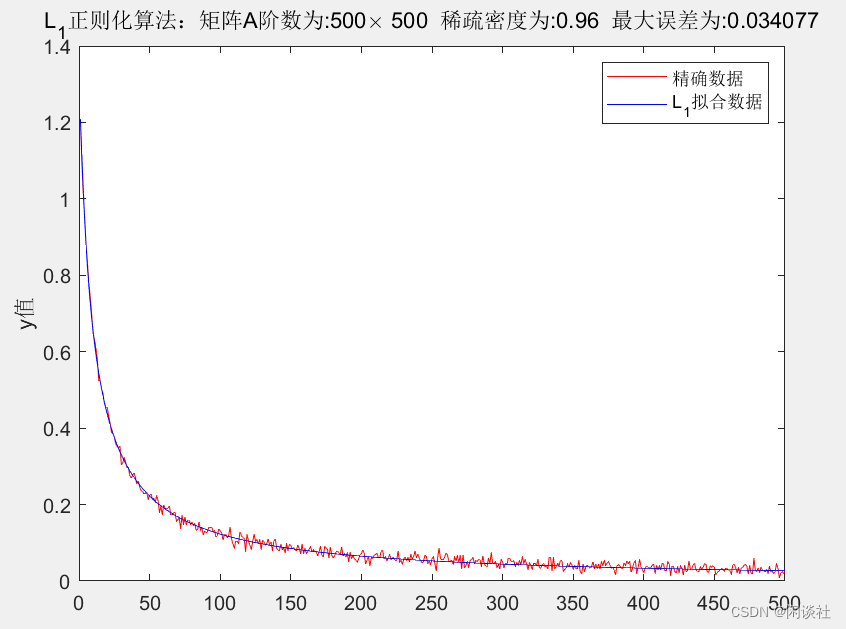
Hilbert矩阵下的高维稀疏数据反演,不论是L1L_1L1正则化还是L1/2L_{1/2}L1/2正则化,得到的结果均不理想,不能将原数据x\bf xx的稀疏性表现出来,而是将其磨光。但从观测数据y\bf yy上分析,虽然拟合的y\bf yy也被磨光处理,但依旧能较好的拟合真实数据。
经过多次尝试发现,Hilbert矩阵下的高维稀疏数据逼近模型,即Ax=yA \bf x=yAx=y,对于固定的A和y\bf yy,其解x\bf xx不唯一。
这是因为Hilbert矩阵的特征值矩阵高度稀疏,当x\bf xx也是稀疏数据,运算时将会丢失很多关键信息,因此无法正确反演稀疏数据x\bf xx。以16位有限数字为界,则500×500500 \times 500500×500的Hilbert矩阵,其特征值矩阵的稀疏密度为93%。


















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











