



关于模型建立过程中参数问题
在模型建立的过程中,我们可以通过继承nn.Module类别来简化这个过程。在网络参数定义的过程中,我们可以通过几个方式来建立自己需要的参数:
import torch
import torch.nn as nn
class model(nn.Module):
def __init__(self):
super(model, self).__init__()
#1.直接建立
self.Linear1 = nn.Linear(1, 2)
#2.直接建立的第二种
self.array = torch.zeros((2, 3))
#3.通过nn.Sequential
self.Layer = nn.Sequential(
nn.Linear(3, 4),
nn.Conv2d(1, 1, kernel_size=3)
)
#4.通过self.register_buffer
self.register_buffer("temp1", torch.ones((1, 2)))
#5.通过self.register_parameters
self.register_parameter("temp2", nn.Parameter(torch.ones(1, 3)))
net = model()
print(list(net.named_parameters()))
一、哪些参数在训练过程中被更新
在网络进行参数更新的过程中,我们需要传递net.parameters()给优化器,所以我们可以通过这个来看到哪些参数实际上会被更新。
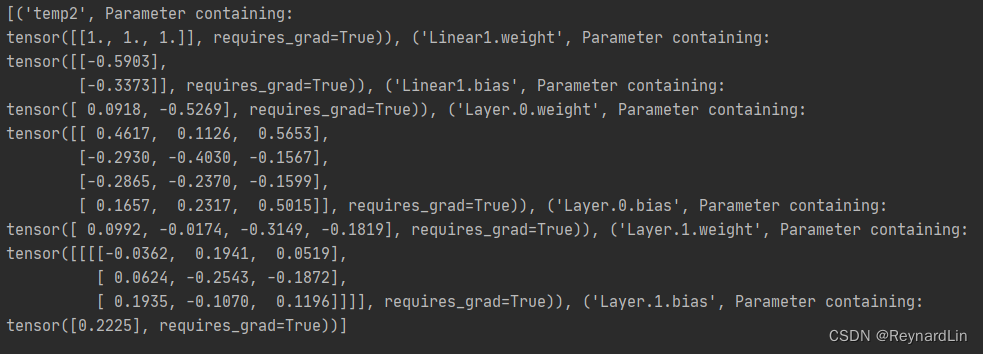
通过print出来我们可以看到,第二种和第四种在训练过程中并不会被更新。
二、哪些参数会被保存
一般我们通过net.state_dict()来保存网络参数,因此通过这个可以确定哪些参数最总会保存下来。

可以看到只有第二种方法没有被保存下来。
总结
在这里小结了模型定义过程中,参数的确定方法。
其中直接的方法并不适用于一个普通torch张量的定义,但是适合适用nn里面的函数。并且第二种方法在任何过程中均没用,可以算是一个错误的用法。
而当我们需要一个不被更新的参数,除了require_grad=False之外,在定义的过程中,我们可以适用self.register_buffer来实现。例如MoCo之中的队列和MemoryBank。
这篇博客主要参考了下面的博客,但是对其中进行补充和改进,将其中的方法分类直接和间接两类,并且第一种方法我认为也是直接建立的方法之一,但是在更新和保存的过程中参数都可以用上。


















 9万+
9万+




 到【灌水乐园】发言
到【灌水乐园】发言







