







朴素匹配算法(蛮力算法)
逐个匹配,失败就右移窗口
性能分析
- 时间复杂度
- 最好情况:O(n+m),Ω(n)
- 每次匹配(O(m))都是开始即失败,只在最后一次成功(O(n))
- 最差情况:O(nm)
- 每次匹配都是到最后一个字符才失败,只在最后一次成功
- 最好情况:O(n+m),Ω(n)
- 空间复杂度
- 就地算法
Rabin-Karp算法
指纹映射
视字母表为d进制数位集合,d为字母表的势
- 往往采用d+1进制,不使用0位
- 后续hash时不能区分最高位的0
按上述映射将长度为m的字符串变为数串
- d>10时,数串对应的数将会剧烈膨胀,存储与计算均难以接受
- 时间复杂度为O(nm),退化为朴素算法
指纹哈希
记散列表长为M,将上述数串哈希到存储与计算可接受的范围内
- 例如:求2025! % 61
- 数串存储结构是String,(初始)计算哈希值过程成本正比于m(进制转换)
P与T子串匹配,必有P的哈希值与T子串哈希值相同
- 相同时才做进一步地逐位检验
哈希冲突
P与T子串不匹配,但P的哈希值与T子串哈希值相同
若各字符独立均匀分布,对应指纹亦为均匀分布,冲突率为1/M,M为哈希表长度
- 散列表越长,冲突率越低
快速指纹计算
窗口移动思想
在P右移中,仅计算去除最高位、右移扩大d倍、加入最低位带来的hash值影响,而不是逐位相加
- 去除最高位:最高位的对应d的数量级 % M
- 右移扩大d倍:当前hash值 × d % M
- 加入最低位:(新加入的最低位 + 当前hash值) % M
由P.substring(j, j + m)指纹计算P.substring(j + 1, j + m + 1)指纹只需O(1)时间
Knuth-Morris-Pratt算法
- P自左向右
- P内部从左到右
如果P.substring(0, j)与T.substring(s, s + j)匹配而P[j]与T[s + j]不匹配,那么下一个可能匹配的位置是P.substring(0, j)前缀与后缀相同的位置
next映射与next表
next[j]是P.substring(0, j)的一个子串p的长度,p既是最长的P.substring(0, j)真前缀,也是最长的P.substring(0, j)真后缀
- next映射是P串自身诱导的,与T串无关
- next[j] = max(index: P.substring(0, index) == P.substring(j - index, j))
- 如果P[j]失配,尝试用P[next[j]]匹配
- 即下次匹配从P.substring(0, j)的最长前后缀的下一个字符开始比对
next映射迭代性
next^k[j] := next[next[...next[next[j]]...]]
- 如果T[i]与P[j]失配
- P.substring(0, next[j]) == P.substring(j - next[j], j)
- 尝试T[i]与P[next[j]]匹配
- 如果T[i]与P[next[j]]失配
- P.substring(0, next[next[j]]) == P.substring(next[j] - next[next[j]], next[j])
- ......
- T[i]会尝试与所有P[next^k[j]]匹配,直到匹配成功
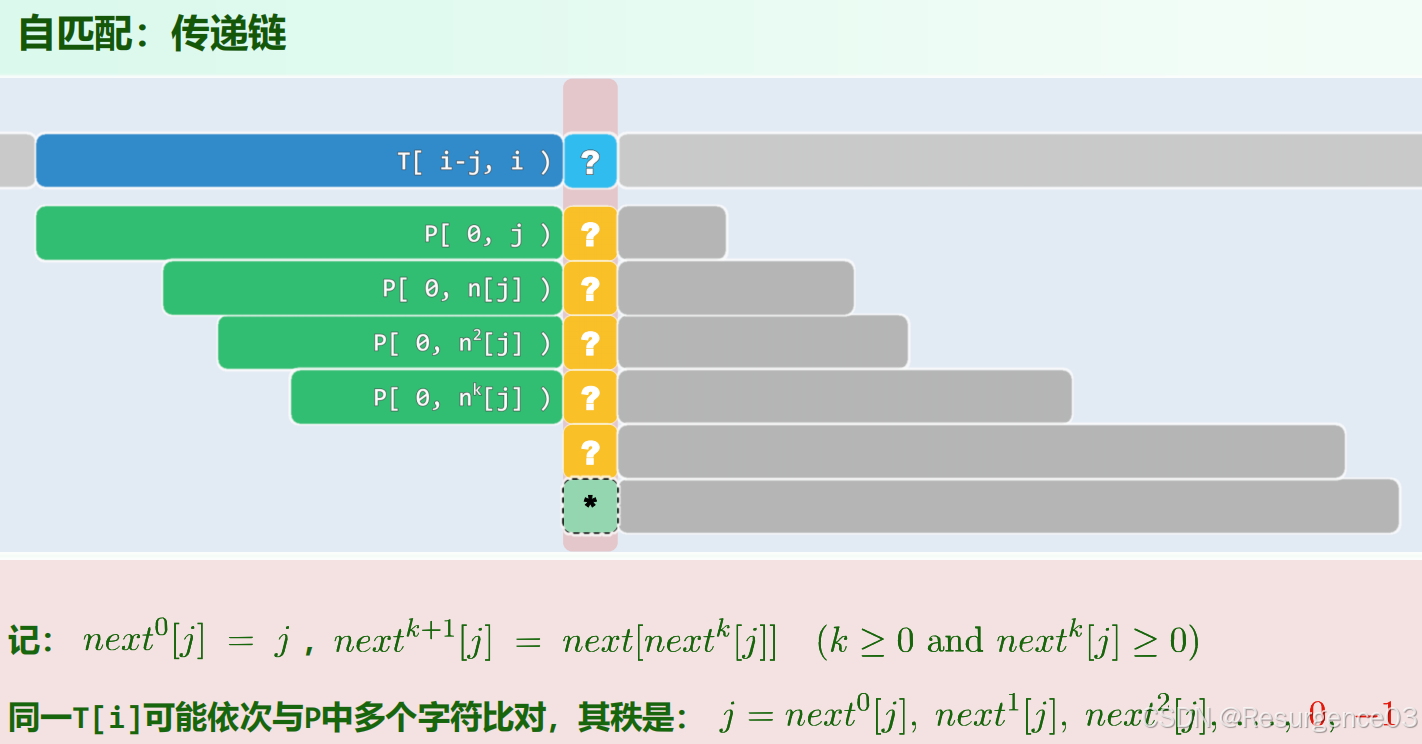
- 局部地看
- T[i]与P[j]尝试匹配的迭代
- 整体地看
- 能与T[i]匹配的j一定满足相同前后缀关系
- next映射将从大到小遍历所有的P.substring(0, j)相同前后缀长度
下次推进按j - next[j]步长推进
- 最长前后缀越长,next[j]越大,表明前后缀差距越小,越难推进
next表构造
对于0 <= j < m,因next映射将从大到小遍历所有的P.substring(0, j)相同前后缀长度,只需找到可增长的位置即可
next[j + 1] = next^k[j] + 1 iff P[j] = P[next^k[j]],k取等式成立的最小者
void nextInit () {
for (int j = 0; j < m; j++) {
if (j == 0) {
next[j] = -1;
}
else {
int mayMatchPosition = next[j - 1];
while (P[j - 1] != P[mayMatchPosition]) {
mayMatchPosition = next[mayMatchPosition];
}
next[j] = next[mayMatchPosition] + 1;
}
}
}真前后缀保证next[j] < j,算法必将终止
改进next表
在原有next表基础上
- 如果回退一步,待比对字符仍相同,即P[j] == P[next[j]]
- j = next[j]回退后,比对必然失败
- 一直回退到待比对字符不同的位置,即P[j] != P[next^k[j]],k取不等式成立的最小者
void improveNext () {
// next[0]固定为-1
for (int j = 1; j < m; j++) {
while (P[j] == P[next[j]]) {
next[j] = next[next[j]];
}
}
}性能分析
- 时间复杂度
- 建next表:O(m)
- 整体复杂度为O(n + m)
- P和T中每个字符只尝试一次
- 空间复杂度
- next表:O(m)
Boyer-Moore算法
- P自左向右
- P内部从右往左
坏字符策略:一旦失配,查BC表右移,优先匹配T中的这个失配字符(坏字符)
好后缀策略:一旦失配,查GS表右移,优先匹配已经匹配好的后缀部分(好后缀)
BC表
bc[ch]是一个数组下标,其给出P最右边ch字符的下标
对于字母表中的每个元素,记录其在P中从右往左数第一次出现的位置
- bc表从左往右扫描P串构造
void bcInit() {
for (int j = 0; j < sizeof(alphabet); j++) {
bc[j] = -1;
}
for (int j = 0; j < m; j++) {
bc[P[j]] = j;
}
}假设P[j]失配,对应T字符为b
- bc[b] < j
- 表明P[j]左边有b(或者P中根本没有b,此时指向通配符,相当于P整体移过b)
- P向右平移j - bc[b]
- bc[b] > j
- 表明P[j]右边有b
- P向右平移1跳过该字符

GS表
gs[j]是一个移动步长,如果P[j]位置与T[i]失配,P向右移动gs[j]长度,移动前后保持已经匹配的后缀部分,且移动前后尝试与T[i]匹配的P字符不同
- 换言之,T[i]之后原来匹配的部分平移后一定也匹配
- 自带改进
- gs[j]的所有可能取值必然均满足上述性质
- gs[j] <= |P|
- 如果P中没有好后缀,最多移过整个P串长度(最好情况)
- gs[j] > 1
- 如果刚开始就失配,只能移动1步
SS表
ss[j]是一个子串长度,从P[j]开始向前取长度为ss[j]的子串是P的长度为ss[j]的后缀
- P.substring(j + 1 - ss[j], j + 1) == P.substring(m - ss[j], m)
- ss[m - 1] = m
- ss[j] <= j + 1
- ss[j] = j + 1,P.substring(j + 1 - ss[j], j + 1)既是前缀,也是后缀
- ss[j] < j + 1,P.substring(j + 1 - ss[j], j + 1)是中段的后缀内容
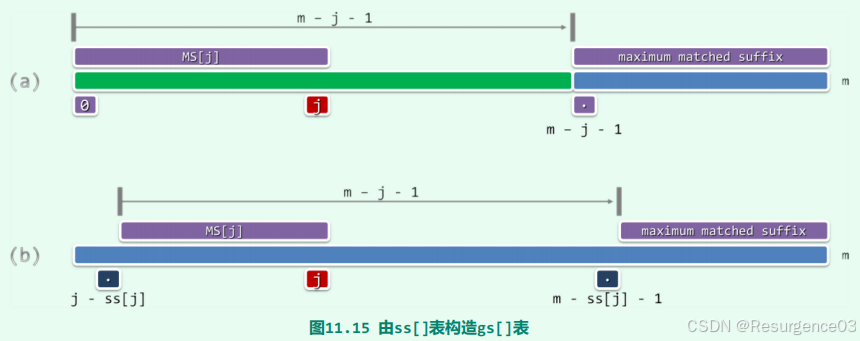
利用SS表构造GS表
单个GS表元素刻画
假设在P[m - (j + 1) - 1]处失配,最后匹配位置为P[m - (j + 1)]
- 即P的长度为j + 1的后缀P.substring(m - (j + 1), m)已经和T匹配
- 根据ss表,可以知道P.substring(m - (j + 1), m)(或后面的一部分)在P中所有出现的位置
- 每个ss[i] != 0的i值引导一次P.substring(m - ss[i], m)出现
- gs[m - (j + 1) - 1]应当为:让最靠右的可能匹配位置对准现在位置的步长最小值
- P.substring(m - (j + 1), m)局部如果在P头部出现,可以是局部出现
- P.substring(m - (j + 1), m)局部如果在P内部出现,那么必须整个都出现
- 否则必然不匹配
- 具有更短的偏移步长
构造算法
- 对于在P头部出现的P.substring(m - (j + 1), m)
- ss[j] = j + 1,P.substring(0, j + 1)既是前缀,也是后缀
- 对应最后匹配位置P[m - (j + 1)]
- 右移m - (j + 1)长度,前后缀将对齐,可以重新开始匹配
- 对于P[m - (j + 1)]左侧的所有字符P[i],右移m - (j + 1)长度就有可能匹配
- gs[i]可取m - (j + 1)
- ss[j] = j + 1,P.substring(0, j + 1)既是前缀,也是后缀
- 对于在P内部出现的P.substring(m - (j + 1), m)
- ss[j] < j + 1,P.substring(j + 1 - ss[j], j + 1)是中段的后缀内容
- 这表明P.substring(j + 1 - ss[j], j + 1)的前一个字符就有可能匹配T的对应字符
- 右移m - (j + 1)长度,公共部分将对齐,且公共部分前一个字符不同,可以重新开始匹配
- gs[m - (ss[j] + 1)] = m - (j + 1)
- ss[j] < j + 1,P.substring(j + 1 - ss[j], j + 1)是中段的后缀内容
- 从左向右遍历,让更小的步长覆盖更大的步长
void gsInit() {
for (int j = 0; j < m; j++) {
gs[j] = m;
}
for(int j = 0; j < m - 1; j++){
// j == m - 1时,gs[m - 1]为第一个字符即失配情形,直接移动m步
if (ss[j] == j + 1) {
for (int i = 0; i < m - (j + 1); i++) {
gs[i] = m - (j + 1);
}
}
else {
gs[m - (ss[j] + 1)] = m - (j + 1);
}
}
}性能分析
- 时间复杂度
- 预处理:BC表建表时间和GS表建表时间均正比于规模 O(sizeof(alphabet) + m)
- 最好情况:O(n / m)
- 最差情况:O(n + m)
-
空间复杂度
-
BC表和GS表分别需要额外空间O(sizeof(alphabet))和O(m)
-
匹配算法性能比较
Pr:Pairing rate,单次匹配率
- 与字符表规模成反比
- 单次匹配率越高,表明字符重合度越高,越难推进,时间复杂度一般越高
- KMP无论Pr如何,始终为O(n + m)
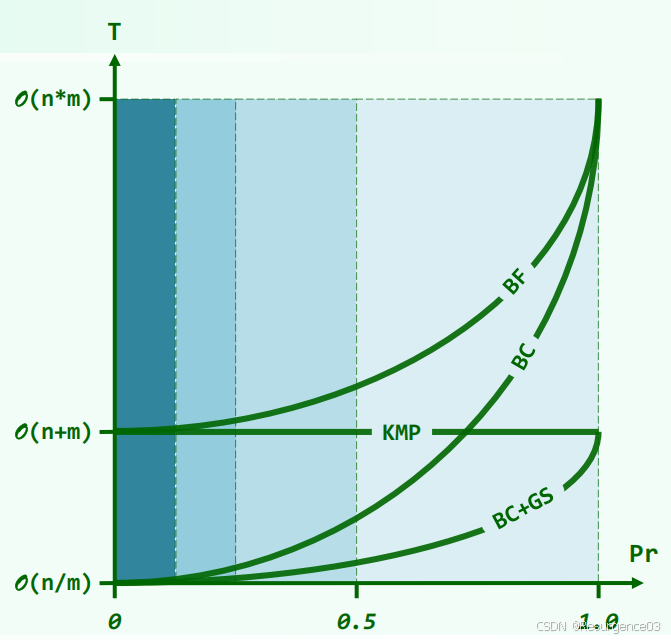
- KMP与BC的交点大于0.5
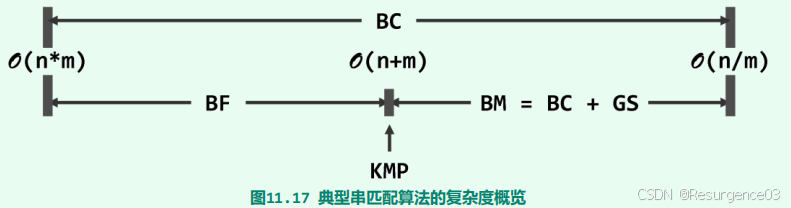


- Pr大
- KMP算法稳定线性O(n + m)
- Pr小
- 含BC机制的BM算法达到上限O(n / m)

















 1204
1204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









