




一些网络设备,比如防火墙或者审计系统,一般都有文件过滤的功能,可以对用户上网传输的文件进行过滤,比如可以限制用户通过ftp下载word文档,也就是文件类型为doc或者docx的文件。
那么文件过滤的功能是怎么实现呢?这里说一下大概的实现思路。
1、文件识别理论基础
首先,用户上网传输文件一般大都是经过传输层的tcp协议,了解tcp协议的同学应该知道,tcp报文一般不分片,而是使用分段,那么一个文件一般都很大,所以一个tcp分段报文是传输不完的,那么一个文件必然就会存在很多tcp分段报文中,所以在进行文件识别和过滤之前,需要先将文件的内容正确的还原出来,所以第一步涉及到tcp分段的重组,当然今天重点只是讲文件识别和过滤,tcp分段重组下次再单独讲。完成tcp分段重组,重组文件内容之后,我们需要先识别文件的类型,那么如何识别文件的类型呢?
这里我们还要注意一点,文件扩展名并不等同于文件类型,比如一个文件名为aaa.txt的文件,它的文件扩展名为txt,文件类型也为txt,但是如果我把文件名改完aaa.exe,那它的文件扩展名就变成了exe,但实际文件类型还是为txt,所以两者并不等同。我们在做文件过滤时,不是以文件扩展名来限制的,而是以文件类型。因为用户可以通过修改文件扩展名来逃避文件过滤检查。
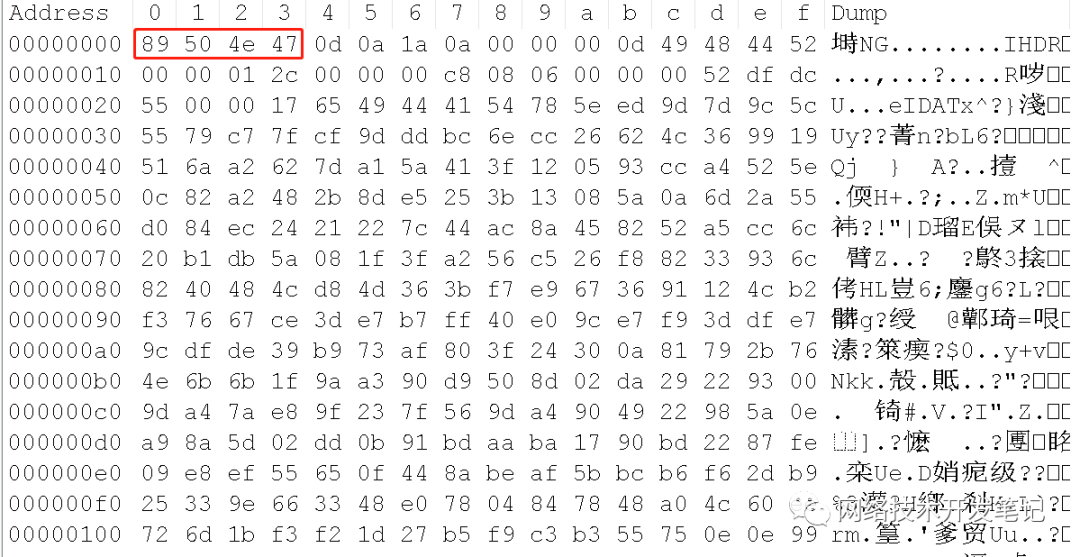
那么我们到底怎么来识别一个文件的类型呢?其实就是通过文件的魔数,也叫file magic,也就是每个文件都带有自己的特征,这个特征我们直接用对应软件打开看不到,但是windows通过Notepad++(安装HEX-Editor插件)或者linux通过hexdump工具查看文件的二进制数就可以看到。比如我们通过Nodepad++查看一个PNG文件:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 197
197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









