




 本文介绍了多种提升代码性能的方法,包括慎用异常处理、使用局部变量、利用位运算代替乘除法、一维数组代替二维数组等。这些技巧有助于开发者在实际编程中优化程序效率。
本文介绍了多种提升代码性能的方法,包括慎用异常处理、使用局部变量、利用位运算代替乘除法、一维数组代替二维数组等。这些技巧有助于开发者在实际编程中优化程序效率。
慎用异常
经常使用的try-catch捕获异常对系统性能而言是非常糟糕的。
虽然在一次try-catch中,无法察觉到它对性能带来的损失。但一旦把try-catch放在循环当中,就会给系统性能带来极大的伤害。
//try-catch在循环内,这段代码耗时110ms
int a=0;
for(int i=0;i<100000000;i++){
try{
a++;
} catch(Exception e) {}
}
//如果把try-catch移到循环体外,就能提升系统性能
//这段代码执行耗时62ms
int a=0;
try{
for(int i=0;i<100000000;i++){
a++;
}
} catch(Exception e){}尽量使用局部变量而不是类的成员变量
调用方法时,传递的参数以及在调用中创建的临时变量都保存在栈中,速度较快。其他变量,如静态变量,实例变量等,都在堆中创建,速度比较慢。
//使用局部变量进行计算
int a=0; //在函数体内定义的局部变量
for(int i=0;i<100000000;i++){
a++:
}//将局部变量替换成类的静态变量
public static int a=0; //在类中定义变量
for(int i=0;i<100000000;i++){
a++: //在函数体中调用
}第一段代码耗时78ms,第二段耗时266ms;
局部变量的访问速度远远高于类的成员变量;
位运算代替乘除法
在所有运算中,位运算是最高效的。
long a=100;
for(int i=0;i<100000000;i++){
a*=2;
a/=2;
}
for(int i=0;i<100000000;i++){
a<<=2; //*2
a>>=2;
}第一段代码耗时219ms,第二段耗时31ms,还是很明显的;
替换switch
switch类似于if-else,两者的性能也差不多。所以,不能说switch会降低性能,但还是能提升性能的方法的。


一维数组代替二维数组
数组的随机访问性能比较好,许多JDK库底层都是基于数组实现的。
一维数组的访问速度要优于二维数组。所以,可以通过算法将二维数组转为一维数组,再进行处理;
在集合访问或数组访问的时候,应该尽量减少方法调用;
提取表达式
提取重复的代码,尽可能减少重复的计算,尤其是在循环体内;
展开循环
展开循环会影响代码的可读性和可维护性,但在极端情况下,为了提高系统性能,可以考虑循环展开;
//耗时94ms
int[] array = new int[9999999];
for(int i=0;i<9999999;i++){
array[i] = i;
}
//展开循环,减少循环次数,提升系统性能
//耗时31ms
int[] array = new int[9999999];
for(int i=0;i<9999999;i+=3){
array[i] = i;
array[i+1] = i;
array[i+2] = i;
}布尔运算代替位运算
虽然位运算的速度远远高于算术运算,但是在条件判断的时候,使用位运算替代布尔运算是非常错误的。
在条件判断的时候,Java会对布尔运算进行充分的优化。即,a&b&c&d,只有一个是false,剩下的就不计算了,直接返回false。即,只有表达式的值能够确定,剩余的余子表达式就不计算了。
如果使用位运算的话,位运算本身没什么性能问题,但位运算总是将所有的子表达式计算完之后才返回。
使用arraycopy()
数组复制应该使用System.arraycopy()函数,而不是自己实现的。
System.arraycopy()函数是native函数,通常native函数的性能要优于普通的函数。应该尽量调用native函数。
使用Buffer进行I/O操作
在进行I/O操作时,有个尽可能选择带缓冲的类;
详细的,可以查阅资料;
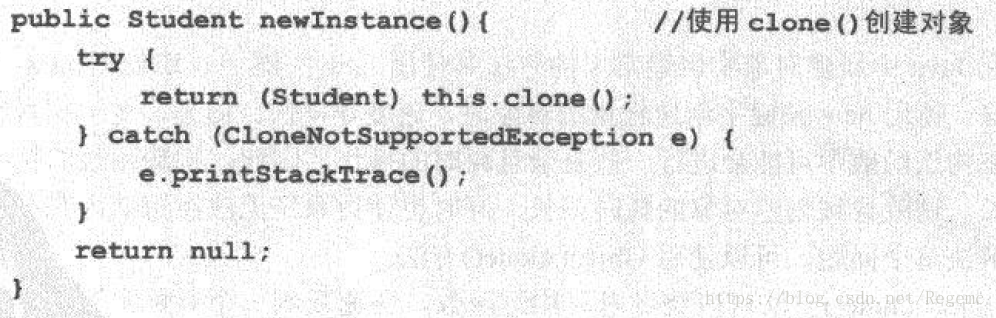
使用clone()代替new
新建对象通常用new。使用new创建轻量级对象,速度非常快。对于重量级对象,由于对象在构造函数中可能会进行一些复杂且耗时的操作,所以速度会比较慢。
Object.clone()可以绕过构造函数,快速复制一个对象实例。
但,在默认情况下,clone()方法生成的实例只是原对象的浅拷贝。如果需要深拷贝,则需要重新实现clone()方法。
静态方法替代实例方法
实例方法需要维护一张类似于虚函数表的结构,以支持对多态的支持。与静态方法相比,实例方法的调用需要更多的资源。
所以,如果一些方法没有重载的必要(如,工具类),可以直接申明为静态方法,加速方法的调用。

















 766
766

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









