




一、深入类和对象
鸭子类型和多态
多态的概念是应用于Java和C#这一类强类型语言中,而Python崇尚“鸭子类型”
动态语言调用实例方法时不检查类型,只要方法存在,参数正确,就可以调用。这就是动态语言的“鸭子类型”,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
所谓多态:定义时的类型和运行时的类型是不一样,此时就称为多态。
抽象基类(abc模块)
抽象基类(abstract base class,ABC):抽象基类就是类里定义了纯虚成员函数的类。纯虚函数只提供了接口,并没有具体实现。抽象基类不能被实例化(不能创建对象),通常是作为基类供子类继承,子类中重写虚函数,实现具体的接口。
抽象基类就是定义各种方法而不做具体实现的类,任何继承自抽象基类的类必须实现这些方法,否则无法实例化。
应用场景:
(1)判断某个对象的类型;
class Demo(object):
def __init__(self,names):
self.names = names
# def __len__(self):
# return len(self.names)
def __iter__(self):
pass
def test(self):
pass
d = Demo(['juran', 'python'])
print(len(d))
print(hasattr(d, "test"))
from collections.abc import Sized,Iterable
print(isinstance('demo', int))
print(isinstance(d, Iterable))
(2)我们需要强制某个子类必须实现某些方法
import abc
class CacheBase(metaclass=abc.ABCMeta):
@abc.abstractmethod
def get(self, key):
# raise ValueError
pass
# self.key = key
@abc.abstractmethod
def set(self, key, value):
# raise NotImplementedError
pass
class RedisBase(CacheBase):
# 重写父类中的方法
# def get(self, key):
# pass
def set(self, key, value):
pass
r = RedisBase()
# r.get('juran')
使用isinstance和type的区别:
i=1
s='a'
isinstance(i,int)
isinstance(s,str)
isinstance(s,int)
print(type(i))
if isinstance(i, int):
# if type(i) == 'int':
print(123)
class A:
pass
class B(A):
pass
b = B()
print(isinstance(b, B))
print(isinstance(b, A)) # True 考虑类的继承关系
print(type(b) is B)
print(type(b) is A) # False 没有考虑类的继承关系
# == value
# 和 is 内存地址
# 区别
类变量和实例变量:
class A:
# 类属性
aa = 1
# 实例方法
def __init__(self, x, y):
# 实例属性
self.x = x
self.y = y
# self.aa = 22
a = A(1, 2)
# print(a.x, a.y, a.aa) # 向上查找
# print(A.x) # 向下查找
A.aa = 11
a.aa = 22
print(a.aa) # 22
print(A.aa) # 11
b = A(1, 2)
print(b.aa) # 11
类属性和实例属性以及查找顺序
MRO算

Python2.2之前的算法:金典类
DFS(deep first search):A->B->D->C->E

Python2.2版本之后,引入了BFS(广度优先搜索)
BFS:A->B->C->D
在Python2.3之后,Python采用了C3算法
Python新式类继承的C3算法:链接: link
**'''
class D(object):
pass
class B(D):
pass
class C(D):
pass
class A(B, C):
pass
print(A.__mro__)
'''
class D:
pass
class B(D):
pass
class E:
pass
class C(E):
pass
class A(B, C):
pass
# A,B,D,C,E
print(A.__mro__)**
Python对象的自省机制
自省是通过一定的机制查询到对象的内部结构
Python中比较常见的自省(introspection)机制(函数用法)有: dir(),type(), hasattr(), isinstance(),通过这些函数,我们能够在程序运行时得知对象的类型,判断对象是否存在某个属性,访问对象的属性。
class Person(object):
name = 'jingang'
class Student(Person):
def __init__(self, school_name):
self.school_name = school_name
user = Student('教育')
# print(user.__dict__)
# print(dir(user))
# print(user.name)
# list()
a = [1, 2]
print(a.__dict__)
# print(dir(a))
# print(list.__dict__)
super函数
在类的继承中,如果重定义某个方法,该方法会覆盖父类的同名方法,但有时,我们希望能同时实现父类的功能,这时,我们就需要调用父类的方法了,可通过使用 super 来实现。
# class A:
# def __init__(self):
# print("A")
#
#
# class B(A):
# def __init__(self):
# print("B")
# # python2的写法
# # super(B, self).__init__()
# super().__init__()
# 重写了B的构造函数 为什么还要去调用super
# b = B()
class People(object):
def __init__(self, name, age, weight):
self.name = name
self.age = age
self.weight = weight
def speak(self):
print("%s 说:我%d岁了"%(self.name, self.age))
class Student(People):
def __init__(self,name, age, weight, grade):
# self.name = name
# self.age = age
# self.weight = weight
# super().__init__(name ,age, weight)
People.__init__(self, name, age, weight)
self.grade = grade
def speak(self):
print("%s 说:我%d岁了 我在读%d年级"%(self.name, self.age, self.grade))
s = Student('lg', 18, 30, 3)
# s.speak()
# super 执行顺序到底是什么样的?
class A:
def __init__(self):
print("A")
class B(A):
def __init__(self):
print("B")
super().__init__()
class C(A):
def __init__(self):
print("C")
super().__init__()
class E:
pass
class D(B, C):
def __init__(self):
print("D")
super().__init__()
d = D()
print(D.__mro__) # D B C A
# super 调用父类中的方法
# 而是按照 mro 算法来调用的
二、类与对象深度问题与解决技巧
1、如何派生内置不可变类型并修改其实例化行为
我们想自定义一种新类型的元组,对于传入的可迭代对象,我们只保留其中int类型且值大于0的元素,例如:
IntTuple([2,-2,'jr',['x','y'],4]) => (2,4)
# self对象到底是谁创建的呢?
#self是通过__new__创建的,当__new__没有返回值时,__init__方法(是在产生类对象之后的实例化)不能执行
class A(object):
def __new__(cls, *args, **kwargs):
print("A.__new___", cls, args)
return object.__new__(cls) #建议返回值写object
# return super().__new__(cls)
def __init__(self, *args):
print("A.__init__")
a = A(1, 2)#等同于下面两行代码
a = A.__new__(A, 1, 2)
A.__init__(a, 1, 2)
如何继承内置tuple 实现IntTuple
class IntTuple(tuple):
def __new__(cls, iterable):
# for i in iterable:
# if isinstance(i, int) and i > 0:
# super().__init__(i)
# 生成器
# f = (i for i in iterable if isinstance(i, int) and i > 0)
f = [i for i in iterable if isinstance(i, int) and i > 0]
print(f)
# 硬编码,此时cls就是IntTuple,但是return中不能用IntTuple,目的是为了避免硬编码
return super().__new__(cls, f)
int_t = IntTuple([2, -2, 'jr', ['x', 'y'], 4])
print(int_t) # (2, 4)
2、如何为创建大量实例节省内存
在游戏中,定义了玩家类player,每有一个在线玩家,在服务器内则有一个player的实例,当在线人数很多时,将产生大量实例(百万级)
如何降低这些大量实例的内存开销?
解决方案:
定义类的__slots__属性,声明实例有哪些属性(关闭动态绑定)
import tracemalloc # 跟踪内存的使用
class Player1(object):
def __init__(self, uid, name, status=0, level=1):
self.uid = uid
self.name = name
self.status = status
self.level = level
class Player2(object):
__slots__ = ('uid', 'name', 'status', 'level')#关闭__dict__动态绑定属性功能
def __init__(self, uid, name, status=0, level=1):
self.uid = uid
self.name = name
self.status = status
self.level = level
# p1 = Player1('0001', 'juran')
# p2 = Player2('0002', 'juran')
# print(dir(p1))
# print(len(dir(p1))) # 30
# print(dir(p2))
# print(len(dir(p2))) # 29
# __weakref__ 弱引用
# __dict__ 动态绑定属性,及其浪费内存
# print(set(dir(p1)) - set(dir(p2)))
# p1.x = 6
# p1.__dict__['y'] = 7
# print(p1.__dict__)
# 有了__slots__之后就可以把动态绑定属性关掉,也就是执行p2.x = 6时,会报错。
# print(p2.name)
# # __dict__ 动态绑定属性会占用多少属性呢?
# print(sys.getsizeof(p1.__dict__))#112,getsizeof查看对象占用的内存,内存分析的化要用tracemalloc
# print(sys.getsizeof(p1.name))#54
# print(sys.getsizeof(p1.uid))#53
tracemalloc.start()
p1 = [Player1(1, 2, 3) for _ in range(100000)] #这个地方的下划线(_)表示循环的值不需要,只需要循环的次数 # 16.8 MiB
p2 = [Player2(1, 2, 3) for _ in range(100000)] # 7837 KiB
end = tracemalloc.take_snapshot()
top = end.statistics('lineno')
# top = end.statistics('filename')
for stat in top[:10]:
print(stat)
3、Python中的with语句:自动地释放资源
上下文管理器协议
contextlib简化上下文管理器
# 上下文管理器
class Sample(object):
# 获取资源
def __enter__(self):
print('start')
return self
def demo(self):
print('this is demo')
# 释放资源 Traceback
def __exit__(self, exc_type, exc_val, exc_tb):
# <class 'AttributeError'> 异常类
print(exc_type, '-')
# 'Sample' object has no attribute 'dems' 异常值
print(exc_val, '-')
# <traceback object at 0x000002D58D8D0A48> 追踪信息
print(exc_tb, '-')
print('end')
# 要想类能用with语句,类中需要有__enter__和__exit__两种方法,这样写也是比较麻烦的
# with Sample() as sample:
# sample.dems()
import contextlib # 简化上下文管理器
@contextlib.contextmanager
def file_open(filename):
# xxx __enter__ 函数
print('file open')
yield {} #生成器
#yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yield后面(右边)的值。
# 重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码(下一行)开始执行。
# return 的作用:如果没有 return,则默认执行至函数完毕,遇到return程序结束。
# __exit__ 函数
print('file close')
with file_open('demo.txt') as f:
print('file operation')
4、如何创建可管理的对象属性
在面向对象编程中,我们把方法看做对象的接口。直接访问对象的属性可能是不安全的,或设计上不够灵活,但是使用调用方法在形式上不如访问属性简洁。
'''
麻烦
A.get_key() # 访问器
A.set_key() # 设置器
A.key
A.key = 'jr'
形式上 属性访问
实际上 调用方法
'''
class A:
def __init__(self, age):
self.age = age
def get_age(self):
return self.age
def set_age(self, age):
if not isinstance(age, int):
raise TypeError('Type Error')
self.age = age
#实现方式一:直接调用Property函数
# property(fget=None, fset=None, fdel=None, doc=None) -> property attribute
R = property(get_age, set_age)
#实现方式二:装饰器方式
@property # @property相当于get方法
def S(self):
return self.age
@S.setter # @S.setter相当于set方法
def S(self, age):
if not isinstance(age, int):
raise TypeError('Type Error')
self.age = age
a = A(18)
# 文件读取的 str
# a.age = '20'
# print(type(a.age))
# a.set_age('20')
# print(a.get_age())
# a.R = 20 #相当于调用set_age方法
# print(a.R)#相当于调用get_age方法
print(a.S)
a.S = 22
5、如何让类支持比较操作
有时我们希望自定义类的实例间可以使用,<,<=,>,>=,==,!=符号进行比较,我们自定义比较的行业,例如,有一个矩形的类,比较两个矩形的实例时,比较的是他们的面积
from functools import total_ordering
import math
import abc #抽象基类
@total_ordering
class Shape(metaclass=abc.ABCMeta):
@abc.abstractmethod #抽象基类中的第二种应用场景:我们需要强制某个子类必须实现某些方法
def area(self):
pass
def __lt__(self, other):
return self.area() < other.area()
def __eq__(self, other):
return self.area() == other.area()
class Rect(Shape):
def __init__(self, w, h):
self.w = w
self.h = h
def area(self):
return self.w * self.h
# def __lt__(self, other):
# return self.area() < other.area()
#
# def __eq__(self, other):
# return self.area() == other.area()
# rect1 = Rect(1, 2)
# rect2 = Rect(1, 2)
# print(Rect(1, 2) > Rect(1, 2)) # rect2 < rect1
class Cirle(Shape):
def __init__(self, r):
self.r = r
def area(self):
return self.r ** 2*math.pi
# def __lt__(self, other):
# return self.area() < other.area()
#
# def __eq__(self, other):
# return self.area() == other.area()
c = Cirle(8)
rect = Rect(1, 2)
print(c == rect)
6、如何在环状数据结构中管理内存
双向循环链表
弱引用:不占用引用计数。
import weakref
class Node:
def __init__(self, data):
self.data = data
self.left = None
self.right = None
def add_right(self, node):
self.right = node
# node.left = self
node.left = weakref.ref(self)
def __str__(self):
return 'Node:<%s>' % self.data
def __del__(self):
print('in __del__: delete %s' % self)
def create_linklist(n):
head = current = Node(1)
for i in range(2, n + 1):
node = Node(i)
current.add_right(node)
current = node
return head
head = create_linklist(1000)
head = None
import time
for _ in range(1000):
time.sleep(1)
print('run...')
input('wait...')
7、通过实例方法名字的字符串调用方法
我们有三个图形类
Circle,Triangle,Rectangle
他们都有一个获取图形面积的方法,但是方法名字不同,我们可以实现一个统一的获取面积的函数,使用每种方法名进行尝试,调用相应类的接口
class Triangle:
def __init__(self,a,b,c):
self.a,self.b,self.c = a,b,c
def get_area(self):
a,b,c = self.a,self.b,self.c
p = (a+b+c)/2
return (p * (p-a)*(p-b)*(p-c)) ** 0.5
class Rectangle:
def __init__(self,a,b):
self.a,self.b = a,b
def getArea(self):
return self.a * self.b
class Circle:
def __init__(self,r):
self.r = r
def area(self):
return self.r ** 2 * 3.14159
shape1 = Triangle(3, 4, 5)
shape2 = Rectangle(4, 6)
shape3 = Circle(1)
def get_area(shape):
method_name = ['get_area', 'getArea', 'area']
for name in method_name:
f = getattr(shape, name, None) #getattr(x, 'y') is equivalent to x.y,当x中不存在‘y’时,返回None,而不是报错。
if f:
return f()
# map 函数
# print(get_area(shape1))
# print(get_area(shape2))
# print(get_area(shape3))
shape_list = [shape1, shape2, shape3]
area_list = list(map(get_area, shape_list))
print(area_list)
三、Python 垃圾回收机制
1、Python 垃圾回收机制
计数引用我们反复提过好几次, Python 中一切皆对象。因此,你所看到的一切变量,本质上都是对象的一个指针。
那么,怎么知道一个对象,是否永远都不能被调用了呢?
就是当这个对象的引用计数(指针数)为 0 的时候,说明这个对象永不可达,自然它也就成为了垃圾,需要被回收。
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial') # 8.4921875M
# 局部变量
a = [i for i in range(10000000)]
show_memory_info('after a created') # 396.41796875 MB
func()
show_memory_info('finished') # 9.2734375 MB
2、循环引用
如果有两个对象,它们互相引用,并且不再被别的对象所引用,那么它们应该被垃圾回收吗?
'''
引用计数
'''
import sys
import gc
# 清除没有引用的对象
# gc.collect()#循环引用
a = []
# 2 查看变量的引用次数 本身也要算一次
# print(sys.getrefcount(a)) # 2,引用计数
def func(a):
# 1 a = []
# 2 函数调用
# 3 函数的参数
# 4 getrefcount
print(sys.getrefcount(a)) # 4
func(a)
# b = a
# print(sys.getrefcount(a)) # 3次
# 引用次数为0 是垃圾回收启动的充分必要条件嘛?充分不必要,例子如下:
import os
import psutil
# 显示当前 python 程序占用的内存大小
def show_memory_info(hint):
pid = os.getpid()
p = psutil.Process(pid)
info = p.memory_full_info()
memory = info.uss / 1024. / 1024
print('{} memory used: {} MB'.format(hint, memory))
def func():
show_memory_info('initial')# 8.546875 MB
a = [i for i in range(10000000)]
b = [i for i in range(10000000)]
show_memory_info('after a, b created')#783.8046875 MB
a.append(b)
b.append(a)
func()
show_memory_info('finished') #783.8046875 MB
3、调试内存泄漏
虽然有了自动回收机制,但这也不是万能的,难免还是会有漏网之鱼。内存泄漏是我们不想见到的,而且还会严重影响性能。有没有什么好的调试手段呢?
它就是 objgraph,一个非常好用的可视化引用关系的包。在这个包中,我主要推荐两个函数,第一个是 show_refs(),它可以生成清晰的引用关系图。
import objgraph
a = [1, 2, 3]
b = [4, 5, 6]
a.append(b)
b.append(a)
objgraph.show_refs([a])
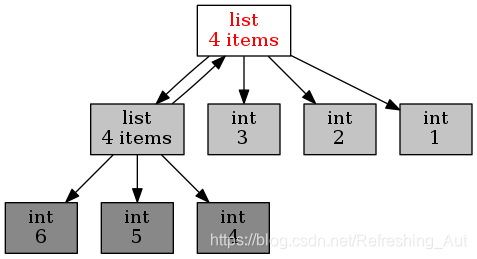
dot转图片链接: link.
4、总结
垃圾回收是 Python 自带的机制,用于自动释放不会再用到的内存空间;
引用计数是其中最简单的实现,不过切记,这只是充分非必要条件,因为循环引用需要通过不可达判定,来确定是否可以回收;
Python 的自动回收算法包括标记清除和分代收集,主要针对的是循环引用的垃圾收集;
调试内存泄漏方面, objgraph 是很好的可视化分析工具。
四、代码调试和性能分析
1、调试和性能分析
用 pdb 进行代码调试
首先,我们来看代码的调试。也许不少人会有疑问:代码调试?说白了不就是在程序中使用 print() 语句吗?
没错,在程序中相应的地方打印,的确是调试程序的一个常用手段,但这只适用于小型程序。因为你每次都得重新运行整个程序,或是一个完整的功能模块,才能看到打印出来的变量值。如果程序不大,每次运行都非常快,那么使用 print(),的确是很方便的。
可能又有人会说,现在很多的 IDE 不都有内置的 debug 工具吗?但是在大型项目中,可能有混合代码,不同的语言之间的调试,这时就可以借用pdb进行调试。
如何使用 pdb
首先,要启动 pdb 调试,我们只需要在程序中,加入import pdb和pdb.set_trace()这两行代码就行了
a = 1
b = 2
import pdb
pdb.set_trace()
c = 3
print(a + b + c)
这时,我们就可以执行,在 IDE 断点调试器中可以执行的一切操作,比如打印,语法是"p ":
(pdb) p a
1
(pdb) p b
2
除了打印,常见的操作还有“n”,表示继续执行代码到下一行
(pdb) n
-> print(a + b + c)
而命令l,则表示列举出当前代码行上下的 11 行源代码,方便开发者熟悉当前断点周围的代码状态
(pdb) l
1 a = 1
2 b = 2
3 import pdb
4 pdb.set_trace()
5 -> c = 3
6 print(a + b + c)
命令“s“,就是 step into 的意思,即进入相对应的代码内部。
import pdb
a = 1
b = 2
def func():
print('enter func()')
pdb.set_trace() # 可以在调试中 用p a 来打印a,用n继续往后执行,用l显示未执行的代码,用s进入函数体内部。
c = 3
func()
print(a + b + c)
当然,除了这些常用命令,还有许多其他的命令可以使用
参考对应的官方文档链接: link
2、用 cProfile 进行性能分析
事实上,除了要对程序进行调试,性能分析也是每个开发者的必备技能。
日常工作中,我们常常会遇到这样的问题:在线上,我发现产品的某个功能模块效率低下,延迟高,占用的资源多,但却不知道是哪里出了问题。
这时,对代码进行 profile 就显得异常重要了。
这里所谓的 profile,是指对代码的每个部分进行动态的分析,比如准确计算出每个模块消耗的时间等。
计算斐波拉契数列,运用递归思想
import cProfile
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def fib_seq(n):
res = []
if n > 0:
res.extend(fib_seq(n-1))
res.append(fib(n))
return res
# print(fib_seq(30))
cProfile.run('fib_seq(30)')

参数介绍:
(1)ncalls,是指相应代码 / 函数被调用的次数
(2)tottime,是指对应代码 / 函数总共执行所需要的时间(注意,并不包括它调用的其他代码 / 函数的执行时间)
(3)tottime percall,就是上述两者相除的结果,也就是tottime / ncalls
(4)cumtime,则是指对应代码 / 函数总共执行所需要的时间,这里包括了它调用的其他代码 / 函数的执行时间
(5)cumtime percall,则是 cumtime 和 ncalls 相除的平均结果。
五、经典的参数错误
def add(a, b):
a += b
# a = a + b
return a
a = 1
b = 2
c = add(a, b)
print(c) # 3
print(a, b) # 1 2
a = [1, 2]
b = [3, 4]
c = add(a, b)
print(c) # [1 2 3 4]
print(a, b) # a = [1 2 3 4] b = [3 4]
a = (1, 2)
b = (3, 4)
c = add(a, b)
print(c) # (1 2 3 4)
print(a, b) # (1 2) (3 4)
# 可变 不可变:对于不可变类型的数据重新赋值的话,相当于重新创建了一个数据,id发生了改变。
# 数据结构 列表:列表的创建是在__init__方法中的, 元组:元组的创建在__new__方法中
不可变类型
以int类型为例:实际上 i += 1 并不是真的在原有的int对象上+1,而是重新创建一个value为6的int对象,i引用自这个新的对象。
可变类型
以list为例。list在append之后,还是指向同个内存地址,因为list是可变类型,可以在原处修改。
六、元类编程
1、__getattr__和__getattribute__魔法函数
from datetime import date
class User:
def __init__(self, name, birthday, info={}):
self.name = name
self.birthday = birthday
self.info = info
# 在查找不到属性的时候调用
def __getattr__(self, item):
# print(item, 'attribute not find')
# print(item)
# return 'attribute not find'
# pass
# return self.info[item]
return self.info.get(item)
# __getattribute__ 在__getattr__之前执行
# def __getattribute__(self, item):
# return "juran"
# def demo(): pass
# print(demo())
if __name__ == '__main__':
# 1990-1-1
user = User('juran', date(year=1990, month=1, day=1), info={"age": 18})
# print(user.name)
print(user.birthday)
2、属性描述符
class User(object):
def __init__(self, age, name):
self.age = age
self.name = name
def get_age(self):
return self.age
def set_age(self, age):
if not isinstance(age, int):
raise TypeError('type error')
self.age = age
如果User类中有多个属性都需要判断,那么就需要写多个方法,这些方法怎么复用呢?这个时候就要用到属性描述符
属性描述符,只要实现了__get__,set,__delete__任何一个方法,就被称为属性描述符
# 属性描述符 __get__ __set__ __delete__
# Django
class IntField(object):
"""
数据描述符
"""
def __get__(self, instance, owner):
print("__get__")
# print(instance)
return self.values
def __set__(self, instance, value):
print("__set__")
# print(instance)
# print(value)
if not isinstance(value, int):
raise ValueError('Value Error')
self.values = value
def __delete__(self, instance):
pass
class NoneDataIntField:
"""
非数据描述符
"""
def __get__(self, instance, owner):
pass
class User:
age = IntField()
# age = 19
user = User()
user.age = 30
user.__dict__['age'] = 18
print(user.age)
属性查找顺序:属性描述符的优先级是最高的
user = User(), 那么user.age 顺序如下:
1 如果"age"是出现在User或其基类的__dict__中, 且age是data descriptor,那么调用其__get__方法, 否则
2 如果"age"出现在user的__dict__中, 那么直接返回 obj.__dict__['age'],否则
3 如果"age"出现在User或其基类的__dict__中
3.1 如果age是non-data descriptor,那么调用其__get__方法, 否则
3.2 返回 __dict__['age']
4 如果User有__getattr__方法,调用__getattr__方法,否则
5 抛出AttributeError
3、自定义元类
动态创建类
def create_class(name):
if name == 'user':
class User(object):
def __str__(self):#打印的时候被调用
return "user"
return User
elif name == 'student':
class Student:
def __str__(self):
return "student"
return Student
if __name__ == '__main__':
myclass = create_class('user')
obj = myclass()
print(obj)
# 查看数据类型 创建类
print(type(obj))
4、使用type创建类
type还可以动态的创建类,type(类名,由父类组成的元组,包含属性的字典)
'''
type(name, bases, dict) -> a new type
'''
# User = type("User", (), {})
# obj = User()
# print(obj)
# 添加属性
# User = type("User", (), {'name': 'juran'})
# obj = User()
# print(obj)
# print(obj.name)
# 添加一个方法
def demo(self):
return self.name
def get_age(self):
self.age = 18
return self.age
# def __init__(self):#尽量不用调用魔法方法
# self.sex = 1
User = type("User", (), {'name': 'juran', "info": demo, "age": get_age})
obj = User()
# print(obj.name)
# print(obj)
class BaseClass(object):
def test(self):
return "base class"
def __str__(self):
return "this is test"
class BaseClass1(object):
def test1(self):
return "base class1"
# b = BaseClass1()
# print(b)
User = type("User", (BaseClass, BaseClass1), {'name': 'juran'})
user = User()
print(user)
print(user.test1())
5、metaclass属性
如果一个类中定义了metalass = xxx,Python就会用元类的方式来创建类
'''
def upper_attr(class_name, class_parents, class_attr):
# print(class_name)
# print(class_parents)
# print(class_attr)
newattr = {}
for name, value in class_attr.items():
# print(name)
# print(value)
if not name.startswith("_"):
newattr[name.upper()] = value
return type(class_name, class_parents, newattr)
class Foo(object, metaclass=upper_attr):
# __metaclass__ = upper_attr
name = 'juran'
f = Foo()
print(hasattr(Foo, 'name'))
print(hasattr(Foo, 'NAME'))
# print(f.NAME)
# print(f.name)
'''
# 类的实例化 首先寻找metaclass
class Demo(object):
def __new__(cls, *args, **kwargs):
pass
class MetaClass(type): #metaclass是继承type
def __new__(cls, *args, **kwargs):
pass
class User(Demo, metaclass=MetaClass):#metaclass是优先执行的,在此处Demo并未被执行
pass
obj = User()
七、迭代器和生成器
1、迭代器
在介绍迭代器之前,先说明下迭代的概念:
迭代:通过for循环遍历对象的每一个元素的过程。
Python的for语法功能非常强大,可以遍历任何可迭代的对象。
在Python中,list/tuple/string/dict/set/bytes都是可以迭代的数据类型。
迭代器是什么?
迭代器是一种可以被遍历的对象,并且能作用于next()函数。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。 迭代器只能往后遍历不能回溯,不像列表,你随时可以取后面的数据,也可以返回头取前面的数据。
from collections.abc import Iterator, Iterable
# print(isinstance(list(), Iterable)) # True
# print(isinstance(list(), Iterator)) # False
# 迭代器的实现通常使用两个方法:iter next(取迭代器了里面的元素)
l = [1, 2, 3, 4]
it = iter(l)
# print(it)
# print(next(it))
# print(next(it))
# print(next(it))
print(next(it), '-')
for i in it:
print(i)
2、生成器
有时候,序列或集合内的元素的个数非常巨大,如果全制造出来并放入内存,对计算机的压力是非常大的
生成器生成的两种方式:
(1)(x for x in range(10))
(2)yield关键字
# g = (x for x in range(10))
# print(g)
# print(next(g))
# print(next(g))
# print(next(g))
# print(next(g))
# print(next(g))
# for i in g:
# print(i)
# 0 1 2 3 5 8 a, b = b, a+b
def fibonacci():
print("--func start--")
a, b = 0, 1
for i in range(5):
# print(b)
print("--1--")
# 当函数中出现yield关键字的时候,这个函数就变成了一个生成器了
yield b #yield是返回值,每次运行到yield会停在此处,并返回值,后面再运行时,从yield位置开始运行
print("--2--")
a, b = b, a+b
print("--3--")
print("--func end--")
g = fibonacci()
print(next(g))
print(next(g))
print(next(g))
print(next(g))
print(next(g))
生成器如何读取大文件
文件300G,文件比较特殊,一行 分隔符 {|}
def readlines(f, newline):
buf = ""
while True:
while newline in buf:
# index 2
pos = buf.index(newline)
yield buf[:pos]
buf = buf[pos + len(newline):]
chunk = f.read(1024)
# 读到文件末尾
if not chunk:
yield buf
break
buf += chunk
# 2+3
'abc{|}123{|}456'
with open('demo.txt') as f:
for line in readlines(f, "{|}"):
print(line)

















 661
661

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









