




 本文介绍Python中正则表达式的使用方法,包括基本匹配、分组匹配及高级应用如search、findall等函数的使用,并讲解了贪婪与非贪婪模式的区别。
本文介绍Python中正则表达式的使用方法,包括基本匹配、分组匹配及高级应用如search、findall等函数的使用,并讲解了贪婪与非贪婪模式的区别。
python 正则表达式
- 正则表达式 : 是一种特殊的字符序列,专门用于匹配符合符合条件的字符串 [ Regular Expression]
- 正则的作用 : 用于验证 、筛选提取内容
- python 中使用的模块: re
- re模块的基本使用
import re # 导入re模
result = re.match(正则表达式, 要匹配的字符串) # 使用match() 方法进行匹配操作
result.group( ) # 使用group()方法提取数据
1.正则的基本匹配
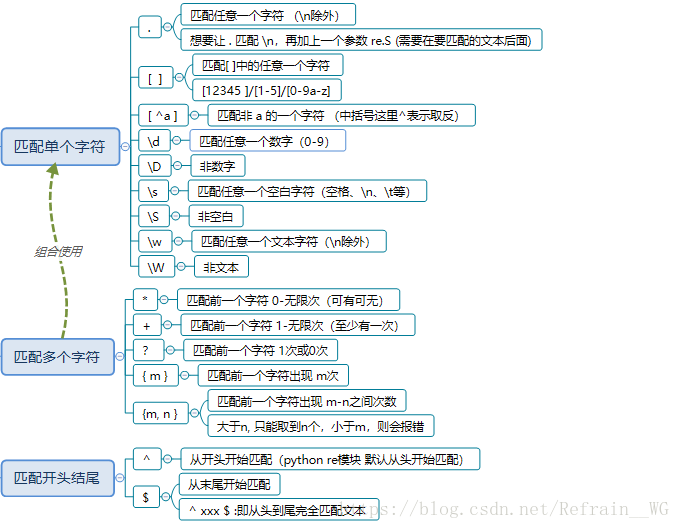
案例 :
# 匹配变量名是否符合标识符命名规则
res = re.match("[a-zA-Z_]+[\w]*","name_123")
print(res.group()) # 运行结果 : name_123res = re.match("[a-zA-Z_]+[\w]*","name_123")
print(res.group()) # 运行结果 : name_123
# 匹配字符串的开头和结尾 (注意: python中match 默认从头开始匹配,可以省略^)
res = re.match("[\w]{4,20}@gmail\.com$", "refrain_WG@gmail.com")
print(res.group()) # 运行结果: refrain_WG@g'mail.comres = re.match("[\w]{4,20}@gmail\.com$", "refrain_WG@gmail.com")
print(res.group()) # 运行结果: refrain_WG@g'mail.com
2.正则的分组匹配

案例 :
# | 的使用: 或
res = re.match("[1-9]?\d$|100","6")
print(res.group()) # 运行结果 : 6
# ( ) 的使用: 分组
res = re.match("\w{4,20}@(163|qq|gmail)\.com", "abc123@gmail.com")
print(res.group()) # 运行结果 : abc123@gmail.com
# \ 的使用: 这里 \1 代表引用分组1的正则表达式
res = re.match(r"<([a-zA-Z]*)>\w*</\1>", "<html>引用分组</html>")
print(res.group()) # 运行结果: <html>引用分组</html> # 运行结果: <html>引用分组</html>
3.正则的高级使用
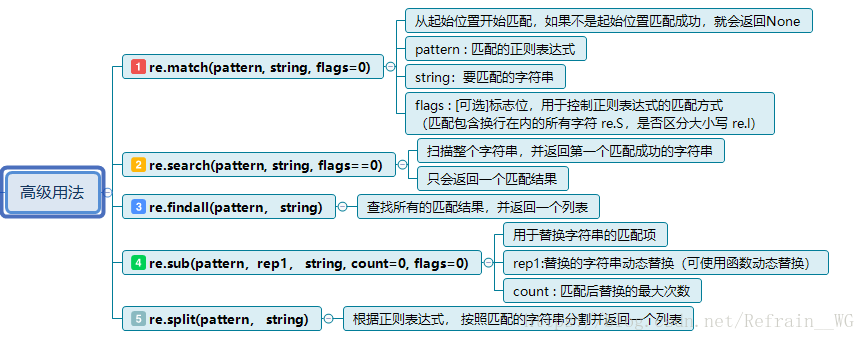
案例:
- search( ) : 匹配整个字符串,返回第一个符合正则表达式的字符串结果.
res = re.search(r"\d+", "随机数123-9999")
print(res.group()) # 运行结果为: 123
- findall( ) : 匹配整个字符串, 查找所有符合正则表达式的匹配结果, 并返回一个列表.
res = re.findall(r"\d+", "随机数: 123, 007, 9999, 2018, 6, 16")
print(res) # 运行结果为 : ['123', '007', '9999', '2018', '6', '16'] # 运行结果为 : ['123', '007', '9999', '2018', '6', '16']
- sub( ) : 使用正则表达式匹配文本中要替换的数据, 然后替换.
res = re.sub(r"\d+", '20180616', "学号:1205071")
print(res) # 运行结果为: 学号:20180616
- split( ) : 根据正则表达式, 切割字符串并返回一个列表.
res = re.split(r"-| ","随机2018-06-16 2018-11-22文本")
print(res) # 运行结果为: ['随机2018', '06', '16', '2018', '11', '22文本']
注意 : findall( ) , sub( ) , split( ) 的使用,不需要使用group( ) 提取数据
4.贪婪 和 非贪婪
贪婪: Python里数量词默认是贪婪的,总是尝试匹配尽可能多的字符;
非贪婪 : 和贪婪相反,总是尝试匹配尽可能少的字符。
解决方案: 在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪。

THE END
Refrain_WG 2018.06.16

















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









