






目录
前情提要
最终代码在结尾
我这篇文章写的是旧岛(如下图)链接。不是新岛!
此文章以my sunset来演示
放心,后面会有从一个反推到全部的方法,别急
获取音频地址
搭建框架
我们用的是python requests库来爬取
所以我们先要搭建代码:
import requests
url = "https://box3.codemao.cn/m/1061259"
header = {
}
res = requests.post("https://box3.codemao.cn/api/api/content-server-rpc",data=payload_text,headers=header)
res.encoding = "utf-8"
print(res.text)
分析结构
使用开发者模式
我们先打开网页

再打开开发者模式,打开网络选项卡,刷洗一下:(也是非常的赏心悦目)
没事!我们有Fiddler!
使用Fiddler抓包
(这里就不教大家如何使用了,古人云:“知之为知之,不知百度知。”)
我们开启过滤,只过滤box3.codemao.cn
再刷新网页,Fiddler得到:
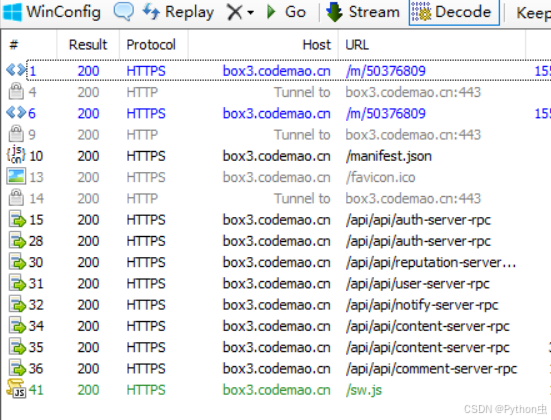
记得关上抓包工具,不然爬虫程序会导致异常,后文有写
逐包分析
我们一个一个包分析,发现编号34的返回值有点可疑:
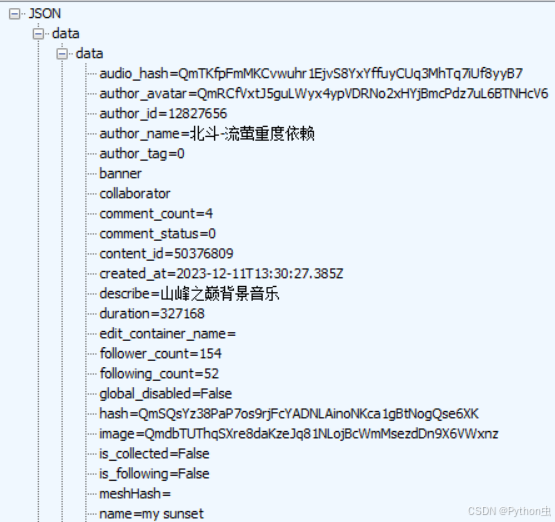
看到audio_hash的值:QmTKfpFmMKCvwuhr1EjvS8YxYffuyCUq3MhTq7iUf8yyB7
回开发者模式找一下
刚好有一个是匹配的:
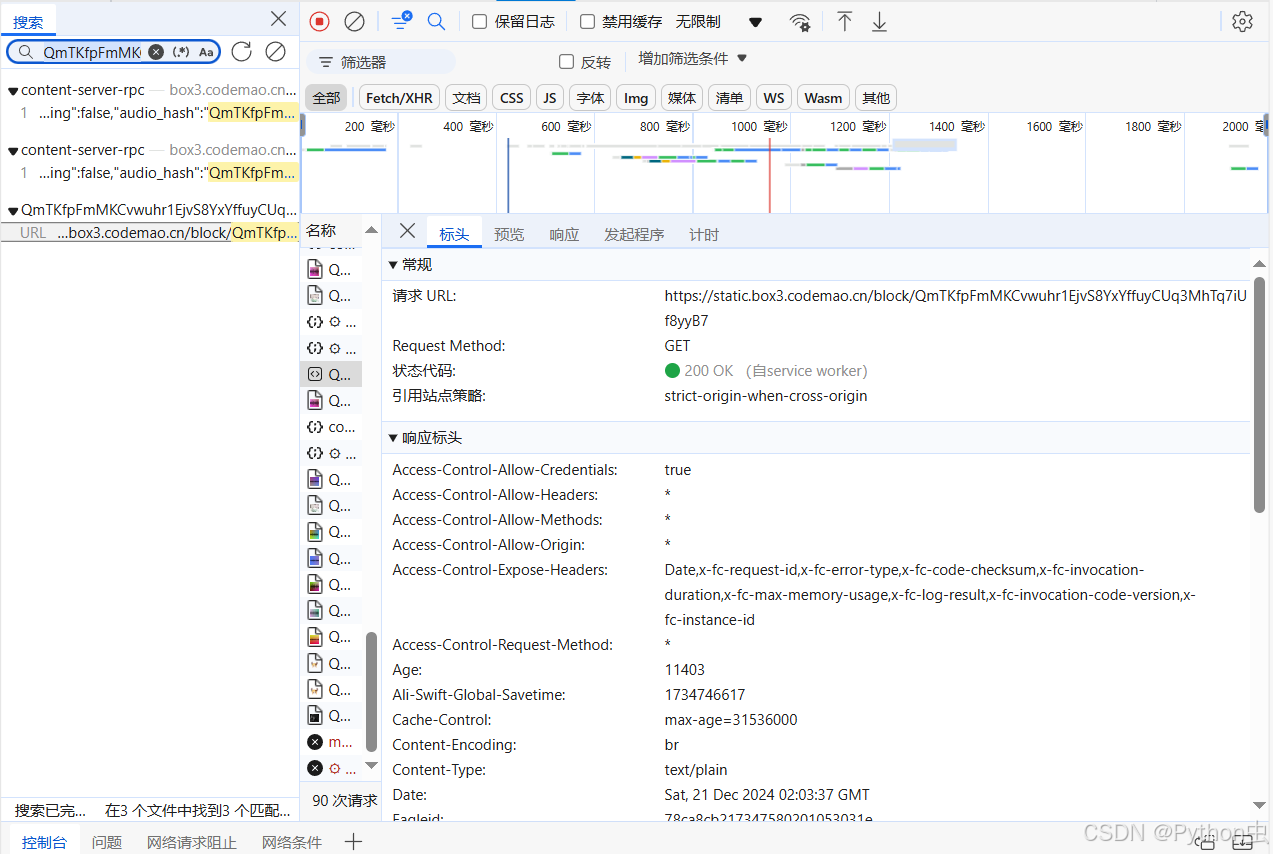
打开这个网址,下载下来,后缀改成.mp3发现就是歌曲的圆形!
继续编写代码
编写Header
我们复制一下在Fiddler的请求头:
Host: box3.codemao.cn
Connection: keep-alive
Content-Length: 124
Cache-Control: max-age=0
Prefer: safe
User-Agent: ***
DNT: 1
Content-Type: application/json
Accept: */*
Origin: https://box3.codemao.cn
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: same-origin
Sec-Fetch-Dest: empty
Referer: https://box3.codemao.cn/sw.js
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cookie: ***
这里为了不泄露隐私,所以我把cookie和user-agent标成了3个新号(***)
改一下写入header变量、改一下地址:
import requests
url = "https://box3.codemao.cn/m/50376809"
header = {
"Host": "box3.codemao.cn",
"Connection": "keep-alive",
"Content-Length": "110",
"Cache-Control": "max-age=0",
"Prefer": "safe",
"User-Agent": "***",
"DNT": "1",
"Content-Type": "application/json",
"Accept": "*/*",
"Origin": "https://box3.codemao.cn",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "same-origin",
"Sec-Fetch-Dest": "empty",
"Referer": "https://box3.codemao.cn/sw.js",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cookie": "***"
}
res = requests.post("https://box3.codemao.cn/api/api/content-server-rpc",headers=header)
res.encoding = "utf-8"
print(res.text)
报错了:
requests.exceptions.ConnectionError: ('Connection aborted.', RemoteDisconnected('Remote end closed connection without response'))
编写Payload(负载)
我们少写了负载(payload),复制一份(在Fiddler或者开发者模式都可以):
为了保护隐私,userid我替换成了***
{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":50376809}}}
这可以不用dict,直接用字符串装着就可以了
payload_text = '{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":1061259}}}'
再把装着负载的请求发送出去:
res = requests.post("https://box3.codemao.cn/api/api/content-server-rpc",data=payload_text,headers=header)
运行!:
得到了我们一直要的结果:
{"type":"success","data":{"type":"get","data":{"author_id":12827656,"author_tag":0,"comment_count":4,"comment_status":0,"content_id":50376809,"follower_count":154,"following_count":52,"play_count":0,"version":1,"version_id":60053579,"view_count":44,"global_disabled":false,"is_collected":false,"is_following":false,"audio_hash":"QmTKfpFmMKCvwuhr1EjvS8YxYffuyCUq3MhTq7iUf8yyB7","author_avatar":"QmRCfVxtJ5guLWyx4ypVDRNo2xHYjBmcPdz7uL6BTNHcV6","author_name":"北斗-流萤重度依赖","banner":[],"collaborator":[],"created_at":"2023-12-11T13:30:27.385Z","describe":"山峰之巅背景音
乐","duration":327168,"edit_container_name":"","hash":"QmSQsYz38PaP7os9rjFcYADNLAinoNKca1gBtNogQse6XK","image":"QmdbTUThqSXre8daKzeJq81NLojBcWmMsezdDn9X6VWxnz","meshHash":"","name":"my sunset","notice":null,"play_container_name":null,"published_at":"2023-12-11T13:32:30.126Z","url":null}}}
缩减Header
我们看到Header的代码像某坨东西:
header = {
"Host": "box3.codemao.cn",
"Connection": "keep-alive",
"Content-Length": "110",
"Cache-Control": "max-age=0",
"Prefer": "safe",
"User-Agent": "***",
"DNT": "1",
"Content-Type": "application/json",
"Accept": "*/*",
"Origin": "https://box3.codemao.cn",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "same-origin",
"Sec-Fetch-Dest": "empty",
"Referer": "https://box3.codemao.cn/sw.js",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cookie": "***"
}
根据我的测试,只用保留cookie即可:
header = {
"Cookie": "***"
}
从一个推到全部
我们看到这只可以找到一首,而其他的找不到
我们和其他的歌曲对比一下:
这是sunser(https://box3.codemao.cn/m/50376809)的Payload:{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":50376809}}}
这是flower dance(https://box3.codemao.cn/m/50072982)的Payload:{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":50072982}}}
聪明的你也已经看出来了:
Payload中的contentId是网址的最后的数字
(把contentId的值改成url.split("/")[-1](最后一项的数字))
所以我们的Payload改成这样:
payload_text = '{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":'+url.split("/")[-1]+'}}}'
我们现在可以改变url来得到歌曲的url
下载歌曲
转换形式
我们把获取到的结果
{"type":"success","data":{"type":"get","data":{"author_id":12827656,"author_tag":0,"comment_count":4,"comment_status":0,"content_id":50376809,"follower_count":154,"following_count":52,"play_count":0,"version":1,"version_id":60053579,"view_count":44,"global_disabled":false,"is_collected":false,"is_following":false,"audio_hash":"QmTKfpFmMKCvwuhr1EjvS8YxYffuyCUq3MhTq7iUf8yyB7","author_avatar":"QmRCfVxtJ5guLWyx4ypVDRNo2xHYjBmcPdz7uL6BTNHcV6","author_name":"北斗-流萤重度依赖","banner":[],"collaborator":[],"created_at":"2023-12-11T13:30:27.385Z","describe":"山峰之巅背景音 乐","duration":327168,"edit_container_name":"","hash":"QmSQsYz38PaP7os9rjFcYADNLAinoNKca1gBtNogQse6XK","image":"QmdbTUThqSXre8daKzeJq81NLojBcWmMsezdDn9X6VWxnz","meshHash":"","name":"my sunset","notice":null,"play_container_name":null,"published_at":"2023-12-11T13:32:30.126Z","url":null}}}
把它传到一个dict变量里,用json.loads()来解析json
audio_url = json.loads(res.text)
提取音乐URL
我们观察到歌曲的地址在audio_hash["data"]["data"]["audio_hash"]
我们再补充
audio_url = json.loads(res.text)["data"]["data"]["audio_hash"]
我们再看我们下载的包
我们再前面加上https://static.box3.codemao.cn/block/就是歌曲的网址了
audio_url = "https://static.box3.codemao.cn/block/" + \
json.loads(res.text)["data"]["data"]["audio_hash"]
保存音乐
最后下载至本地,名字是它的后几位数字:
save_path = url.split("/")[-1] + ".mp3"
with requests.get(audio_url, stream=True) as r:
with open(save_path, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
最后代码
把上面的整合一下
在加上一些输入和输出的设置
再重声明一下:cookie和userId为了保护隐私,我改成***
import requests
import json
url = input("请输入音频链接:")
# url = "https://box3.codemao.cn/m/50376809"
audio_id = url.split("/")[-1]
header = {
"Cookie": "***"
}
payload_text = '{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":'+audio_id+'}}}'
print("正在访问...")
res = requests.post("https://box3.codemao.cn/api/api/content-server-rpc",data=payload_text,headers=header)
res.encoding = "utf-8"
print("访问成功, 结果:", res.text)
audio_url = "https://static.box3.codemao.cn/block/" + \
json.loads(res.text)["data"]["data"]["audio_hash"]
print("歌曲地址:", audio_url)
save_path = audio_id + ".mp3"
print(f"正在下载至{save_path}")
with requests.get(audio_url, stream=True) as r:
with open(save_path, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
print(f"保存至文件{save_path}")
其他
为什么要关掉Fiddler再启动爬虫程序
因为这样会报错:
urllib3.exceptions.SSLError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1006)
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\requests\adapters.py", line 667, in send
resp = conn.urlopen(
^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\urllib3\connectionpool.py", line 843, in urlopen
retries = retries.increment(
^^^^^^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\urllib3\util\retry.py", line 519, in increment
raise MaxRetryError(_pool, url, reason) from reason # type: ignore[arg-type]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
urllib3.exceptions.MaxRetryError: HTTPSConnectionPool(host='box3.codemao.cn', port=443): Max retries exceeded with url: /api/api/content-server-rpc (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1006)')))
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "e:\zhu\python\爬虫\codemao_music\getURL.py", line 14, in <module>
res = requests.post("https://box3.codemao.cn/api/api/content-server-rpc",data=payload_text,headers=header)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\requests\api.py", line 115, in post
return request("post", url, data=data, json=json, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\requests\api.py", line 59, in request
return session.request(method=method, url=url, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\requests\sessions.py", line 589, in request
resp = self.send(prep, **send_kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\requests\sessions.py", line 703, in send
r = adapter.send(request, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\PC\AppData\Local\Programs\Python\Python311\Lib\site-packages\requests\adapters.py", line 698, in send
raise SSLError(e, request=request)
requests.exceptions.SSLError: HTTPSConnectionPool(host='box3.codemao.cn', port=443): Max retries exceeded with url: /api/api/content-server-rpc (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1006)')))
整理代码
import requests
import json
url = input("请输入音频链接:")
# url = "https://box3.codemao.cn/m/50376809"
audio_id = url.split("/")[-1]
header = {
"Cookie": "***"
}
payload_text = '{"type":"get","data":{"type":"id","data":{"type":3,"userId":***,"isPublic":true,"meshHash":false,"contentId":'+audio_id+'}}}'
print("正在访问...")
res = requests.post("https://box3.codemao.cn/api/api/content-server-rpc",data=payload_text,headers=header)
res.encoding = "utf-8"
print("访问成功, 结果:", res.text)
audio_url = "https://static.box3.codemao.cn/block/" + \
json.loads(res.text)["data"]["data"]["audio_hash"]
print("歌曲地址:", audio_url)
save_path = audio_id + ".mp3"
print(f"正在下载至{save_path}")
with requests.get(audio_url, stream=True) as r:
with open(save_path, 'wb') as f:
for chunk in r.iter_content(chunk_size=8192):
f.write(chunk)
print(f"保存至文件{save_path}")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









