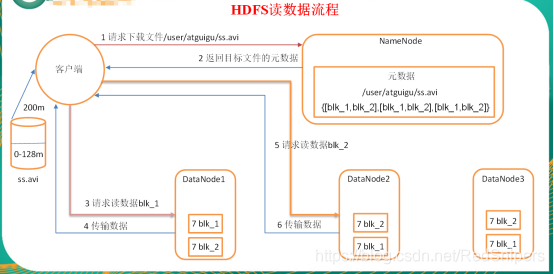
HDFS读数据流程 1)客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。 2)挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。 3)datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。 4)客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
 HDFS读数据流程解析
HDFS读数据流程解析
HDFS读数据流程解析
HDFS读数据流程解析
 649
2120
1247
3043
649
2120
1247
3043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言