



这是一篇从 0 到 1 在 AutoDL 上运行Qwen3-30B-A3B 的实战记录——包含做选择时的心理活动、以及踩过/躲过的小坑。希望你能像坐我旁边一样,看我如何把一块 H20 96GB 卡调教到能顺畅出字。
一、算力卡选择与租用
1.1 选择合适的GPU配置
这次我们要跑的是Qwen3-30B-A3B-Instruct-2507这个模型,这是一个的30B参数的模型。首先我们需要选择具有足够显存的GPU。下面先快速估个账:
显存 & 磁盘需求怎么估?
| 组成 | 估算方式 | 约占用 |
|---|---|---|
| 模型参数(FP16) | 30B * 2 Bytes | ~60 GB 显存/磁盘 |
| 模型参数(BF16) | 同 FP16 | ~60 GB |
| 8bit 量化 | 30B * 1 Byte | ~30 GB |
| KV Cache (生成时) | seq_len * hidden * layer_factor * bytes | 视上下文而定 (典型 2~8 GB) |
| 临时中间张量/碎片 | 10%~20% 预留 | 6~12 GB |
显存经验公式(推理):
显存需求 ≈ 模型参数(精度后) + KV Cache(并发*上下文) + 预留(10~20%)
以:单轮 2K tokens 上下文 + 采样 512 输出,batch=1 推理为例:
- FP16 参数 60GB
- KV Cache 约 ~3GB(粗略)
- 预留 8GB
- 合计 ≈ 71GB
磁盘:
| 项目 | 大小(约) |
|---|---|
| 模型权重(safetensors 多分片) | 55~65 GB |
默认的 50GB 会直接“空间不足”。我实际跑完磁盘占用63.88GB,建议扩容到70GB。
推荐配置:
- GPU型号: H20-NVLink
- 显存: 96GB
- 内存: 200GB
- 数据盘: 扩容后建议选择不少于70GB(重要)
1.2 租用步骤
-
登录AutoDL平台
- 访问 AutoDL官网
- 登录你的账户
-
选择算力规格
- 在算力市场中选择"H20-NVLink / 96GB"配置选购时要注意还剩多少可扩容的数据盘
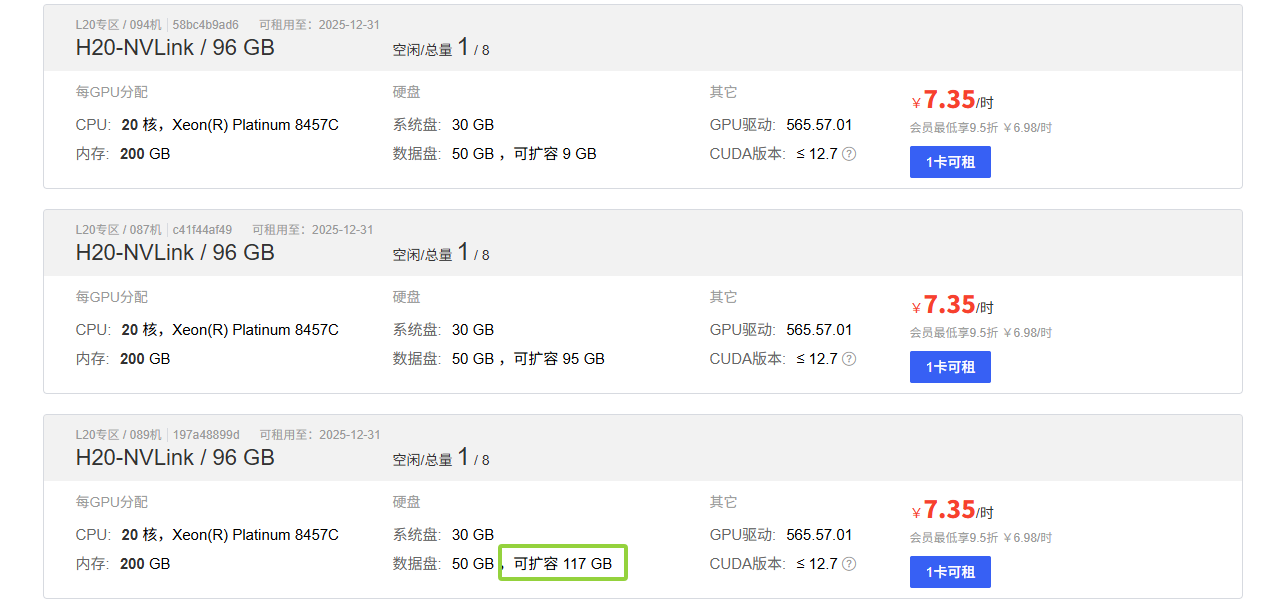
- 在算力市场中选择"H20-NVLink / 96GB"配置选购时要注意还剩多少可扩容的数据盘
-
选择镜像
- 建议选择:
PyTorch / 2.3.0 / 3.12(ubuntu22.04) / 12.1
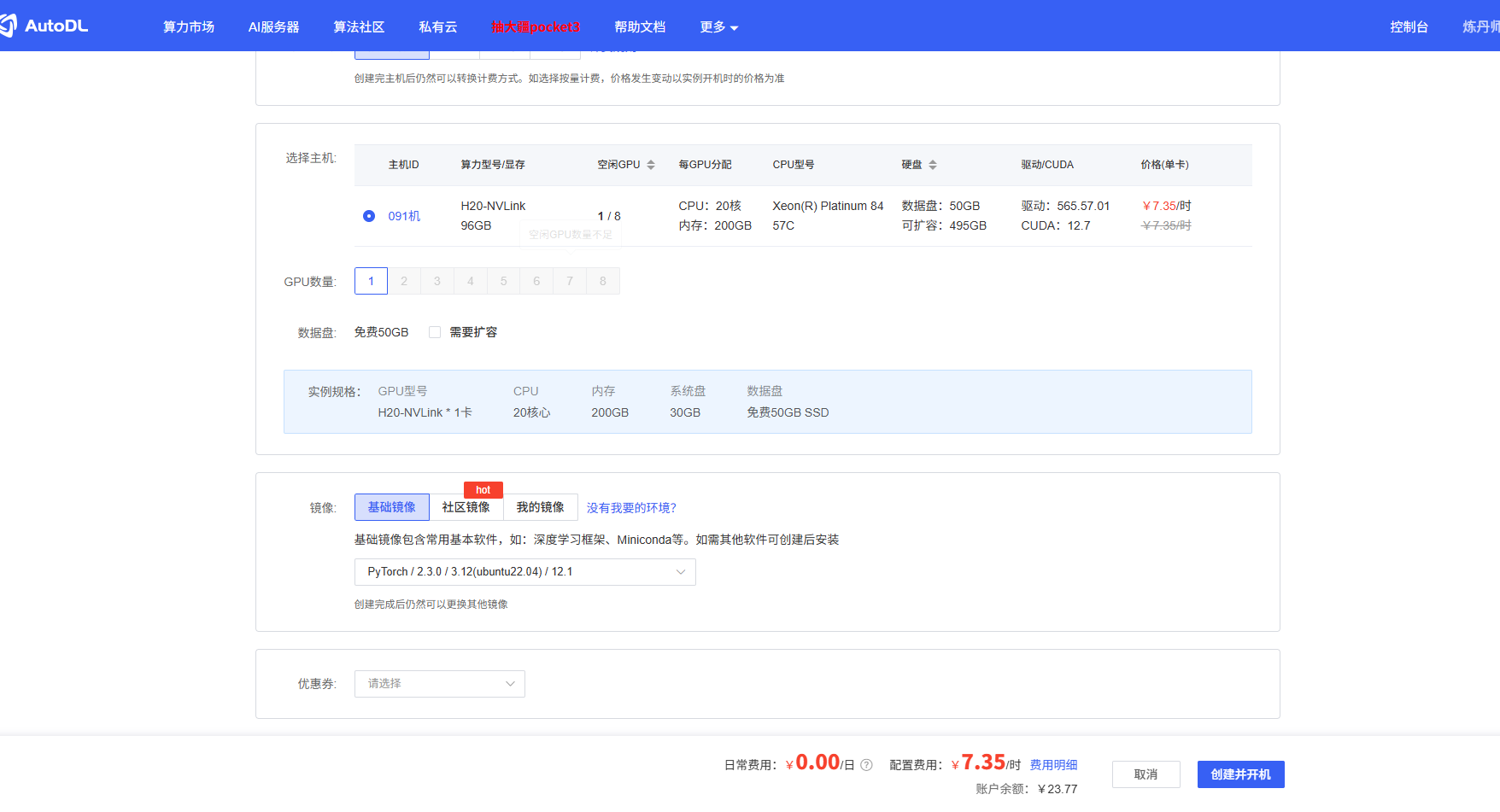
- 建议选择:
-
确认订单
- 检查配置信息
- 确认价格(约¥7.35/时)
- 点击"创建并开机"
二、数据盘扩容操作
2.1 扩容步骤
-
进入实例管理
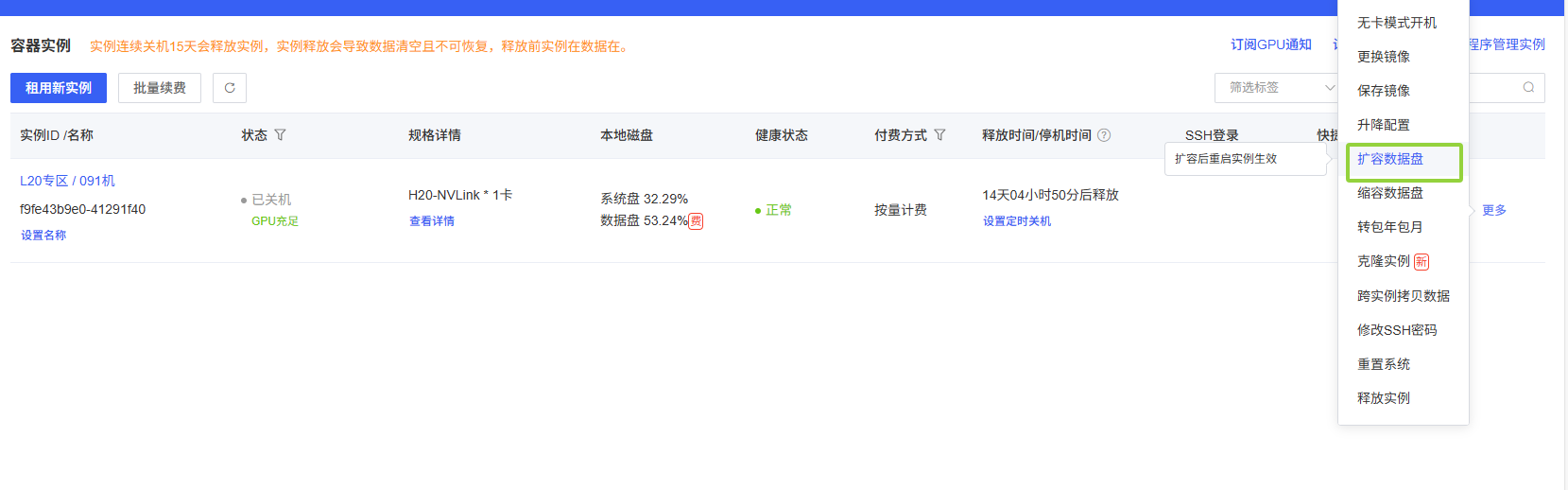
在实例列表中找到你的机器,点击右侧的"扩容数据盘"选项。
-
设置扩容容量
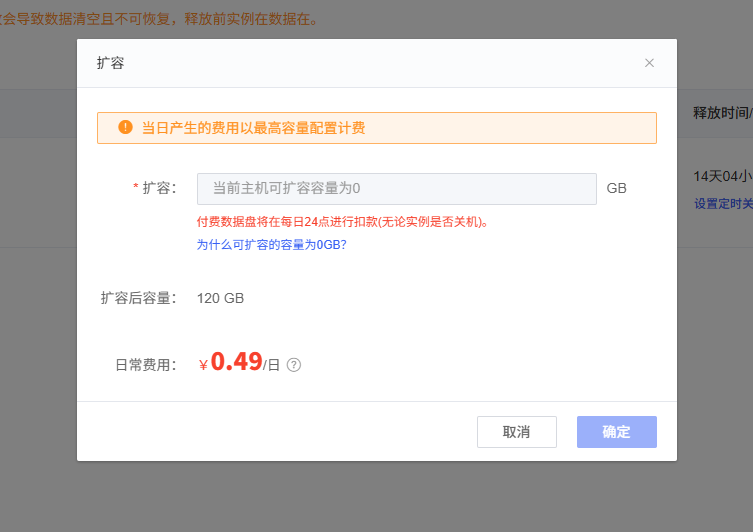
在弹出的对话框中设置扩容容量,建议扩容到70GB(根据实际需求调整,这里我一开始多估计了一点)。
-
等待扩容完成
三、SSH连接到实例
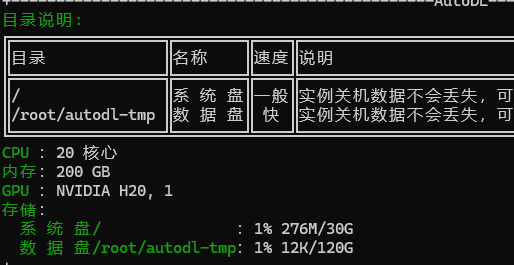
连接成功后我们能看到当前的GPU型号和数据盘大小。
四、运行Qwen3-30B-A3B
接下来我将使用两种方式来运行Qwen3模型,分别是ModelScope库和vllm。
4.1 ModelScope
首先安装ModelScope环境
pip install modelscope
source /etc/network_turbo
pip install git+https://github.com/huggingface/transformers.git@main
pip install accelerate
编写Python代码
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Thinking"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content) # no opening <think> tag
print("content:", content)
设置环境变量
将ModelScope的缓存目录设置到数据盘。
export MODELSCOPE_CACHE=/root/autodl-tmp/cache
运行测试
运行python程序。
等待漫长的模型下载过程…

模型下载完成后,稍等片刻就能看到模型输出

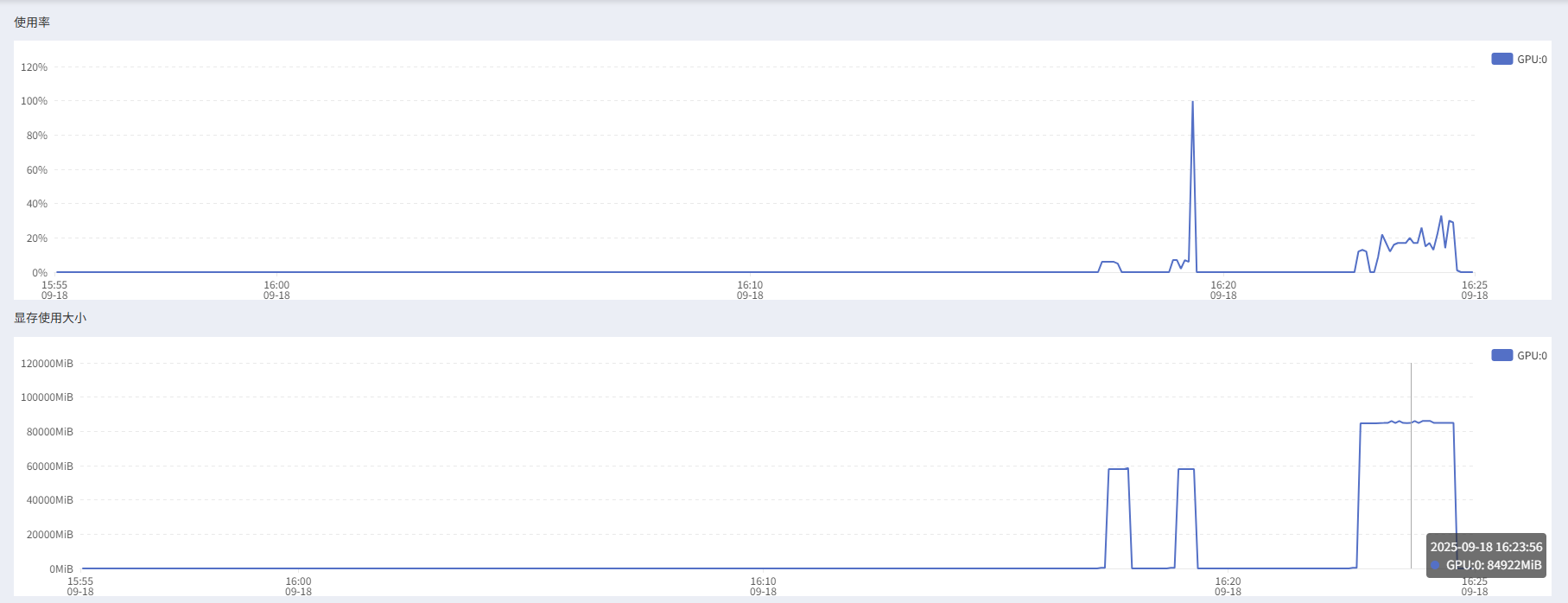
在AutoDL上我们可以看到实时的GPU使用率和显存占用,显存大约占用85GB。
4.2 vllm
vllm是一个高效的推理引擎,专为大规模语言模型设计。它支持多种优化技术,如流水线并行和张量并行,以最大化GPU利用率和吞吐量。
首先安装vllm环境
pip install vllm --extra-index-url https://mirrors.tuna.tsinghua.edu.cn/pytorch-wheels/cu128 -i https://pypi.tuna.tsinghua.edu.cn/simple
设置环境变量
将vllm的缓存目录设置到数据盘。设置后vllm和modelscope的缓存目录是公用的,接下来的模型下载就不会重复了。
export TRANSFORMERS_CACHE=/root/autodl-tmp/cache
运行测试
这里将上下文长度设置为4096,可以根据显存大小进行调整。
VLLM_USE_MODELSCOPE=true vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 4096
等待模型加载完成后,打开另一个终端窗口,使用curl命令进行测试:
curl -X POST "http://localhost:8000/v1/chat/completions" -H "Content-Type: application/json" -d '{
"model": "Qwen/Qwen3-30B-A3B-Instruct-2507",
"messages": [
{"role": "user", "content": "write a store about dog and cat"}
]
}'
等待模型输出结果
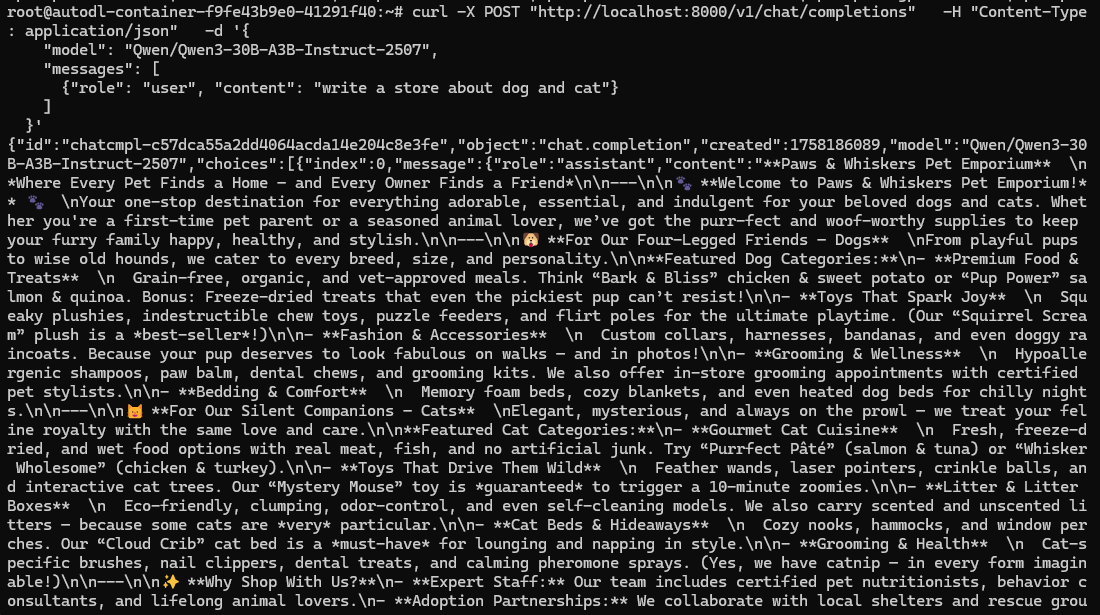
在刚刚的vllm终端窗口我们能看到模型的推理速度,可以看到推理速度非常快有51.5tokens/s。

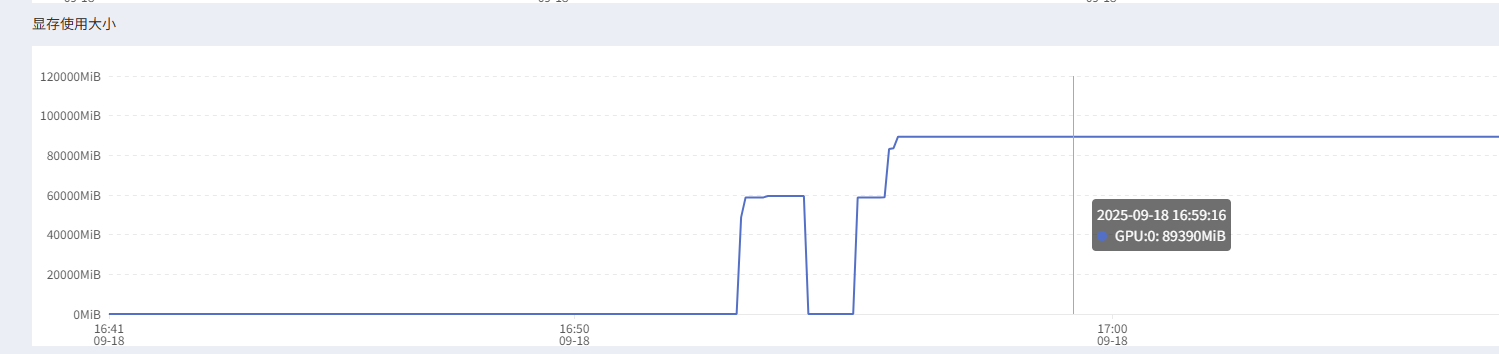
在AutoDL上我们可以看到在上下文长度为4096时,实时的GPU使用率和显存占用,显存大约占用89GB。
五、总结
这一圈下来,最强烈的感受是:30B 级模型“看起来吓人”,但流程真不神秘——准备空间 > 等待下载 > 第一次出字。
最后
30B 大模型不是高冷科研怪兽,更像一只“吃得多但脾气还算好”的巨型猫:给它足够的碗(显存)、铺好垫子(磁盘),它就会安静地陪你聊天。
如果你也准备试:祝你一次拉满、一次出字;有新奇玩法(比如 4bit量化后的模型 + 长上下文 + 并发)欢迎留言交流。👋


















 1106
1106



 到【灌水乐园】发言
到【灌水乐园】发言








