







什么是缓存击穿?
缓存击穿问题也叫热点Key问题,一个被高并发访问且缓存过期了的热点key突然失效,由于缓存为空,导致所有的请求直接访问数据库,无效的请求访问会在瞬间给数据库带来巨大的冲击
如何解决缓存击穿问题?
解决缓存击穿的三种解决方案:
1.互斥锁
使用分布式锁控制缓存更新,只有获取到锁的请求才能访问数据库更新缓存,其他请求阻塞等待。采用双重检查机制优化性能:等待锁释放后,其他请求获取锁前先检查缓存是否有数据,有则直接返回,避免重复更新。该方案无额外内存消耗,数据一致性强,实现相对简单。但线程需要等待,性能一般,存在死锁风险,适合对数据一致性要求严格的场景。
我喜欢使用Redisson实现分布式锁。Redisson为Redis提供了多种数据结构的支持,提供了线程安全的操作,简化了Java使用Redis的复杂度
示例代码
@Service
public class RedissonDoubleCheckService {
@Autowired
private RedissonClient redissonClient;
@Autowired
private RedisTemplate<String, Object> redisTemplate;
/**
* Redisson + 双重检查锁机制
*/
public Object getDataWithDoubleCheck(String key) {
// 第一次检查:直接从缓存获取
Object cachedData = redisTemplate.opsForValue().get(key);
if (cachedData != null) {
return cachedData;
}
// 缓存未命中,使用Redisson获取分布式锁
RLock lock = redissonClient.getLock("lock:" + key);
try {
// 尝试获取锁,等待1秒,自动续期
if (lock.tryLock(1, TimeUnit.SECONDS)) {
// 获取锁成功后,第二次检查缓存
cachedData = redisTemplate.opsForValue().get(key);
if (cachedData != null) {
return cachedData;
}
// 确实需要更新缓存,从数据库加载数据
Object dbData = loadDataFromDB(key);
if (dbData != null) {
// 更新缓存
redisTemplate.opsForValue().set(key, dbData, Duration.ofMinutes(10));
}
return dbData;
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
} finally {
// 释放锁(Redisson会自动处理)
if (lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
return null;
}
private Object loadDataFromDB(String key) {
// 模拟数据库查询
return "data_for_" + key;
}
}
2.逻辑过期
设置缓存永不过期,而是数据内部维护一个逻辑过期时间戳,请求获取数据时,先判断当前时间是否超过逻辑过期时间。如果过期,拿到锁的线程去开启一个新的线程,异步去更新缓存,其他所有的请求直接返回旧数据,这种方案线程无需等待,性能较好。但是不保证一致性,有额外的内存消耗,实现复杂
3.使用中间件或者框架
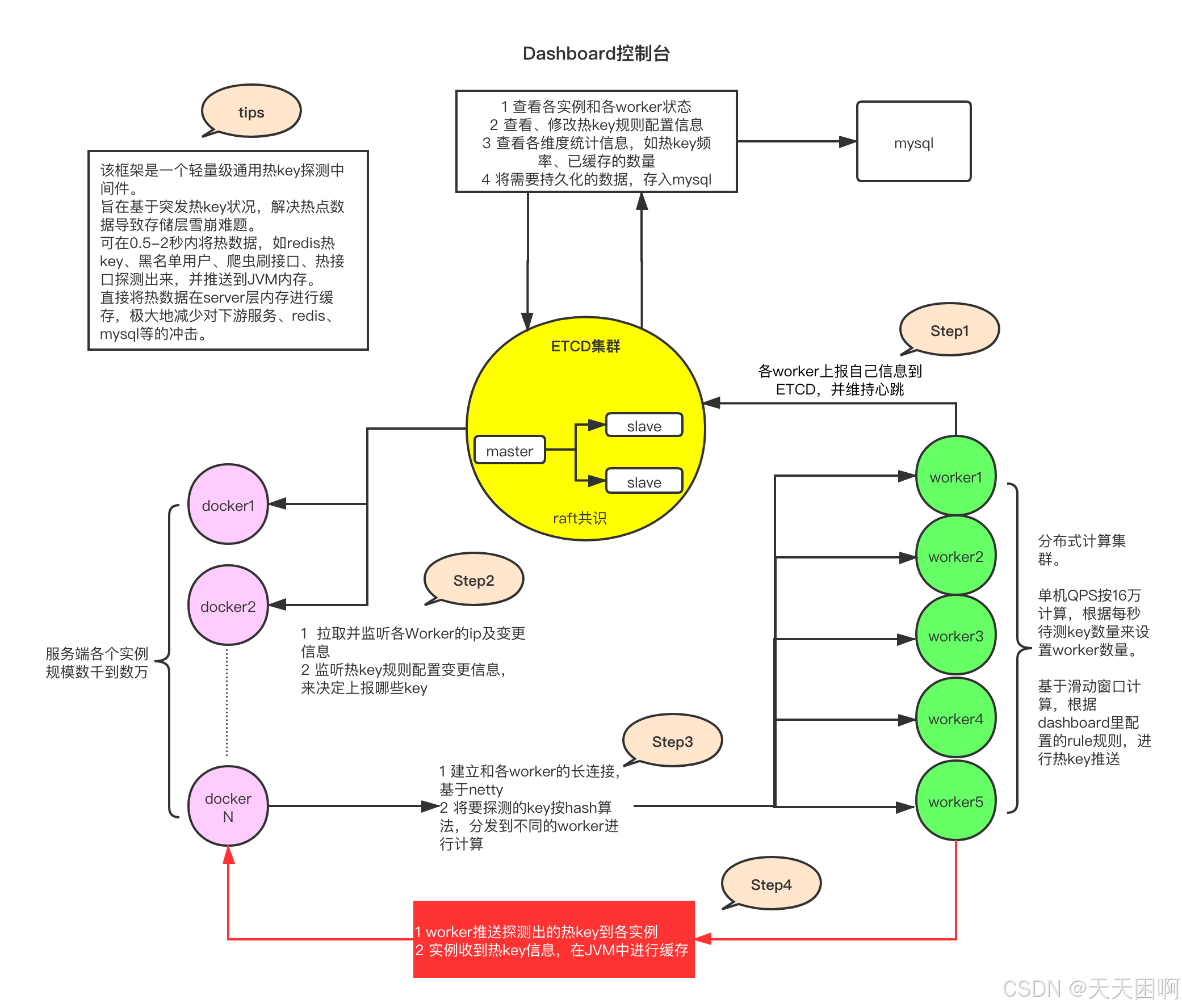
京东提供了一个轻量级通用的热key探测中间组件hotkey
根据官方仓库描述:hotkey是京东App后台中间件,毫秒级探测热点数据,毫秒级推送至服务器集群内存,大幅降低热key对数据层查询压力,历经多次高压压测和京东618、双11大促考验
官方架构图如下:
什么是缓存穿透?
缓存穿透指查询请求的数据在缓存中和数据库中都没有相应的记录,每次请求都会去数据库查询,这样缓存永远不会生效,造成数据库负担加重
如何解决缓存穿透?
1.对非法请求的参数做好校验,拦截异常请求,对一些异常的用户和异常ip做限流,也可以做一个黑名单,在网关或者在请求检查这一步把非法的请求拦截住
2.缓存空值,对于数据库中查不到的key,我们缓存一个空值或者特殊标识,并设置相对较短的过期时间(比如5-10分钟)。这样可以防止相同的无效key请求直接打到数据库。但是这种方案有一个局限性:如果每个请求查询的key都不一样,那么缓存空值就会失效,因为无法命中缓存,还是会穿透到数据库。
3.布隆过滤器方案:为了解决缓存空值的局限性,我们可以引入布隆过滤器。在数据写入数据库的同时,也将key写入布隆过滤器中。当请求到来时,先通过布隆过滤器快速判断这个数据是否可能存在:如果布隆过滤器判断数据不存在,那就可以直接返回,无需查询缓存和数据库。如果布隆过滤器判断数据可能存在,再继续走正常的缓存查询流程
建议三种方案结合:
方案一是一个预防的作用,方案二和三将缓存空值和布隆过滤器结合起来使用,可以形成一个更完善的防护体系。布隆过滤器负责过滤掉大部分肯定不存在的请求,缓存空值则作为兜底方案处理特殊情况,两者配合能够有效防止缓存穿透问题。
扩展知识:
布隆过滤器的原理:布隆过滤器由一个位数组和k个独立的哈希函数组成。添加元素时,使用k个哈希函数计算出k个哈希值,将位数组中对应位置设为1。查询时,同样计算k个哈希值,检查对应位置是否都为1:如果所有位置都是1,说明元素可能存在,如果有任何位置是0,说明元素肯定不存在,利用"肯定不存在"的特性,可以有效过滤掉大量无效请求,防止缓存穿透。
它的缺点有误判的可能,他不支持删除,如果你在数据库中执行删除的操作布隆过滤器就没有办法同步删除的操作
什么是缓存雪崩?
缓存雪崩是指在同一时间段,大量的缓存key同时失效或者Redis服务宕机,导致大量的数据到达数据库,带来巨大压力
如何解决缓存雪崩?
1.给不同的key设置过期时间,加上一个随机值,避免同一时间大量缓存失效
2.使用多级缓存,如本地缓存和分布式缓存相结合使用
3.针对热点数据,做缓存预热,保证业务高峰期时数据不会过期
4.利用Redis集群提高服务的可用性,做好降级限流熔断等策略
总结
掌握缓存相关知识不仅能在面试中脱颖而出,更是实际工作中必备的技能。每一个难点的攻克都是成长的足迹,每一份努力都会在秋招中得到回报。大家秋招加油,相信你们都能收获理想的offer!


















 2959
2959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









