



 文章探讨了语料库在自然语言处理中的重要性,包括平衡语料库、平行语料库等类型。接着介绍了N-gram模型及其局限性,以及神经网络语言模型如何克服这些问题,特别是词向量表示的作用。此外,还讨论了词法分析的挑战,如分词和词性标注,以及句法分析中的短语结构和依赖分析。最后提到了语义分析和CRFs在解决语义消歧等问题中的应用。
文章探讨了语料库在自然语言处理中的重要性,包括平衡语料库、平行语料库等类型。接着介绍了N-gram模型及其局限性,以及神经网络语言模型如何克服这些问题,特别是词向量表示的作用。此外,还讨论了词法分析的挑战,如分词和词性标注,以及句法分析中的短语结构和依赖分析。最后提到了语义分析和CRFs在解决语义消歧等问题中的应用。
语料库
语料库(corpus) :指收集和整理的一组文本数据,用于训练和评估自然语言处理模型,就是存放语言材料的仓库 (语言数据库)
语料库类型:异质的、同质的、系统的、专用的
知识库:指存储和组织的结构化知识数据,通常包括实体、属性和关系。
词汇语义库、词法、句法规则库、常识库等等

-
平衡语料库:平衡语料库着重考虑语料的代表性与平衡性。
- 一种是指在同一种语言的语料上的平行;
- 另一种平行语料库是指在两种或多种语言之间的平行采样和加工,例如,机器翻译中的双语对齐语料库
-
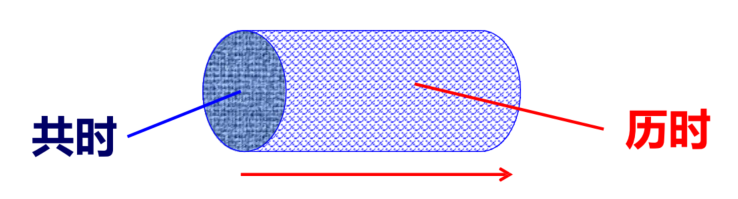
共时语料库:是为了对语言进行共时(同一时段)研究而建立的语料库,即研究一个共时平面中的元素与元素的关系
-
历时语料库:是为了对语言进行历时研究而建立的语料库,即研究一个历时切面中元素与元素关系的演化
-
熟语料库:是指经过预处理和清洗后的文本数据,例如去除语法错误、拼写错误、标点符号等,进行了分词、词性标注、句法分析等处理
-
生语料库:生语料库(raw corpus)是指未经过任何处理和清洗的原始文本数据,包括语法错误、拼写错误、标点符号等。生语料库通常需要经过预处理和清洗才能用于训练和评估自然语言处理模型
形式语言与自动机
形式语法



- N:词元有多个种类
- ∑\sum∑是开头结尾的标识符
- P:表示一个映射规则
- S:表示一个句子



- 就是箭头就是映射关系,可以进行替换
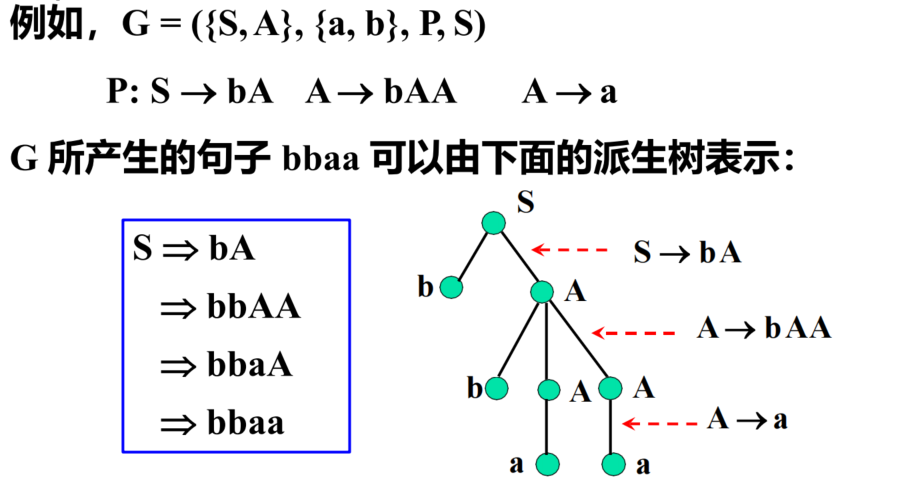
文法

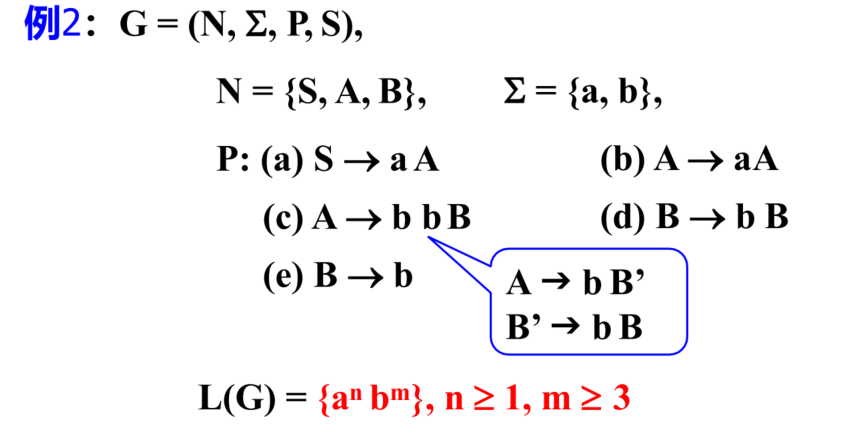



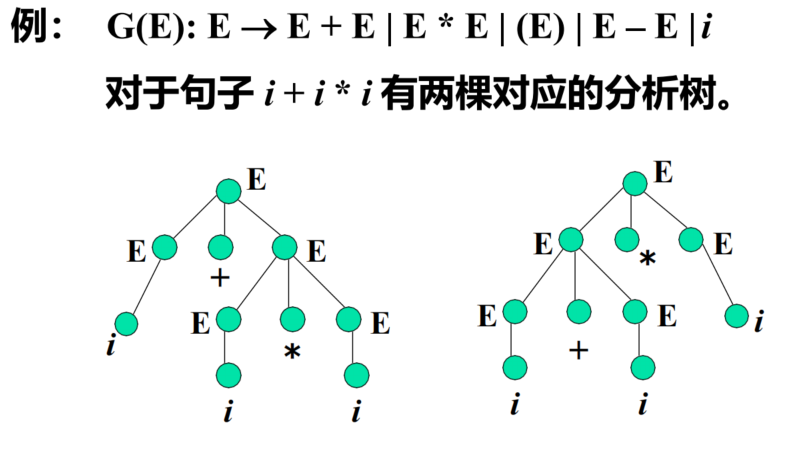
- 如果CFG树并不止一颗,那么文法有二义性



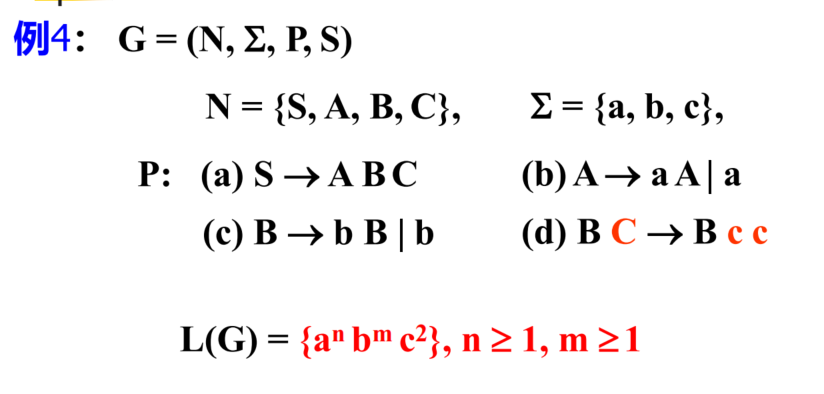
有限自动机
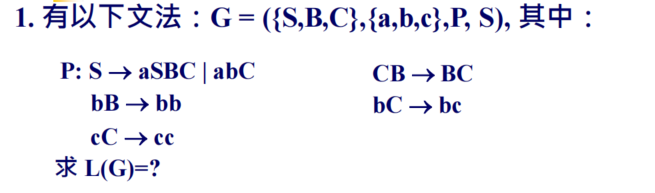

N元语言模型
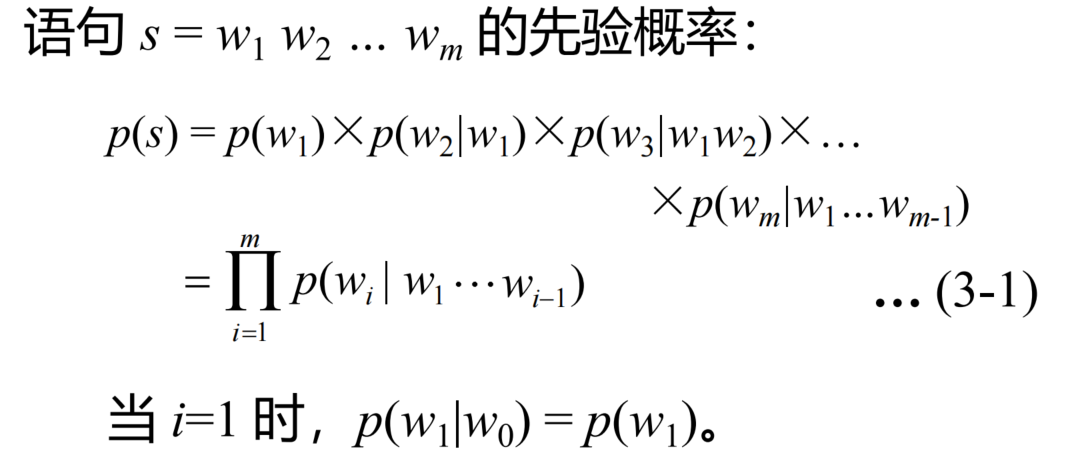

- 即,当前位置的每一个词与所有历史的词都相关(很长的一个)

- 解决方案:划分等价类


两个条件:
1)句子内所有字符串的概率和为1 ,∑sp(s)=1\sum_s{p(s)=1}∑sp(s)=1
2)句子头和句尾加入标志词< BOS > 和 < EOS >
N-gram 例子


参数估计

- 如何算?





平滑

- 困惑度


- 拉普拉斯平滑


习题


N-gram模型的缺点:
- 数据稀疏:测试集很容易出现没出现过的次元,导致零概率发生
- 忽略语义相似性,语义相似但是无法共享信息
神经网络的语言模型
基于N-gram模型的改进
- One-hot表示

- 存在问题,one-hot表示做乘积运算,病态

- 基于连续语义空间的词语表示

- 词向量表示(连续的数字,其实是词出现的概率P(w|wi))
- 神经网络函数的设计
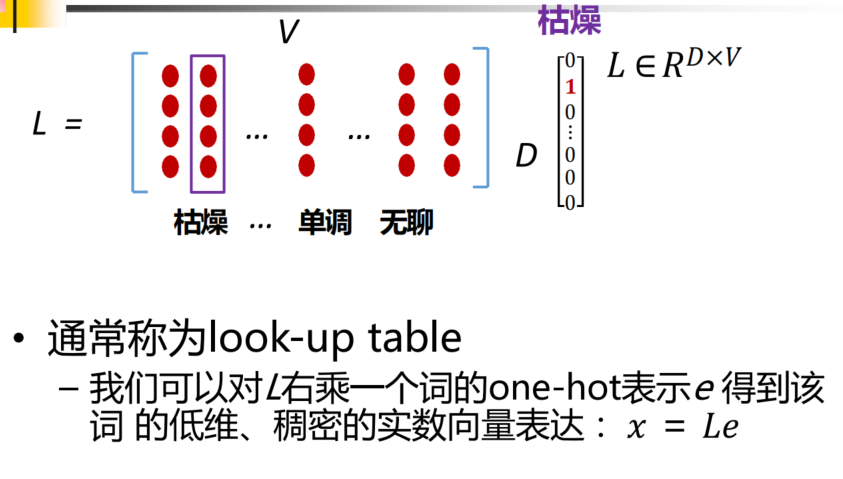
词表规模V和词向量维度D如何确定?
- V的确定:1. 训练数据中所有词;2. 频率高于某个 阈值的所有词;3. 前V个频率最高的词
- D的确定:超参数,人工设定,一般从几十到几百(Embedding)
如何学习L?
- 通常先随机初始化,然后通过目标函数优化词的向
量表达(e.g. 最大化语言模型似然度)
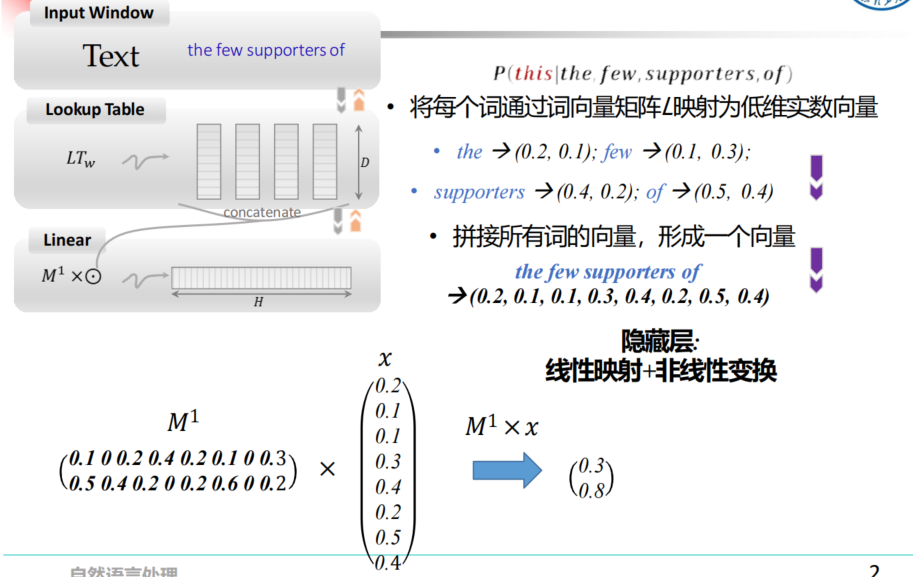
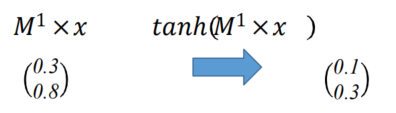
- 考虑历史词元 ,自然引出神经网络的RNN模型(LSTM)
词法分析
- 曲折语(如,英语、德语、俄语等):用词的形态变化表示语法关系,一个形态成分可以表示若干种不同的语法意义,词根和词干与语词的附加成分结合紧密
- 词法分析:词的形态分析(形态还原)。
- 任务:单词识别、形态还原
- 黏着语(如:日语等):分词+形态还原。
- 分析语(孤立语)(如:汉语):分词
汉语分词的主要问题:汉语分词规范问题,歧义切分字段处理,未登录词的识别
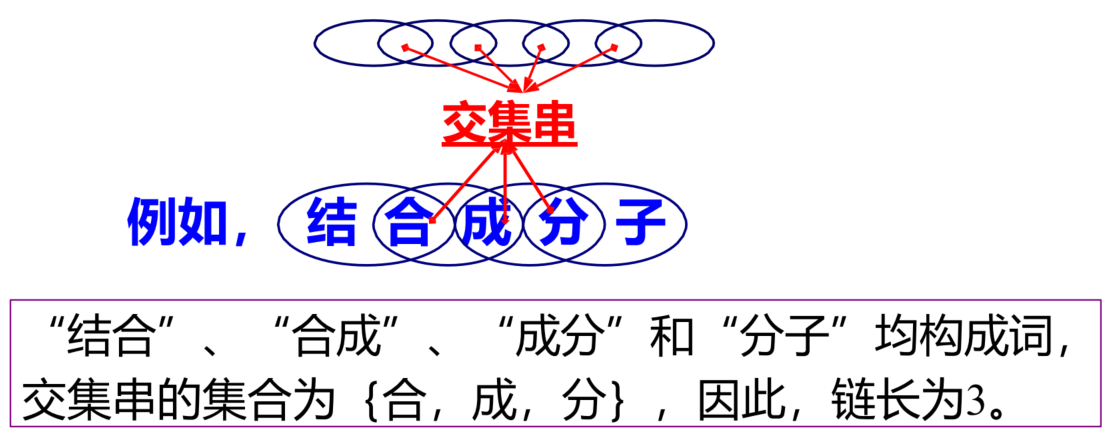
链长:一个交集型切分歧义所拥有的交集串的集合称为交集串链,它的个数称为链长。


基本原则:
1)语义上无法由组合成分直接相加而得到的字串应该合并为一个分词单位
2)语类无法由组合成分直接得到的字串应该合并为一个分词单位
辅助原则:
1)有明显分隔符标记的应该切分之
2)附着性语(词)素和前后词合并为一个分词单位
3)使用频率高或共现率高的字串尽量合并为一个分词单位
4)双音节加单音节的偏正式名词尽量合并为一个分词单位
5)双音节结构的偏正式动词应尽量合并为一个分词单位
6)内部结构复杂、合并起来过于冗长的词尽量切分



正向最大匹配算法:

- 从前往后,词能越长就越长,小于最大长度
逆向最大匹配算法:
- 从后往前,词越长越好,小于最大长度
双向最大匹配算法:

-
命名实体包含:人名、地名、组织机构名、数字、日期、货币数量 -
词性标注的最大问题是消除词性兼类歧义
词性标注集
- NN 名词
- NR 专业名词
- NT 时间名词、
- VA可做谓语的形容词
- VC “是”
- VE“有”作为主要动词
- VV 其他动词
- AD 副词
- M 量词
词法分析计算
-
求链长

-
算分词正确率、召回率

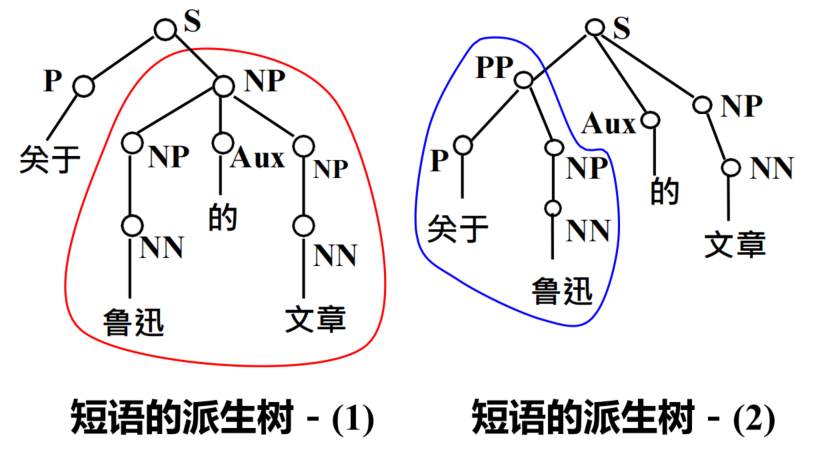
句法分析
句法分析的任务:识别句子的句法结构
- 句法分析的类型:短语结构分析(完全、局部)、依存句法分析
线图分析法


CYK
(1) 汉语分词和词性标注
(2) 构造识别矩阵
(3) 执行分析过程
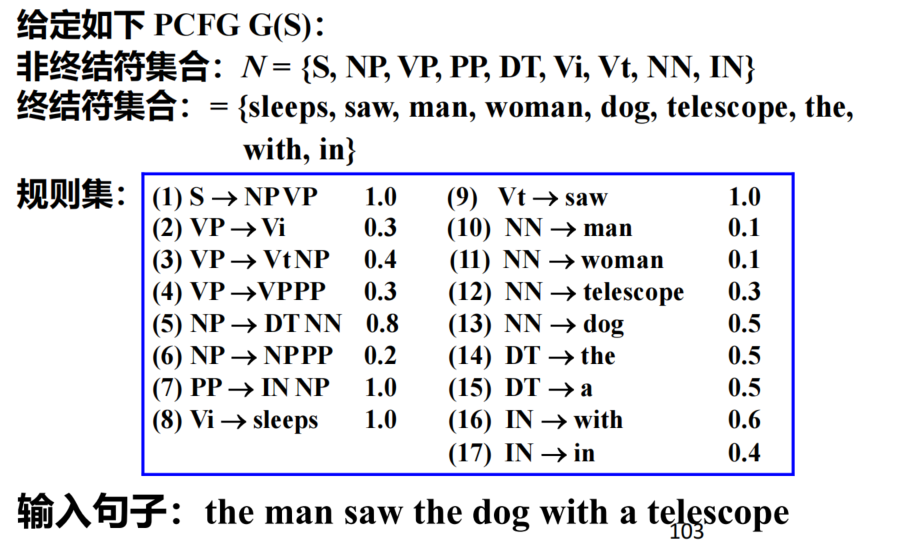
PCFG计算


- 根据规则,一步一步转换(可以倒推),树结构不唯一,看谁的概率大
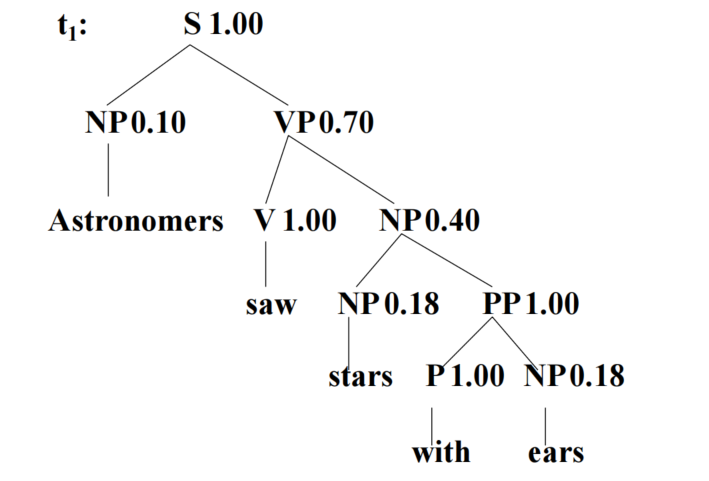
- 三大假设:位置不变性、上下文无关性、祖先无关性
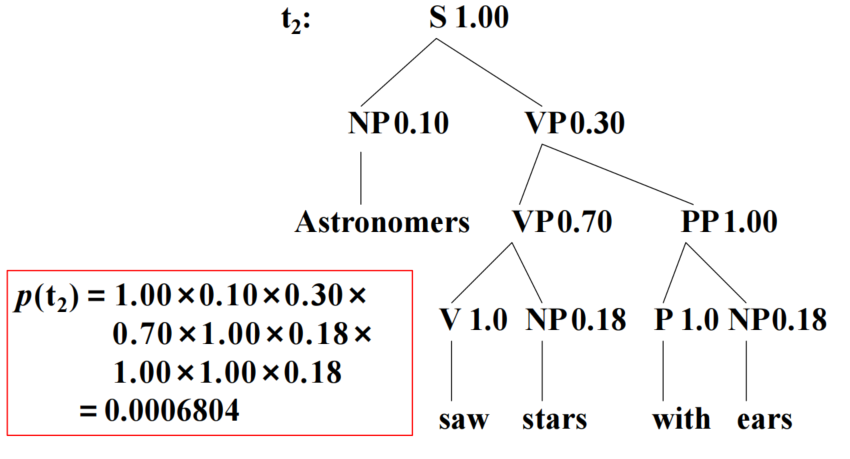
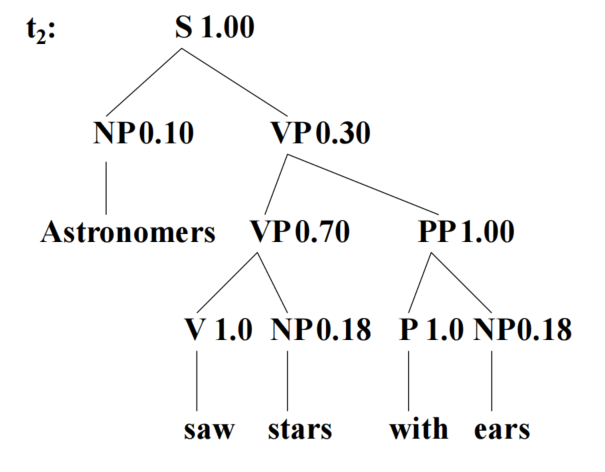
- 计算t1和t2的计算相关性

- 三个问题:

短语结构方法评估
- 内部评测:对评测方法本身的评测,用于指导句法分析系统及其语法的开发过程。
- 语法的覆盖性、平均分析基数、结构一致性、排序的一致性
- 对比评测:用于对比不同系统之间的性能差别
- 树相似性、模型的熵、语法评估兴趣小组
- 句法分析器性能评测:
- 精度
- 召回率
- F指标
- 交叉括号数


语义分析
- 语义分析的基本任务及其面临的困难
- 语义计算研究概括及常见的语义理论(
已考) - 格语法(定义、格框架约束分析)
- 语义网络(概念、关系、语义网络表示、事件的语义关系、基于语义网络的推理分析)
- CD 理论(三个层次:基本动作、剧本、计划)
- 词义消歧(规则方法、统计方法、词典法)
- 语义角色标注的基本概念和方法
- 词向量表示
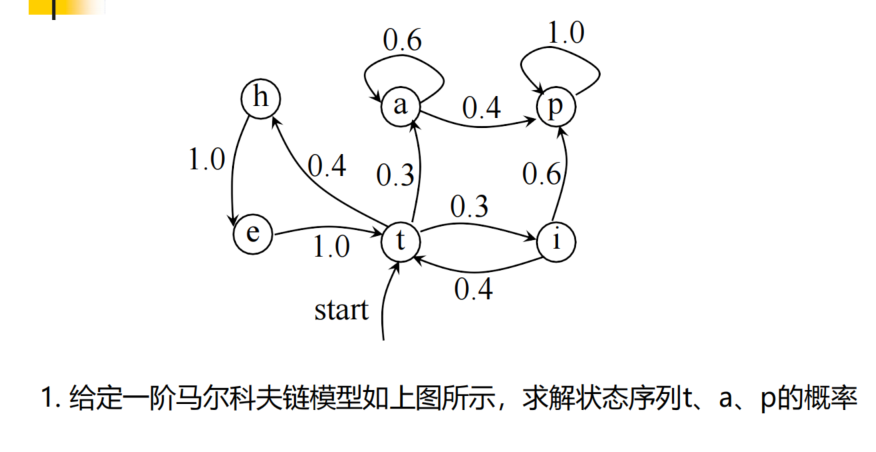
马尔可夫模型

CRFs
实现 CRFs 也需要解决如下三个问题:
特征选取、参数训练、解码




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









