




缺失值处理
发现缺失值
拿到数据的第一步,判断是否存在缺失数据,以及字段的缺失值占比
缺失率:用shape()和count()函数做差得到数据的缺失值个数,再除以样本总个数
定性:df.info:查看总体数据,对比一下就知道哪里少了
定量:
LossRate=all.shape[0]−loss[column]all.shpae[0] LossRate = \frac {all.shape[0]-loss[column]} {all.shpae[0] } LossRate=all.shpae[0]all.shape[0]−loss[column]
- 案例分析:
#缺失率计算
(user_info.shape[0]-user_info['age_range'].count())/user_info.shape[0]
#查看总数量
user_info[user_info['age_range'].isna() | (user_info['age_range'] == 0)].count()
缺失值处理
| 方法 | 说明 |
|---|---|
| dropna | 根据各标签是否存在缺失数据进行过滤,可通过法制调节对缺失值的容忍度 |
| fillna | 指定值或者指定方法,ffill或者bfill (前向填充或者) |
| isnull | 返回bool型对象 |
| notnull | isnull的否定 |
填充方法经验:
- 使用统计量填充:
- 连续值:推荐使用中位数,排除过大过小值的影响
- 离散值:推荐使用众数,不能用均值和中位数
- 特殊值处理:
填一个不正常的取值进行标识,如0,-1 - 不处理:
XGB和LGB等集成树模型对缺失值并不敏感,不需要你处理算法内部以及封装好了
常用缺失值填充方法:
| 插补方法 | 说明 | 优点 | 缺点 | 使用场景 |
|---|---|---|---|---|
| 均值填充 | 平均值 | 被插补的值比较稳定 | 不能反映缺失值的变异性,低估资料变异 | 低缺失率首选 |
| 随机插补 | 聚类填充:使用所有可能值填充;组合完整化方法 | 能体现变异性 | 依赖于观测值 | 低缺失率 |
| 回归插补 | 基于完整的数据集,建立回归模型 | 方差估计好 | 稳定性依赖于辅助变量,误差来源于抽样误差,不好控制 | 变量之间相关性强 |
| EM算法 | 通过观测数据的边缘分布对未知参数进行极大似然估计 | 利用充分,考虑了缺失值的不确定性 | 计算复杂 | 高缺失率 |
| 多重插补MCMC | 估计出插补的值,然后加上不同的噪声,形成多组可选的插补值 | 利用充分 | 计算复杂 | 高缺失率首选 |
异常值
看一下异常值:
单变量:
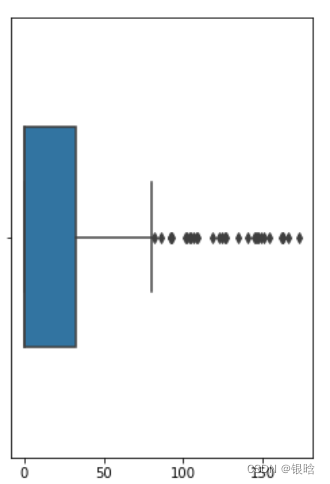
多变量:
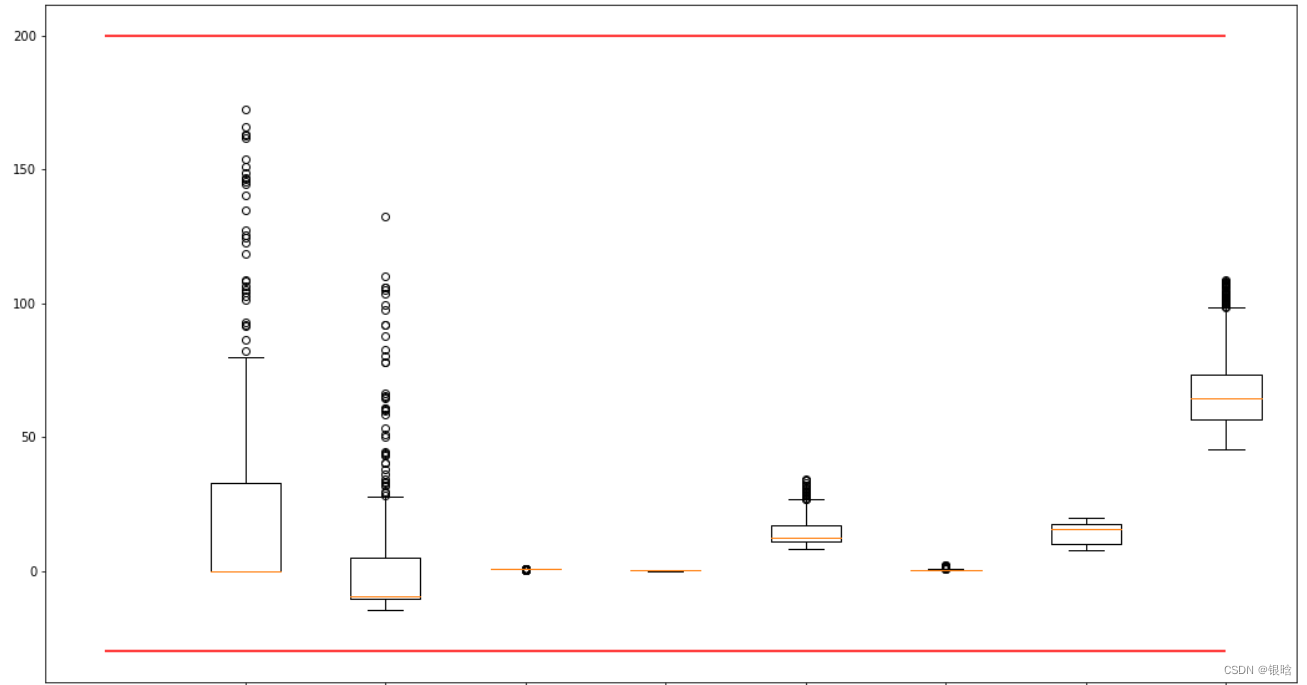
如何处理?
- 删除:如果是输入误差、数据处理误差引起的异常值,或者异常值很小,直接删除
- 转换:例如对数据取对数,可以减轻由极值引起的变化
- 填充:先索引出异常值,然后使用类似缺失值处理的填充方法
- 区别对待:异常值单独拿出来,非异常值放一起,分别训练模型取预测
变量转换的方法
常用的几个:
- 缩放比例或标准化;
MinMax=Xi−MinMax−MinMinMax = \frac{X_{i}-Min}{Max-Min} MinMax=Max−MinXi−Min
Standard=Xi−μσStandard = \frac{X_{i}- \mu}{\sigma}Standard=σXi−μ
- 归一化:
Normolize=x∑jmxj2Normolize = \frac{x}{\sqrt{\sum_{j}^{m}x_{j}^2}}Normolize=∑jmxj2x
使用场景:
- 对输出结果范围有要求,用归一化
- 数据较为稳定,不存在极大值极小值,用归一化
- 数据存在较多异常值和噪声,用标准化
- 常见的机器学习模型都要归一化或者标准化(树模型除外)
- 非线性关系转换为线性:对数变化就是一个
- 使倾斜分布对称:对于向右倾斜的分布采用平方根、立方根或者对数;对于向左分布,去平方、立方或指数
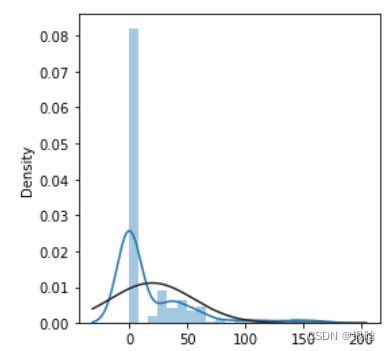
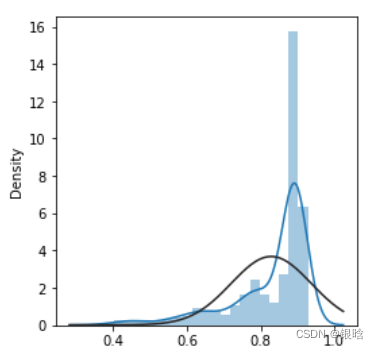
- 再来个比较飘的
- 变量分组:根据不同的目标吧变量按不同类别分组 ;离散型:打标签分类;连续型:one-hot编码
样本不平衡问题
- 随机欠采样
- 随机过采样
基于复制的方法随机增加少数类,或者随机减少多数类;
问题:正确率非常的高,你应该非常的高兴,可惜这是过拟合的表现!
- 基于聚类的过采样
依据聚类中心进行过采样方法/欠采样使得原始类中的集群样本数目相同
以聚类方法作为媒介,在一定程度上缓解了类间不平衡的问题,同时缓解了类内不平衡的问题。
问题:容易过拟合
- SMOTE算法:人工制造相似样本取代直接复制
- 计算少量样本与所有样本的距离
- 设定样本不平衡的过采样倍率,找到距离最近的k个样本
缺点:距离度量,没用考虑近邻样本是不同类的
- 基于数据清洗的SMOTE算法(封装了Tomek Links方法)
光说不练是瞎bb,show you code
import pandas as pd
from imblearn.over_sampling import SMOTE # 过抽样处理库SMOTE
from imblearn.under_sampling import RandomUnderSampler # 欠抽样处理库RandomUnderSampler
from sklearn.svm import SVC #SVM中的分类算法SVC
from imblearn.ensemble import EasyEnsembleClassifier # 简单集成方法EasyEnsemble
我已经对缺失值进行处理,我要处理的变量现在数据标签分为0,1两类
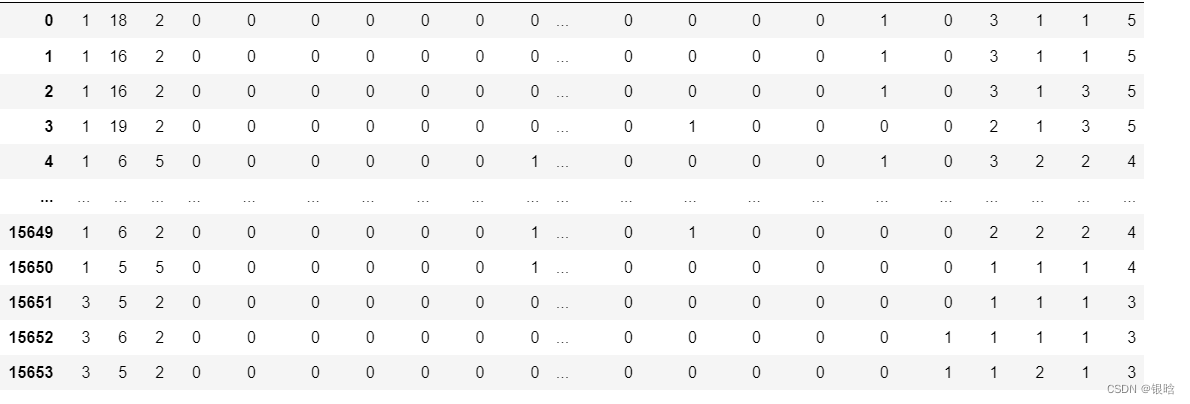
拿出我要处理的列:

这岂止是不平衡哈哈哈哈哈哈哈哈哈哈
直接复制的方法我就不写代码了,害人害己,准确率贼高还贼高兴好吧
from imblearn.over_sampling import RandomOverSampler, SMOTE
from collections import Counter
smo = SMOTE(random_state=0)
X_oversampled, y_oversampled = smo.fit_resample(X,y)
print(Counter(y_oversampled))
- 处理到1:1,平衡状态
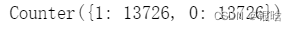
- SMOTE进阶:
from imblearn.combine import SMOTEENN
smo_tnn = SMOTEENN(random_state=0)
X_oversampled_1, y_oversampled_1 = smo_tnn.fit_resample(X,y)
print(Counter(y_oversampled_1))
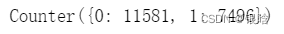
1:1不一定是完美的哦,有时候1:1.5比1:1好
这是二分类的很简单,那完美可视化观察一下多分类的情况:
处理前:
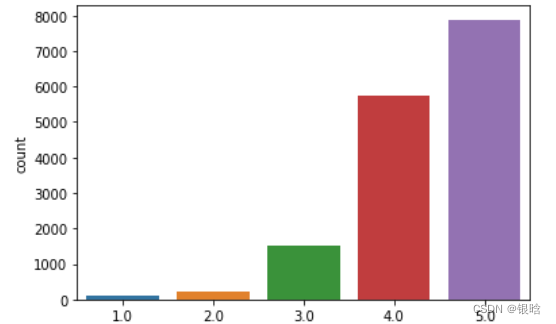
处理后:
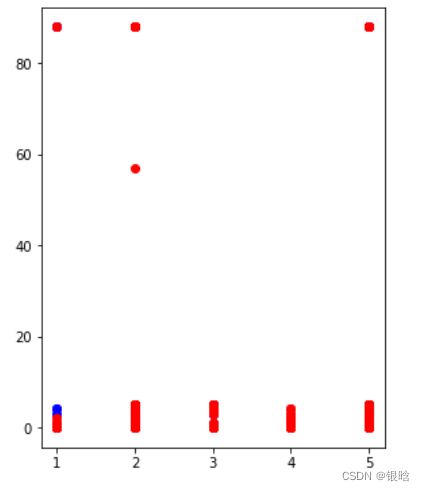
- 蓝色是插入的,很显然补充了少数类
不平衡算法处理之前的效果:
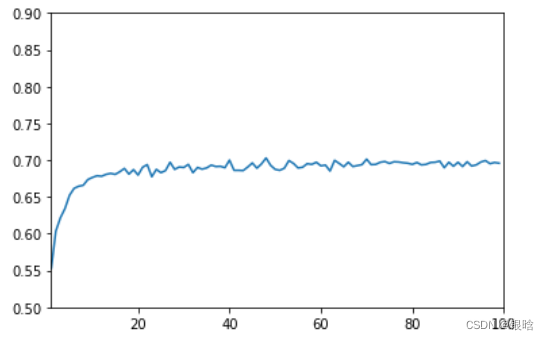
参数任你怎么,上不去嘿嘿嘿!!!
我们来可靠算法经过处理后的表现:
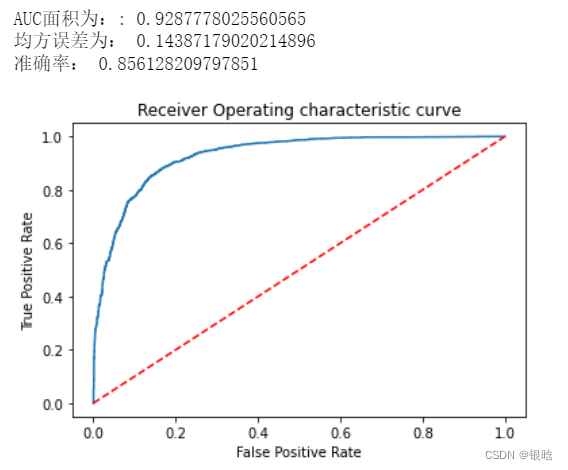
- 准确率不是越高越好,多分类用AUC度量可靠一点,瞅瞅ROC曲线
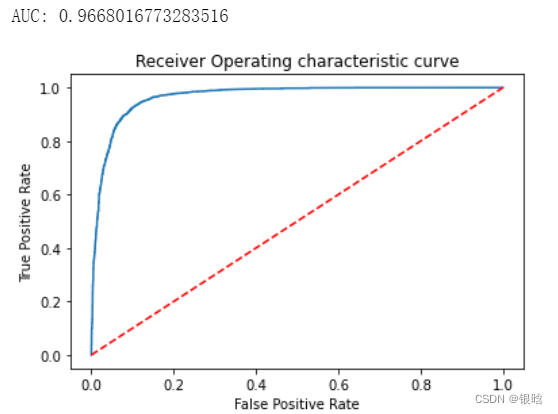
XBG算法已经完美了!
聚类下采样
from imblearn.under_sampling import ClusterCentroids
clu = ClusterCentroids(random_state=0)
X_undersampled, y_undersampled = clu.fit_resample(X,y)
print(Counter(y_undersampled))
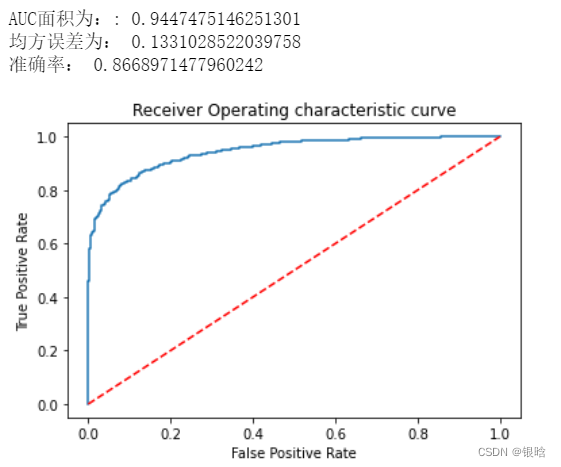
效果也不差,不过你注意一下过拟合的问题
说了半天过拟合,那怎么知道
- 交叉验证的效果一眼便知
交叉验证的效果均值较大,原因分析:
数据量小,数据分布受偶然、特殊数据的影响大,此时扩充数据可以有明显改善,条件不允许的话只能增加折数,从而消除单个模型的不稳定性
考虑不同模型的融合
数据是按时间的顺序储存的,数据集没有打乱的话,每个时间的数据都是不同时间的范围的,在实际问题中不同时间范围内的数据本来就存在很大的不同
验证集的分布本来就和测试集的分布不同


















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









