




RAG 流程复杂,涉及众多部分。如何确定现有的 RAG 方法及其最佳组合,以确定最佳 RAG 实践?
本文介绍了一项新研究,题为“寻找检索增强生成的最佳实践”。这项研究旨在解决这个问题。
本文主要分为四个部分,首先介绍典型的 RAG 流程,然后介绍每个 RAG 模块的最佳实践,最后进行综合评估,最后分享我的想法和见解,最后进行总结。
典型的 RAG 工作流程
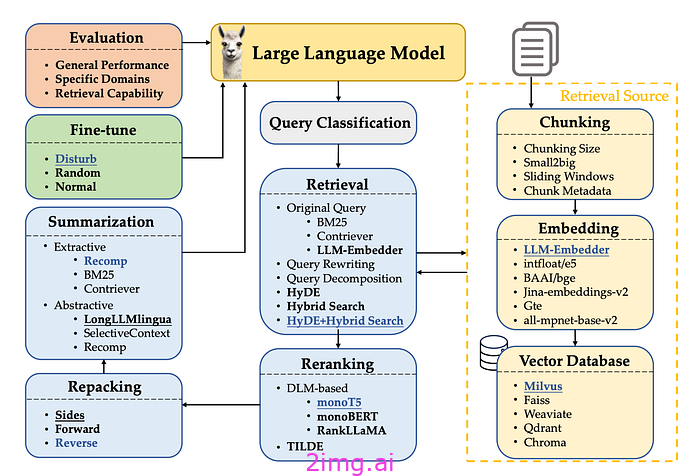
图 1:检索增强生成工作流程。每个组件考虑的可选方法以粗体表示,而带下划线的方法表示各个模块的默认选择。蓝色字体表示的方法表示经验确定的最佳选择。来源:寻找检索增强生成的最佳实践。
典型的 RAG 工作流程包括几个中间处理步骤:
- 查询分类(确定输入查询是否需要检索)
- 检索(高效获取相关文件)
- 重新排序(根据相关性优化检索到的文档的顺序)
- 重新打包(将检索到的文档组织成结构化形式)
- 总结(提取关键信息以生成响应并消除冗余)
实现 RAG 还涉及决定如何将文档分成块、选择使用哪些嵌入进行语义表示、选择合适的向量数据库进行高效的特征存储,以及找到微调 LLM 的有效方法,如图 1 所示。
每个步骤的最佳实践
查询分类
为什么需要查询分类?并非所有查询都需要检索增强,因为 LLM 具有某些功能。虽然 RAG 可以提高准确性并减少幻觉,但频繁检索会增加响应时间。因此,我们首先对查询进行分类,以确定是否需要检索。通常,当需要超出模型参数的知识时,建议进行检索。
我们可以根据任务是否提供足够的信息将任务分为 15 种类型,并展示特定的任务和示例。完全基于用户提供的信息的任务被标记为“足够”,不需要检索;否则,它们被标记为“不充分”,可能需要检索。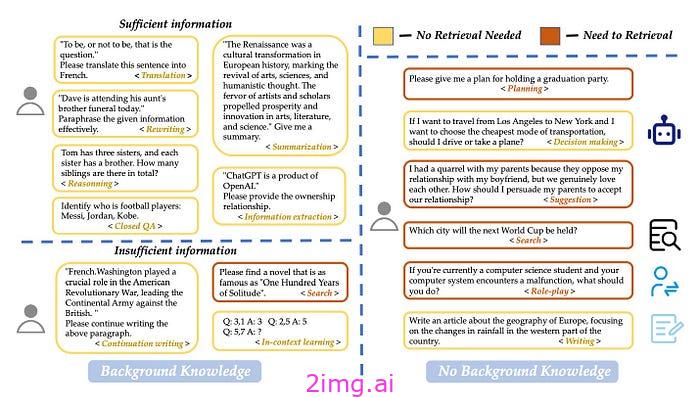
图 2:不同任务的检索需求分类。在未提供信息的情况下,我们根据模型的功能区分任务。来源:寻找检索增强生成的最佳实践。
该分类过程通过训练分类器实现自动化。

图 3:查询分类器的结果。来源:寻找检索增强生成的最佳实践。
分块
将文档分成较小的块对于提高检索准确性和避免 LLM 中的长度问题至关重要。通常有三个级别:
- 标记级分块很简单,但可能会分裂句子,从而影响检索质量。
- 语义级分块使用 LLM 来确定断点,保留上下文但需要更多时间。
- 句子级分块在保留文本语义与简洁高效之间取得平衡。
这里采用句子级分块来平衡简单性和语义保留。分块过程从以下四个维度进行评估。
区
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2167
2167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









