



介绍
- 大型语言模型 (LLM) 擅长生成连贯且上下文相关的文本,但在知识密集型查询方面却举步维艰,尤其是在特定领域和事实问答任务中。
- 检索增强生成 (RAG)系统通过集成结构化知识图谱 (KG) 等外部知识源来解决这一挑战。
- 尽管可以获得从 KG 中提取的信息,但 LLM 往往无法提供准确的答案。
- 最近的一项研究通过分析基于 KG 的 RAG 方法中的错误模式来研究这个问题,确定了八个关键失败点。
意图
研究发现,这些错误主要源于对问题意图的理解不足,因此从知识图谱事实中提取的上下文不足。
基于此分析,该研究提出了 Mindful-RAG,一个专注于基于意图和上下文一致的知识检索的框架。
这种方法旨在提高 LLM 响应的准确性和相关性,比当前方法有了重大进步。
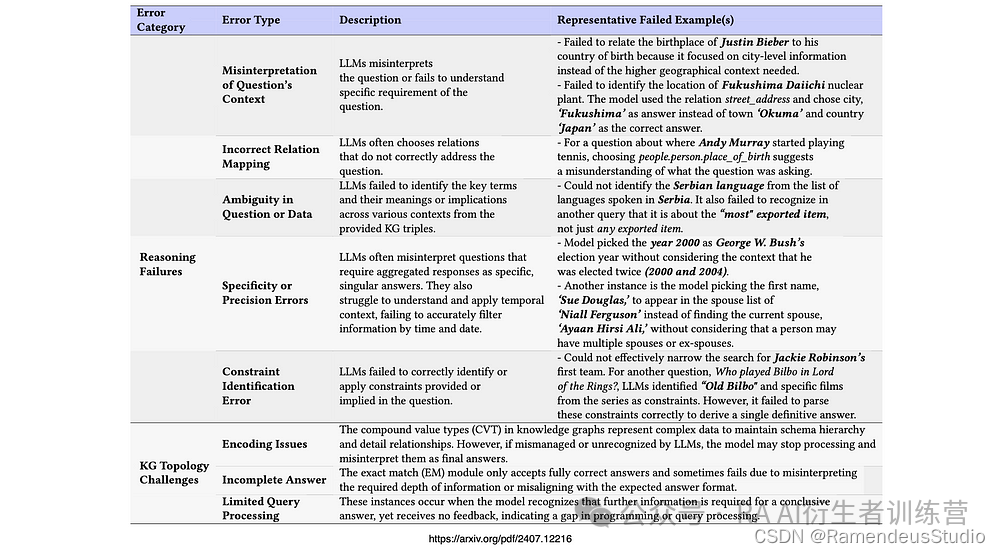
导致错误反应的八个失误点
下图显示了两个错误类别:推理失败和知识图谱、数据拓扑挑战。
列出了错误类型,并附有描述和失败示例……
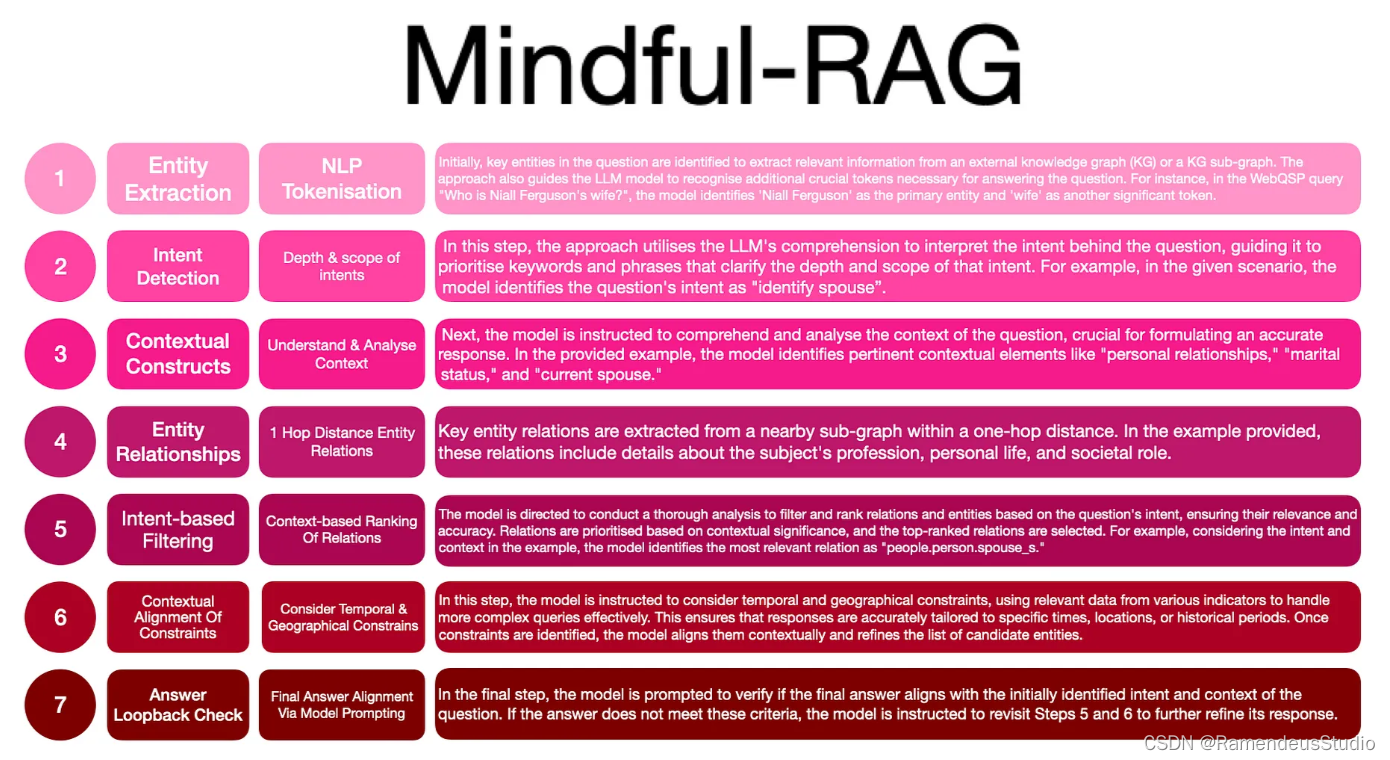
正念-RAG
Mindful-RAG 旨在解决两个关键差距:
- 问题意图的识别 &
- 背景与可用知识的一致性。
该方法采用一种战略混合方法,将模型的内在参数知识与来自知识图谱(KG)的非参数外部知识相结合。
以下步骤提供了设计和方法的全面概述,并辅以说明性示例。
知识图谱和向量
研究指出,将基于向量的搜索技术与基于KG的子图检索相结合,有可能显著提高性能。
意图识别和上下文对齐方面的这些进步表明了有希望的研究途径,可以极大地提高 LLM 在各个领域的知识密集型问答任务中的表现。
综上所述
- 与向量数据库相比,该研究更侧重于 RAG 的知识图谱 (KG) 实现。
- 就这两种方法而言,我并不是最好的方法的专家,因此欢迎任何反馈。
- Mindful-RAG 方法似乎更加以 KG 为导向,其中更多结构化数据本体和数据关系构成了实现的一部分。
- 利用KG需要的复杂数据关系。
- 就如何在 RAG 流程的上游使用自然语言处理 (NLP) 而言,这种方法仍然具有指导意义。
- 回送步骤非常有益,其中最终答案通过 LLM 检查来验证。
- 此外,知识图谱(KG)的使用极大地帮助了复杂问题的回答和相互关系的追踪。

 欢迎前往我们的公众号,阅读更多时事资讯
欢迎前往我们的公众号,阅读更多时事资讯

创作不易,觉得不错的话,点个赞吧!!!

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









