









 Transformer-XL是一种改进的Transformer模型,它通过段级循环和状态重用来处理长序列依赖,相比于RNN和标准Transformer,它能更好地捕捉长期依赖并显著提高处理速度。此外,模型利用相对位置编码来解决不同段间的位置信息问题,从而实现更高效的序列建模。
Transformer-XL是一种改进的Transformer模型,它通过段级循环和状态重用来处理长序列依赖,相比于RNN和标准Transformer,它能更好地捕捉长期依赖并显著提高处理速度。此外,模型利用相对位置编码来解决不同段间的位置信息问题,从而实现更高效的序列建模。
Abstract&Introduction&Related Work
- 研究任务
不受长度限制的transformer - 已有方法和相关工作
没有基于transformer的方法,都是基于RNN - 面临挑战
- 创新思路
- 实验结论
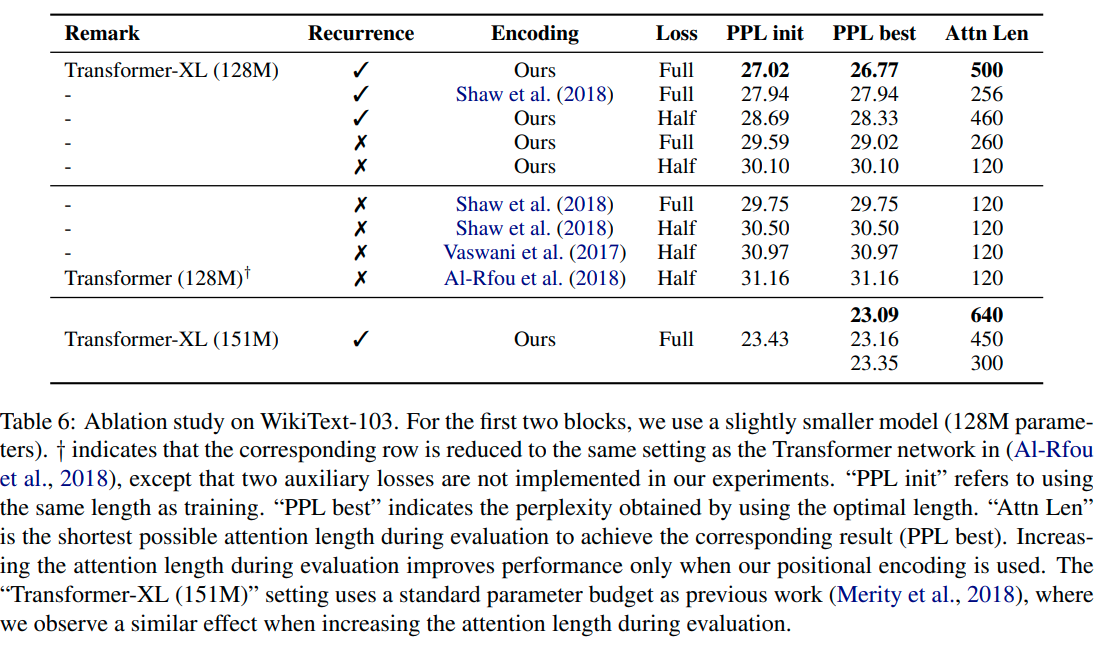
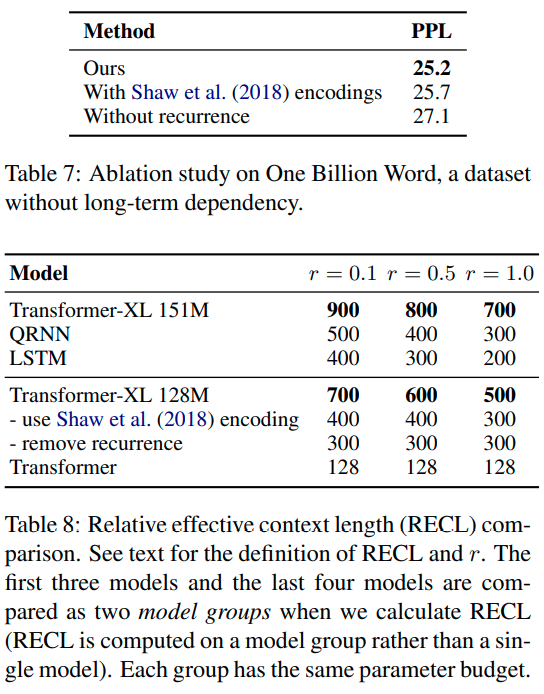
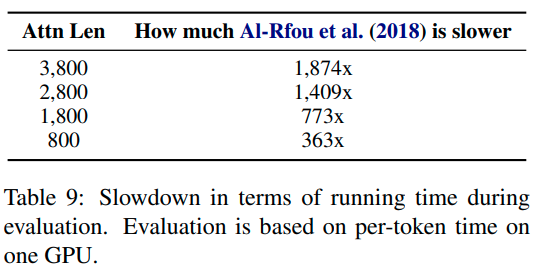
在学习依赖上优于RNN 80%,普通transformer 450%,评估速度比普通transformer快1800倍
Transformer-XL
Segment-Level Recurrence with State Reuse
在训练过程中,为前一个片段计算的隐藏状态序列是固定的,并在模型处理下一个新片段时作为扩展上下文被重新使用。
定义
s
τ
=
[
x
τ
,
1
,
⋯
,
x
τ
,
L
]
and
s
τ
+
1
=
[
x
τ
+
1
,
1
,
⋯
,
x
τ
+
1
,
L
]
\mathbf{s}_{\tau} = \left[x_{\tau, 1}, \cdots, x_{\tau, L}\right] \text { and } \mathbf{s}_{\tau+1}=\left[x_{\tau+1,1}, \cdots, x_{\tau+1, L}\right]
sτ=[xτ,1,⋯,xτ,L] and sτ+1=[xτ+1,1,⋯,xτ+1,L]
隐藏层,SG代表stop-gredient
h
~
τ
+
1
n
−
1
=
[
S
G
(
h
τ
n
−
1
)
∘
h
τ
+
1
n
−
1
]
,
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
=
h
τ
+
1
n
−
1
W
q
⊤
,
h
~
τ
+
1
n
−
1
W
k
⊤
,
h
~
τ
+
1
n
−
1
W
v
⊤
,
h
τ
+
1
n
=
Transformer-Layer
(
q
τ
+
1
n
,
k
τ
+
1
n
,
v
τ
+
1
n
)
.
\begin{array}{l} \widetilde{\mathbf{h}}_{\tau+1}^{n-1}=\left[\mathrm{SG}\left(\mathbf{h}_{\tau}^{n-1}\right) \circ \mathbf{h}_{\tau+1}^{n-1}\right], \\ \mathbf{q}_{\tau+1}^{n}, \mathbf{k}_{\tau+1}^{n}, \mathbf{v}_{\tau+1}^{n}=\mathbf{h}_{\tau+1}^{n-1} \mathbf{W}_{q}^{\top}, \widetilde{\mathbf{h}}_{\tau+1}^{n-1} \mathbf{W}_{k}^{\top}, \widetilde{\mathbf{h}}_{\tau+1}^{n-1} \mathbf{W}_{v}^{\top}, \\ \mathbf{h}_{\tau+1}^{n}=\text { Transformer-Layer }\left(\mathbf{q}_{\tau+1}^{n}, \mathbf{k}_{\tau+1}^{n}, \mathbf{v}_{\tau+1}^{n}\right) . \end{array}
h
τ+1n−1=[SG(hτn−1)∘hτ+1n−1],qτ+1n,kτ+1n,vτ+1n=hτ+1n−1Wq⊤,h
τ+1n−1Wk⊤,h
τ+1n−1Wv⊤,hτ+1n= Transformer-Layer (qτ+1n,kτ+1n,vτ+1n).
普通的transformer layer:

在隐藏层创造了segment-level的循环,与RNN不同的是,这里每段向下移动一层
最大可能的依赖是图b的面积下的点,与截断的BPTT不同的是,这里的方法缓存了一连串的隐状态,而不是最后一个,因此应该与相对位置编码技术一起应用
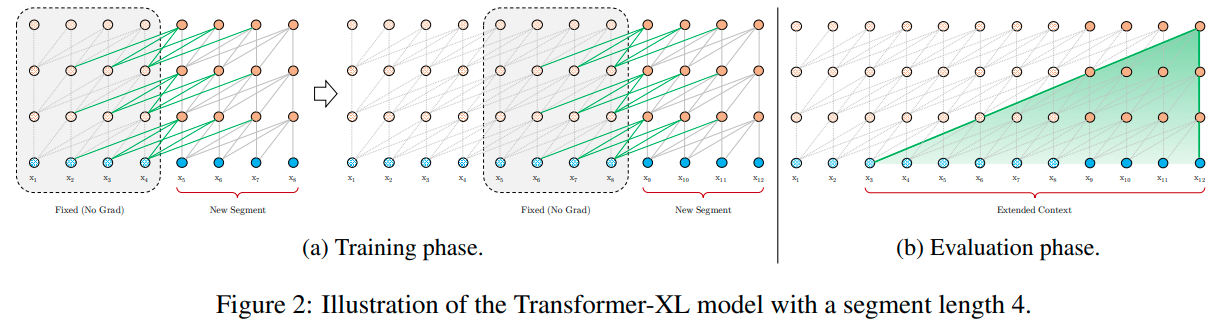
不只是前一个segment,可以与前多个segment相连
Relative Positional Encodings
当重用之前的state信息的时候,保持他们的位置信息也是非常重要的,如果依旧使用绝对位置编码,会出现两个segment用了同样的位置的情况,但实际上却差了一个segment的长度,这样会使模型无法区分他们的位置信息
h
τ
+
1
=
f
(
h
τ
,
E
τ
+
1
+
U
1
:
L
)
h
τ
=
f
(
h
τ
−
1
,
E
s
τ
+
U
1
:
L
)
,
\begin{array}{c}\mathbf{h}_{\tau+1}=f(\mathbf{h}_{\tau},\mathbf{E}_{\tau+1}+\mathbf{U}_{1:L})\\ \mathbf{h}_{\tau}=f(\mathbf{h}_{\tau-1},\mathbf{E}_{\mathbf{s}_{\tau}}+\mathbf{U}_{1:L}),\end{array}
hτ+1=f(hτ,Eτ+1+U1:L)hτ=f(hτ−1,Esτ+U1:L),
绝对位置编码:
A
i
,
j
q
is
=
E
x
i
⊤
W
q
⊤
W
k
E
x
j
⏟
(
a
)
+
E
x
i
⊤
W
q
⊤
W
k
U
j
⏟
(
b
)
+
U
i
⊤
W
q
⊤
W
k
E
x
j
⏟
(
c
)
+
U
i
⊤
W
q
⊤
W
k
U
j
⏟
(
d
)
.
\begin{array}{c}\mathbf{A}_{i,j}^{q\text{is}}=\underbrace{\mathbf{E}_{x_{i}}^{\top}\mathbf{W}_{q}^{\top}\mathbf{W}_{k}\mathbf{E}_{x_{j}}}_{(a)}+\underbrace{\mathbf{E}_{x_{i}}^{\top}\mathbf{W}_{q}^{\top}\mathbf{W}_{k}\mathbf{U}_{j}}_{(b)}+\underbrace{\mathbf{U}_{i}^{\top}\mathbf{W}_{q}^{\top}\mathbf{W}_{k}\mathbf{E}_{x_{j}}}_{(c)}+\underbrace{\mathbf{U}_{i}^{\top}\mathbf{W}_{q}^{\top}\mathbf{W}_{k}\mathbf{U}_{j}}_{(d)}.\end{array}
Ai,jqis=(a)
Exi⊤Wq⊤WkExj+(b)
Exi⊤Wq⊤WkUj+(c)
Ui⊤Wq⊤WkExj+(d)
Ui⊤Wq⊤WkUj.
相对位置编码:
把所有的
U
j
U_j
Uj 都换成了
R
i
−
j
\color{Cyan}{R_{i-j}}
Ri−j 一个正弦波编码矩阵
u
⊤
\color{red}u^\top
u⊤ 和
v
⊤
\color{red}v^\top
v⊤ 是可训练参数
A
i
,
j
r
e
l
=
E
x
i
⊤
W
q
⊤
W
k
,
E
E
x
j
⏟
(
a
)
+
E
x
i
⊤
W
q
⊤
W
k
,
R
R
i
−
j
⏟
(
b
)
+
u
⊤
W
k
,
E
E
x
j
⏟
(
c
)
+
v
⊤
W
k
,
R
R
i
−
j
⏟
(
d
)
.
\mathbf{A}_{i,j}^{\mathrm{rel}}=\underbrace{\mathbf{E}_{x_i}^{\top}\mathbf{W}_q^{\top}\mathbf{W}_{k,E}\mathbf{E}_{x_j}}_{(a)}+\underbrace{\mathbf{E}_{x_i}^{\top}\mathbf{W}_q^{\top}\mathbf{W}_{k,R}\color{Cyan}\mathbf{R}_{i-j}}_{(b)} +\underbrace{{\color{red}u^\top}\mathbf{W}_{k,E}\mathbf{E}_{x_j}}_{(c)}+\underbrace{{\color{red}{v^\top}} \mathbf{W}_{k,R}\color{Cyan}\mathbf{R}_{i-j}}_{(d)}.
Ai,jrel=(a)
Exi⊤Wq⊤Wk,EExj+(b)
Exi⊤Wq⊤Wk,RRi−j+(c)
u⊤Wk,EExj+(d)
v⊤Wk,RRi−j.
Transformer-XL的总公式
h
~
τ
n
−
1
=
[
S
G
(
m
τ
n
−
1
)
∘
h
τ
n
−
1
]
q
τ
n
,
k
τ
n
,
v
τ
n
=
h
τ
n
−
1
W
q
n
⊤
,
h
~
τ
n
−
1
W
k
,
E
n
⊤
,
h
~
τ
n
−
1
W
v
n
⊤
A
τ
,
i
,
j
n
=
q
τ
,
i
n
⊤
k
τ
,
j
n
+
q
τ
,
i
n
⊤
W
k
,
R
n
R
i
−
j
+
u
⊤
k
τ
,
j
+
v
⊤
W
k
,
R
n
R
i
−
j
a
τ
n
=
M
a
s
k
e
t
−
S
o
f
t
m
a
x
(
A
τ
n
)
v
τ
n
o
τ
n
=
l
a
y
e
r
N
o
r
m
(
L
i
n
e
a
r
(
a
τ
n
)
+
h
τ
n
−
1
)
h
τ
n
=
P
o
s
i
t
i
o
n
w
i
s
e
−
F
e
e
d
−
F
o
r
w
a
r
d
(
a
τ
n
)
\begin{array}{c}\widetilde{\mathbf{h}}_{\tau}^{n-1}=\left[\mathrm{SG}(\mathbf{m}_{\tau}^{n-1})\circ\mathbf{h}_{\tau}^{n-1}\right]\\ \mathbf{q}_{\tau}^{n},\mathbf{k}_{\tau}^{n},\mathbf{v}_{\tau}^{n}=\mathbf{h}_{\tau}^{n-1}\mathbf{W}_{q}^{n}{}^{\top},\widetilde{\mathbf{h}}_{\tau}^{n-1}\mathbf{W}_{k,E}^{n}{}^{\top},\widetilde{\mathbf{h}}_{\tau}^{n-1}\mathbf{W}_{v}^{n}{}^{\top}\end{array}\\ \begin{array}{c}\mathbf{A}^n_{\tau,i,j}=\mathbf{q}^n_{\tau,i}{}^{\top}\mathbf{k}^n_{\tau,j}+\mathbf{q}^n_{\tau,i}{}^{\top}\mathbf{W}^n_{k,R}\mathbf{R}_{i-j}\\ +u^{\top}\mathbf{k}_{\tau,j}+v^{\top}\mathbf{W}^n_{k,R}\mathbf{R}_{i-j}\end{array}\\ \begin{array}{l}\mathbf{a}_{\tau}^{n}=\mathbf{Masket-Softmax}(\mathbf{A}_{\tau}^{n})\mathbf{v}_{\tau}^{n}\\ \mathbf{o}_{\tau}^{n}=\mathbf{layerNorm}(\mathbf{Linear}(\mathbf{a}_{\tau}^{n})+\mathbf{h}_{\tau}^{n-1})\\ \mathbf{h}_{\tau}^{n}=\mathbf{Positionwise-Feed-Forward}(\mathbf{a}_{\tau}^{n})\end{array}
h
τn−1=[SG(mτn−1)∘hτn−1]qτn,kτn,vτn=hτn−1Wqn⊤,h
τn−1Wk,En⊤,h
τn−1Wvn⊤Aτ,i,jn=qτ,in⊤kτ,jn+qτ,in⊤Wk,RnRi−j+u⊤kτ,j+v⊤Wk,RnRi−jaτn=Masket−Softmax(Aτn)vτnoτn=layerNorm(Linear(aτn)+hτn−1)hτn=Positionwise−Feed−Forward(aτn)
Experiments
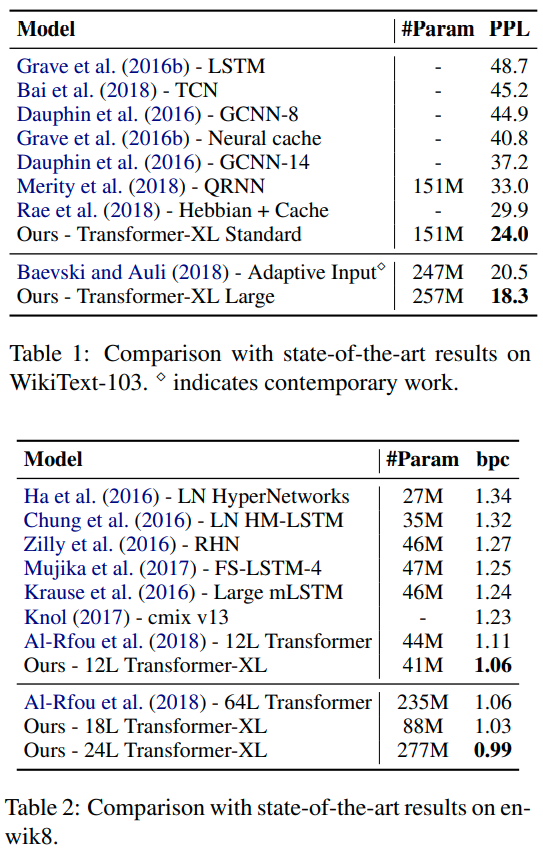
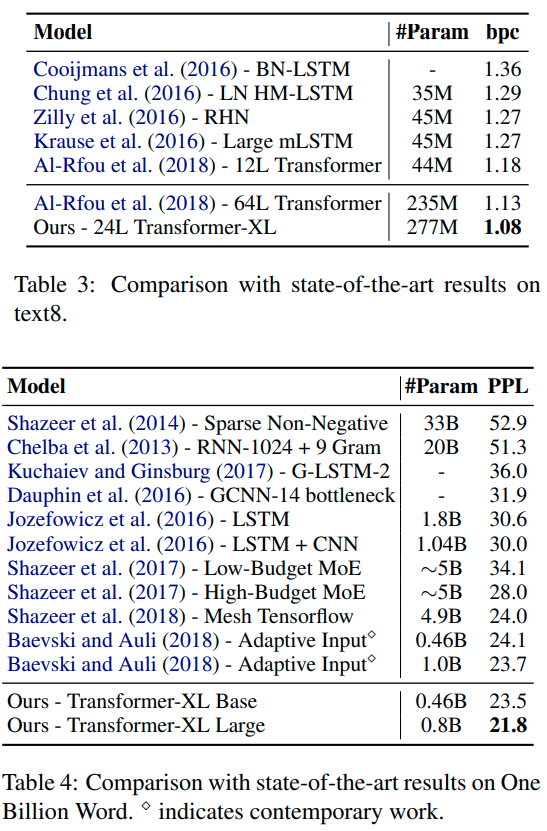
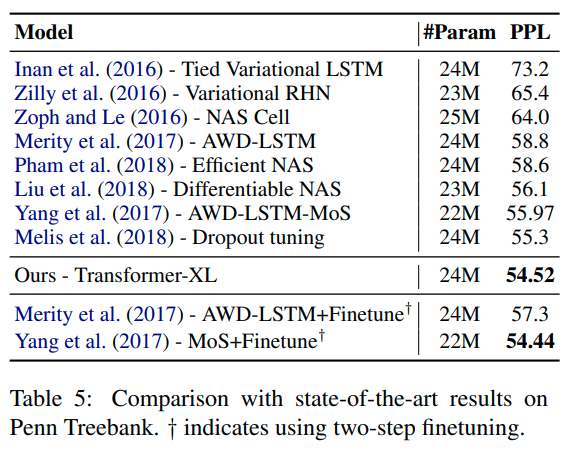
Conclusions
Transformer-XL获得了强大的困惑度结果,比RNN和Transformer建立了更长期的依赖关系,在评估过程中实现了大幅提速,并且能够生成连贯的文本文章。我们设想Transformer-XL在文本生成、无监督的特征学习、图像和语音建模等领域的有趣应用
Remark
话好多。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









