







 本文详细介绍如何在三节点集群上安装配置Hadoop,包括IP地址设置、SSH无密码登录配置、JDK与Hadoop环境变量设置及核心配置文件修改。
本文详细介绍如何在三节点集群上安装配置Hadoop,包括IP地址设置、SSH无密码登录配置、JDK与Hadoop环境变量设置及核心配置文件修改。
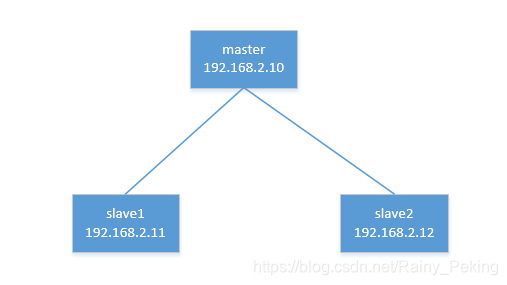
〇、集群结构及IP地址
安装前准备
此次安装是分布式安装,使用三节点(一个主节点,两个从节点)。
操作系统为:Ubuntu 16.04LTS。
0)修改每台机器的IP地址
#修改配置文件interfaces
sudo vim /etc/network/interfaces
#为enp2s0网卡添加以下内容,具体名称看实际使用的网卡名
auto enp2s0
iface enp2s0 inet static #IP获取为静态设置
address 192.168.2.10 #根据配置的机器填写IP
netmask 255.255.255.0 #子网掩码
broadcast 192.168.2.255
gateway 192.168.2.1 #集群路由器地址
dns-nameservers 114.114.114.114 #DNS服务器地址
1)为每台机器安装vim编辑器,默认自带为vi编辑器
sudo apt install vim2)修改主机名
#1.分别在三台机器上修改hostname,将主节点修改为master,两个从节点分别为slave1,slave2
sudo vim /etc/hostname
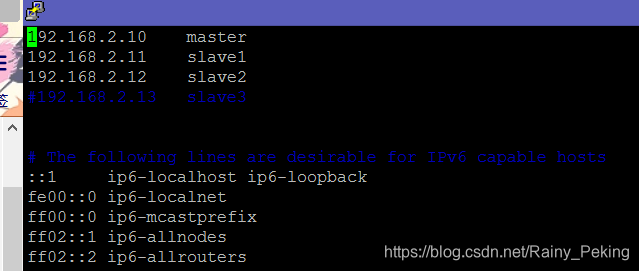
#2.分别在三台机器上修改hosts文件
#将hosts文件中已有的 127.0.0.1 localhost 行删掉(切记),下面IPV6的东西不用动
#增加内容
192.168.2.10 master
192.168.2.11 slave1
192.168.2.12 slave2修改hostname


修改hosts
3)更改系统时区
在三台机器上分别操作
#更改系统时区,根据提示选择AsiaChinaBeijing Timeyes
sudo tzseletct
#将Asia/Shanghai/shell scripts复制到/etc/localtime中
sudo cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
以上所有的配置完成之后重启三台机器!!!
4)集群之间ssh无秘钥登录
1、在三台机器上分别安装ssh server
#在三台机器上分别安装ssh
sudo apt install ssh
sudo apt install openssh-server
sudo apt install rsync
#在master机器上执行,生成公钥
ssh-keygen -t rsa
#将公钥发送到slave1,slave2主机
ssh-copy-id -i ~/.ssh/id_rsa.pub slave1
ssh-copy-id -i ~/.ssh/id_rsa.pub slave2
#验证,无需使用密码即可ssh登录,否则说明配置不成功
ssh slave1
一、相关文件下载
1.JDK下载以及环境变量设置
1)JDK下载:此次安装使用的JDK是1.8.0_144版本的(根据操作系统选择合适的安装包),下载地址。
2)环境变量设置:将下载好的JDK解压到/opt文件夹下,接下来修改环境变量。
#修改profile配置文件
sudo vim /etc/profile
#增加以下内容
export JAVA_HOME=/opt/jdk1.8.0_144
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#JAVA_HOME以JDK使用版本号以及存放具体位置为准3)验证JDK是否配置成功
java -version2.Hadoop包下载
1)Hadoop安装包下载:点击此处,本次安装的版本为2.7.2
2)将下载好的压缩包解压到/opt目录下
3)配置Hadoop环境变量:
#修改profile文件
sudo vim /etc/profile
#增加以下内容
export HADOOP_HOME="/opt/hadoop-2.7.2" #以实际存放目录及版本号为准
export PATH="$HADOOP_HOME/bin:$PATH"
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
3.两台slave机器JDK的配置
1.将JDK与Hadoop发送至另外两台机器
#将jdk文件夹下的文件复制到slave1的/opt目录下
sudo scp -r /opt/jdk1.8.0_144/ hadoop@slave1:/opt
sudo scp -r /opt/jdk1.8.0_144/ hadoop@slave2:/opt2.修改slave机器的profile文件,步骤同上。
二、Hadoop配置文件修改
1.Hadoop中的配置文件
| 文件名称 | 格式 | 描述 |
| hadoop-env.sh | Bash脚本 | 记录Hadoop运行所需的环境变量 |
| core-site.xml | XML | HDFS与MapReduce常用的I/O设置等 |
| hdfs-site.xml | XML | Hadoop守护进程配置项,包括NameNode、SecondaryNameNode、DataNode等 |
| mapred-site.xml | XML | MapReduce的守护进程,包括JobTracker与TaskTracker |
| slaves | 文本 | DataNode的主机名(每行填一个) |
| yarn-site.xml | XML | 配置项释义 |
2.具体修改方法
需要修改的配置文件在/opt/hadoop-2.7.2/etc/hadoop/路径下
1)hadoop-env.sh
vim ./hadoop-env.sh
#增加以下内容
export JAVA_HOME=/opt/jdk1.8.0_1442)配置slave文件
vim ./slaves
#增加以下内容
slave1
slave23)配置core-site.xml文件
vim ./core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- Size of read/write buffer used in SequenceFiles. -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!-- 指定hadoop临时目录,自行创建 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop/tmp</value>
</property>
</configuration>4)配置hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop/hdfs/data</value>
</property>
</configuration>
5)yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
6)配置mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:19888</value>
</property>
</configuration>3.将/opt/hadoop-2.7.2/etc/hadoop/路径下的配置文件发送至slave机器
sudo scp -r /opt/hadoop-2.7.2/etc/hadoop/ hadoop@slave1:/opt/hadoop-2.7.2/etc/hadoop/
sudo scp -r /opt/hadoop-2.7.2/etc/hadoop/ hadoop@slave2:/opt/hadoop-2.7.2/etc/hadoop/4.验证安装
1)格式化节点
hdfs namenode -format2)启动集群
#切换工作目录为/opt/hadoop-2.7.2/sbin
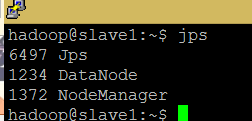
./start-all.sh3)查看运行进程
#在master与slave机器上分别执行查看
jps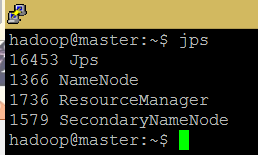
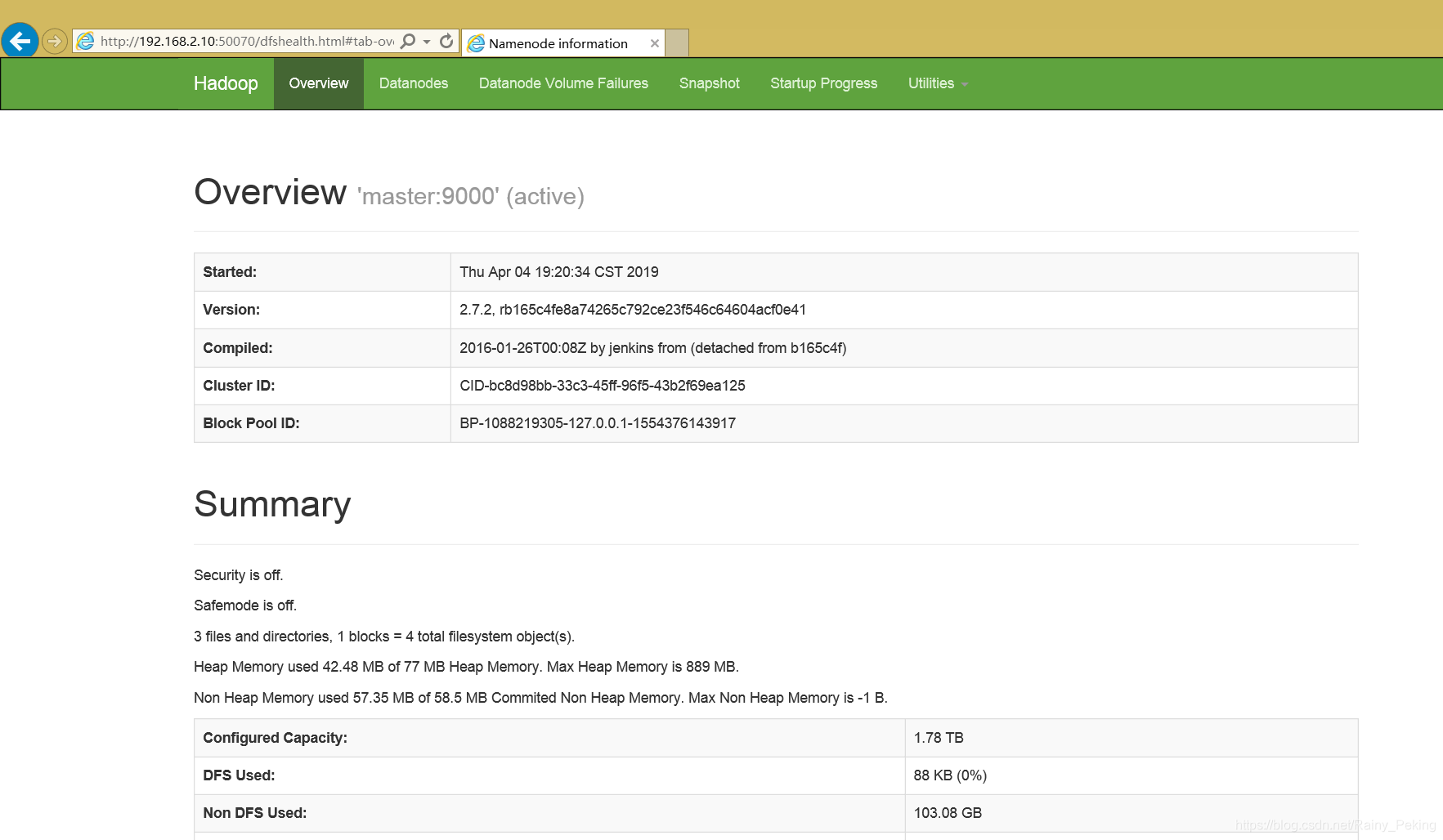
使用浏览器打开http://master:50070/

















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









