




在 PyTorch 中,所有神经网络模型都基于 nn.Module 构建。
在此基础上,我们通常通过以下三种方式来组织网络结构:
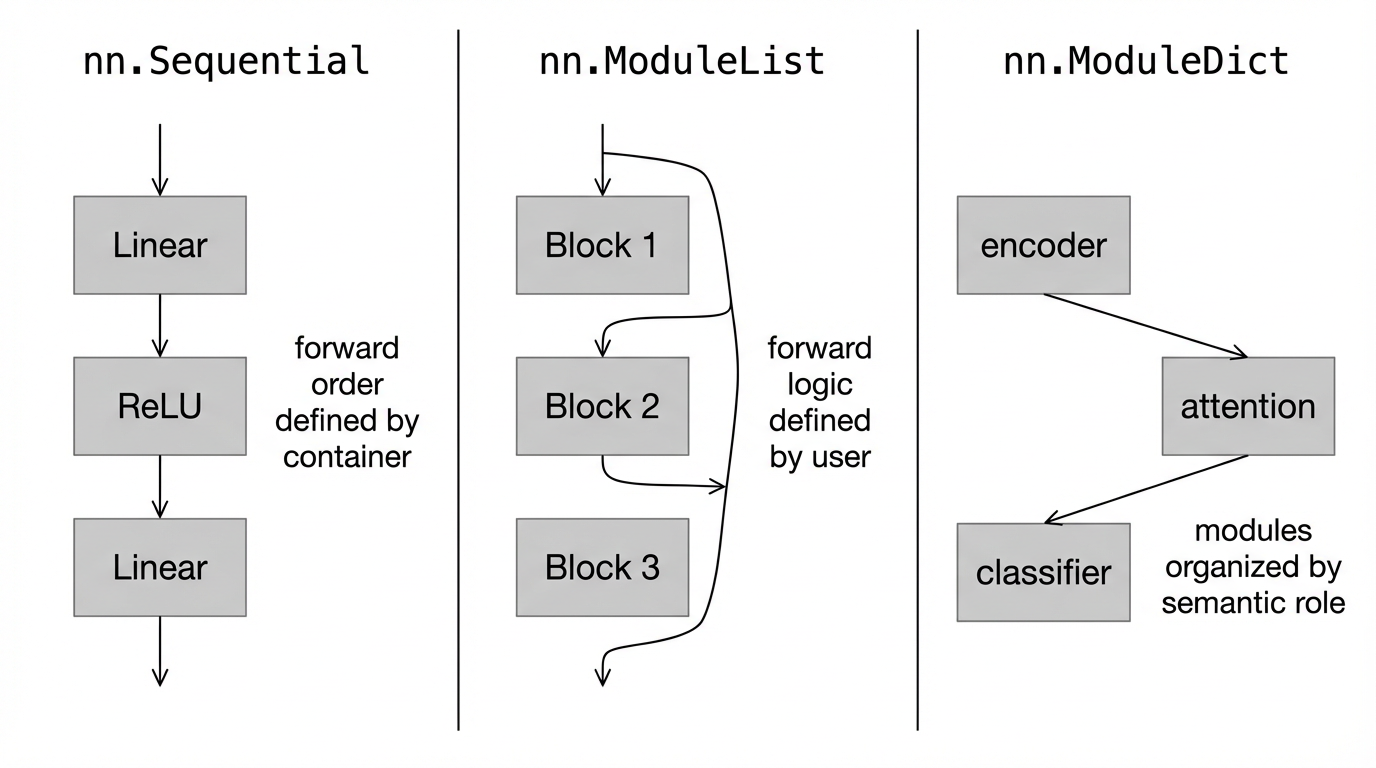
理解这三种容器的设计目的与使用边界,是写出清晰、可维护、可扩展模型代码的关键。
一、nn.Module 与模型的基本结构
nn.Module是torch.nn中提供的模型构造基类,所有神经网络层和模型都继承自它;- 一个标准的 PyTorch 模型通常包含两个核心部分:
- 结构定义:在
__init__中声明和注册子模块; - 数据流定义:在
forward中明确数据的前向传播路径。
- 结构定义:在
在此基础上,PyTorch 提供了多种“模块容器”,用来帮助我们更优雅地组织这些子模块。
二、三种组织方式的对比与适用场景
| 方式 | 是否自动定义 forward | 是否有顺序 | 是否灵活 |
|---|---|---|---|
Sequential | ✅ 是 | ✅ 固定顺序 | ❌ 低 |
ModuleList | ❌ 否 | ⚠️ 仅存储顺序 | ✅ 高 |
ModuleDict | ❌ 否 | ❌ 无隐含顺序 | ✅ 高 |
- Sequential
适合用于 结构已确定、仅做快速验证或标准模块封装 的场景; - ModuleList / ModuleDict
适合:- 同一结构重复多次
- 层数可变
- 需要在
forward中显式控制数据流(如残差、分支、多尺度)
三、Sequential
nn.Sequential 是一个 有序的模块容器,用于将多个子模块按顺序串联起来,形成一个整体模块。
当模型的前向传播逻辑是严格的线性串联时,Sequential 可以显著简化代码结构。
- 核心特性:
Sequential中模块的前向计算顺序,与其被添加到容器中的顺序完全一致。
3.1 Sequential 的内部实现逻辑(简化版)
class MySequential(nn.Module):
def __init__(self, *args):
super(MySequential, self).__init__()
if len(args) == 1 and isinstance(args[0], OrderedDict):
for key, module in args[0].items():
self.add_module(key, module)
else:
for idx, module in enumerate(args):
self.add_module(str(idx), module)
def forward(self, input):
for module in self._modules.values():
input = module(input)
return input
add_module会将子模块注册到self._modules(一个OrderedDict)中;forward只是按顺序遍历并调用这些模块;- 因此,
Sequential本质上是一个**“自动写好 forward 的 Module”**。
3.2 Sequential 的两种常见定义方式
(1) 直接按顺序排列
import torch.nn as nn
net = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 10),
)
print(net)
Sequential( (0): Linear(in_features=784, out_features=256, bias=True) (1): ReLU() (2): Linear(in_features=256, out_features=10, bias=True) )
(2) 使用 OrderedDict 显式命名
import collections
import torch.nn as nn
net = nn.Sequential(collections.OrderedDict([
('fc1', nn.Linear(784, 256)),
('relu1', nn.ReLU()),
('fc2', nn.Linear(256, 10))
]))
print(net)
Sequential(
(fc1): Linear(in_features=784, out_features=256, bias=True)
(relu1): ReLU()
(fc2): Linear(in_features=256, out_features=10, bias=True)
)
-
为什么这里要使用
OrderedDict?OrderedDict是一种 显式保持插入顺序的字典结构。 在nn.Sequential中,这一点非常重要。从内部实现可以看到,
Sequential的前向传播本质上是:for module in self._modules.values(): x = module(x) 也就是说,
Sequential并不依赖模块的名字来决定计算逻辑;它真正依赖的是, 模块在容器中的遍历顺序。 当使用
OrderedDict时,我们同时获得了两点好处:- 前向执行顺序是确定且可依赖的
- 每一层都有明确的语义名称,提升可读性和可维护性
虽然在 Python 3.7+ 中,普通 dict 也保证插入顺序,但在 PyTorch 的设计中,凡是**“顺序本身具有语义”的地方**,都会显式使用 OrderedDict,以避免歧义。换句话说:使用 OrderedDict 并不是为了“让 Sequential 有顺序”,而是为了 让顺序成为一种明确、可阅读、可依赖的设计约定。
3.3 优缺点总结
- ✅ 优点
- 代码简洁、可读性高
- 适合标准模块(Conv + BN + ReLU 等)
- 无需手写
forward
- ❌ 缺点
- 灵活性受限
- 无法方便地插入分支、跳连或外部输入
- 不适合复杂拓扑结构(ResNet、UNet 等)
四、 ModuleList
对应容器:
nn.ModuleList
nn.ModuleList 是一个 模块的列表容器,用于保存多个子模块,但不会自动定义前向传播逻辑。这也是它与 Sequential 的本质区别。
4.1 ModuleList 的核心定位
ModuleList 是“参数级别的容器”,而不是“计算图级别的容器”。
-
具体来说,它会正确注册子模块,使参数出现在
model.parameters()/state_dict()中。但它不会决定模块之间的执行顺序,自动参与前向传播。 -
它的主要作用是:
-
注册参数
-
方便重复结构的声明
-
将控制权完全交给 forward
-
4.2 基本用法示例
import torch.nn as nn
net = nn.ModuleList([
nn.Linear(784, 256),
nn.ReLU()
])
net.append(nn.Linear(256, 10))
print(net[-1])
print(net)
Linear(in_features=256, out_features=10, bias=True) ModuleList( (0): Linear(in_features=784, out_features=256, bias=True) (1): ReLU() (2): Linear(in_features=256, out_features=10, bias=True) )
此时需要特别注意:ModuleList 中模块的排列顺序,本身并不等价于它们在网络中的计算顺序。
4.3 为什么 ModuleList 不自动 forward?
这是很多人第一次用 ModuleList 时最容易困惑的地方。
原因并不复杂,因为Sequential 的设计前提是:网络结构是严格线性的;而 ModuleList 的设计目标是:
允许前向传播逻辑是动态的、可编程的。
- 例如:
- 跳跃连接(ResNet)
- 多分支结构
- 条件执行
- 不同层之间的特征融合
- 这些结构无法用“固定顺序”描述,因此PyTorch 干脆不替你定义 forward,而是把控制权完全交还给用户。
4.4 一个完整示例
class MyModel(nn.Module):
def __init__(self, input_size, hidden_sizes, output_size):
super().__init__()
layers = []
layers.append(nn.Linear(input_size, hidden_sizes[0]))
layers.append(nn.ReLU())
for i in range(1, len(hidden_sizes)):
layers.append(nn.Linear(hidden_sizes[i-1], hidden_sizes[i]))
layers.append(nn.ReLU())
layers.append(nn.Linear(hidden_sizes[-1], output_size))
self.layers = nn.ModuleList(layers)
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
从这里可以清楚地看到,ModuleList 负责 “模块存在”,forward 负责 “模块怎么连”
因此,当“层的数量或连接方式”需要在 forward 中被显式控制时,ModuleList 几乎是唯一合理的选择。
五、 ModuleDict
对应模块:
nn.ModuleDict
如果说 ModuleList 解决的是 “同类模块的重复组织”,那么 ModuleDict 解决的则是:“按语义而不是按顺序组织模块”。
5.1 ModuleDict 的核心思想
nn.ModuleDict 是一个 以名称为键的模块容器:
import torch.nn as nn
net = nn.ModuleDict({
'linear': nn.Linear(784, 256),
'act': nn.ReLU(),
})
net['output'] = nn.Linear(256, 10)
从形式上看,它很像一个普通的 dict,但二者在语义上有着本质区别。
ModuleDict 相比普通 dict,额外承担了 “模块注册” 的职责:
-
子模块会被正确注册为模型的一部分
-
对应参数会自动出现在
state_dict中 -
能被 PyTorch 的训练、保存、加载、优化器等机制完整识别
换句话说,ModuleDict 不是为了“存对象”,而是为了“存模型结构”。
5.2 基于名称访问模块
使用 ModuleDict 的一个直接好处是:可以通过语义明确的名称来访问网络中的子模块。
print(net['linear']) # 访问
Linear(in_features=784, out_features=256, bias=True)
这种访问方式在以下场景中特别有价值:
-
网络中存在多个功能不同的分支
-
模块的“角色”比“位置”更重要
-
forward 中需要根据条件选择不同子模块
5.3 ModuleDict 并不定义“顺序”
这一点非常重要,也非常容易被误解。
print(net)
ModuleDict( (linear): Linear(in_features=784, out_features=256, bias=True) (act): ReLU() (output): Linear(in_features=256, out_features=10, bias=True) )
ModuleDict 中模块的“排列”不代表任何计算顺序语义。真正的执行逻辑,依然必须在 forward 中明确指定。
-
与
Sequential不同:ModuleDict不会自动决定前向传播的执行顺序- 模块之间的调用关系,必须在
forward中显式给出
def forward(self, x): x = self.layers['linear'](x) x = self.layers['act'](x) x = self.layers['output'](x) return x
5.4 为什么要用 ModuleDict,而不是 ModuleList?
两者的核心差异不在“能不能存模块”,而在建模视角:
-
ModuleList: 关注 “第 0 层 / 第 1 层 / 第 2 层” -
ModuleDict: 关注 “backbone / head / classifier / branch_A”当模块的语义角色本身就是模型设计的一部分时,
ModuleDict会明显优于ModuleList。
六、结论:容器的选择,本质是 forward 控制权的选择
在 PyTorch 中,模型结构的定义并不是通过“层的声明顺序”完成的, 而是通过 forward 中的数据流向 最终确定的。
Sequential、ModuleList 和 ModuleDict 的区别,并不在于“能不能装模块”,而在于:谁来决定 forward 的执行逻辑?
nn.Sequential- 将 forward 的控制权交给框架
- 适合结构固定、线性可描述的网络模块
nn.ModuleList- 保留模块的注册与管理
- 将 forward 的控制权完全交还给用户
- 适合层数可变、结构动态的模型
nn.ModuleDict- 进一步强调模块的语义角色
- forward 不再依赖“位置”,而依赖“名称”
- 适合多分支、多功能组件组成的复杂模型
从这个角度看,PyTorch 的设计并不是在提供三种“不同的写法”,而是在刻意引导一种建模思想:模型结构 = 模块注册 + forward 中的显式连接。理解这一点,不仅能帮助我们写出更清晰的模型代码,也能在面对复杂网络结构时,做出更合理的设计选择。
但是真正复杂的模型,从来不是“层堆出来的”,而是 forward 里流动的数据决定的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









