



简介:SeAFusion(2022)是一种语义感知的实时图像融合框架,专为红外与可见光图像融合设计,旨在提升融合结果对高级视觉任务的支持能力。其核心创新在于将图像融合与语义分割任务深度联动,通过引入语义损失函数,将高层语义信息反馈至融合网络,促使其保留源图像中对下游任务(如目标检测、语义分割)至关重要的语义特征。技术层面,SeAFusion 采用轻量级双分支架构,通过梯度残差密集块(GRDB)强化细粒度细节的提取能力。GRDB 通过主密集流实现特征复用,并利用梯度算子提取的残差连接增强边缘和纹理信息的保留。此外,框架设计了联合自适应训练策略,交替优化融合网络与分割网络,在保证融合图像质量的同时,提升其对语义分割等任务的促进作用,避免传统方法中 “模式坍塌” 问题。实验结果表明,SeAFusion 在实时性(支持 4K 分辨率下的实时处理)和任务驱动评估中表现优异,融合图像不仅具备自然的视觉效果,还能显著提升后续高级任务的精度。该框架为多模态数据融合提供了新范式,尤其适用于安防监控、自动驾驶等需兼顾图像质量与语义信息的场景。
本教程配置:Ubuntu-20.04,CUDA-11.6,torch-1.13.1,python-3.8
1.环境配置
1)创建环境
conda create -n sea python=3.8
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install opencv-python-headless
conda install numpy
conda install pillow
2)代码导入
git clone https://github.com/Linfeng-Tang/SeAFusion.git
2.数据集修改
1)构建数据集
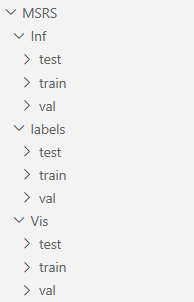
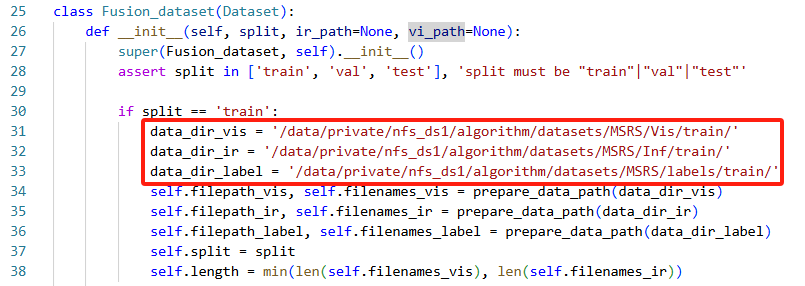
2)修改数据集位置
位置:seafusion-main>TaskFusion_dataset.py
3.训练
1)修改getitem
运行代码时报错:np.asarray(Image.fromarray(image_vis), dtype=np.float32).transpose()
ValueError: axes don't match array,为了解决通道数不一致问题修改getitem函数
位置:seafusion-main>TaskFusion_dataset.py
def __getitem__(self, index):
if self.split == 'train':
vis_path = self.filepath_vis[index]
ir_path = self.filepath_ir[index]
label_path = self.filepath_label[index]
# 读取可见光图像
image_vis = np.array(Image.open(vis_path))
if image_vis.ndim == 2: # 如果是灰度图像
image_vis = np.stack((image_vis,) * 3, axis=-1) # 转为三通道
# 读取红外图像
image_inf = cv2.imread(ir_path, 0)
# 读取标签图像
label = np.array(Image.open(label_path))
# 转换并归一化可见光图像
image_vis = (
np.asarray(image_vis, dtype=np.float32).transpose((2, 0, 1)) / 255.0
)
# 处理红外图像
image_ir = np.asarray(image_inf, dtype=np.float32) / 255.0
image_ir = np.expand_dims(image_ir, axis=0)
# 处理标签
label = np.asarray(label, dtype=np.int64)
name = self.filenames_vis[index]
return (
torch.tensor(image_vis),
torch.tensor(image_ir),
torch.tensor(label),
name,
)
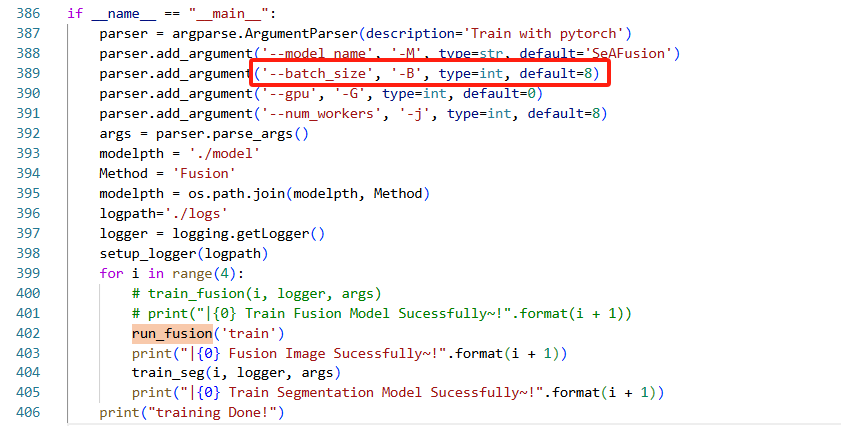
2)修改batch_size
运行代码时报错:torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 600.00 MiB (GPU 0; 23.54 GiB total capacity; 7.20 GiB already allocated; 462.00 MiB free; 7.23 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF,为了解决CUDA内存不足的问题,可降低批次大小
位置:seafusion-main>train.py
3)新建logs文件夹
运行train.py时报错FileNotFoundError: [Errno 2] No such file or directory: '/data/private/nfs_ds1/algorithm/SeAFusion-main/logs/BiSeNet-2025-04-01-07-02-00.log'
新建logs文件夹即可解决
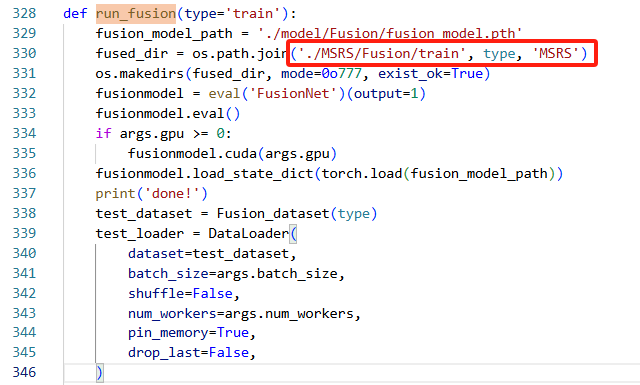
4)修改run_fusion
运行train.py时报错FileNotFoundError: [Errno 2] No such file or directory,只需要添加train到如下位置即可:
5)训练
终端运行:CUDA_VISIBLE_DEVICES=4 train.py


















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









