



 本文探讨了在Java中使用TreeSet存储自定义对象时所需做的改动,特别是当涉及到自定义比较器时。通过示例,解释了如何通过重写Comparator的compare方法来确保对象的独特性,并指出在TreeSet中,add操作依赖于Comparable或Comparator接口来确定元素的唯一性。
本文探讨了在Java中使用TreeSet存储自定义对象时所需做的改动,特别是当涉及到自定义比较器时。通过示例,解释了如何通过重写Comparator的compare方法来确保对象的独特性,并指出在TreeSet中,add操作依赖于Comparable或Comparator接口来确定元素的唯一性。
TreeSet存储自定义对象
TreeSet存储自定义对象需要做哪些改动
我们知道,在HashSet里面存储自定义对象时要重写HashCode()和equals()方法。同样的在TreeSet里面存储自定义对象时也要做一些改动。
以自定义比较器为例
public class User {
private String name;
private int age
}
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
TreeSet<User> users = new TreeSet<>(new Comparator<User>() {
@Override
public int compare(User o1, User o2) {
return o1.getAge()-o2.getAge();
}
});
User user01 = new User("张三", 20);
User user02 = new User("张三", 30);
User user03 = new User("王五", 4);
User user04 = new User("李四", 50);
User user05 = new User("张三", 20);
User user06 = new User("赵六", 20);
users.add(user01);
users.add(user02);
users.add(user03);
users.add(user04);
users.add(user05);
users.add(user06);
users.forEach(System.out::println);
}
提问:TreeSet里面存储有几个对象?
实际运行得知里面有4个对象。
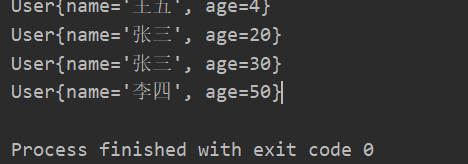
可以看到age为20的对象只有一个。接下来对匿名内部类的代码进行修改
public int compare(User o1, User o2) {
if (o1.getAge()== o2.getAge()){
return o1.getName().compareTo(o2.getName());
}
return o1.getAge()-o2.getAge();
}
重新运行
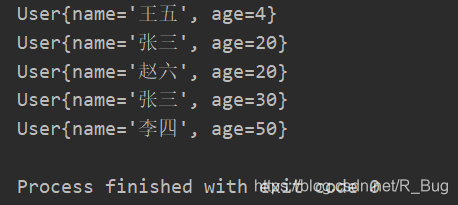
以上问题是我在自学java过程中遇到的。当时我很疑惑,问同学建议我重写HashCode()和equals()。我带着疑惑重写后发现结果并没有不同。思考之后我想到TreeSet的底层是排序二叉树,排序前元素比大小,里面也不牵扯哈希值。难道Comparator匿名内部类的代码直接影响了二叉树的存储?对比前后代码我发现只比较年龄大小的话年龄相同程序认为是同一元素,Set中元素不能重复,所以相同年龄的对象只能在二叉树上面存一个。加上name的比较这样就能合理确认是否是同一个元素。
总的来说
TreeSet集合中add()底层主要依赖实现comparable和comparator接口。
对于非自定义对象(具体可比性的对象),因为hashset和treeset已经实现了比较,不要重新方法,而对于自定义对象(不具有可比性的对象),使用hashset使用需要重写hashcode和equals方法,而使用TreeSet集合需要实现comparator或者comparable重写compare()或者compareTo()方法,实现比较。

















 5728
5728

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









