




 本文介绍如何在润乾报表中使用列名作为分类值绘制统计图,通过list()函数实现列名集合化,case()函数确保系列值与列名正确匹配。
本文介绍如何在润乾报表中使用列名作为分类值绘制统计图,通过list()函数实现列名集合化,case()函数确保系列值与列名正确匹配。
一般来说,在报表中设计的统计图要用到两个变量值,一个是分类值,一般是统计中的横轴,还有一个就是系列值,相应的就是统计图中的纵轴。绝大多数情况下,分类值与系列值都是来源于表中的数据,也就是说,统计图是基于数据库表中的记录来设计器的,例如下面这个统计图:
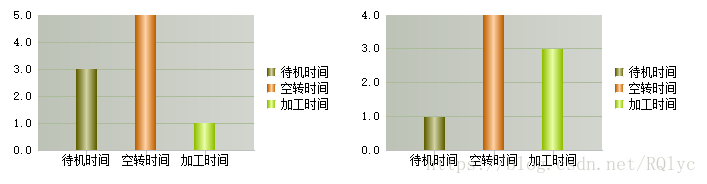
一般会来自于这样的数据:
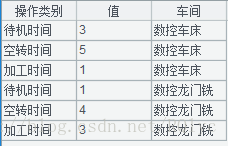
但是,有时会遇到下面这样的数据:
显然,如果还需要做出前面的统计图,那么分类值和系列值就需要使用数据库中的列名也就是字段名了。说实话,小编以前看到这种数据除了摇头,也就是想办法重新设计一张数据表,把所有列名存入一个字段,然后再进行数据转换和导入了。不是小编无能,没办法直接用这些数据画出统计图,实在是因为列名与列名之间都是独立的个体,并没有一个整体的概念,所以也就没有办法表示出对应的占比情况了。但是修改数据库这种操作往往用户是极不愿意接受的,那么,这种统计图就做不了了吗?
现在,经过技能升级的小编可以负责任地告诉你,润乾报表完全可以不修改数据表就搞定问题!
还是用上图的数据和图表来展示一下润乾报表的这个秘技:
首先, 设计报表模板:
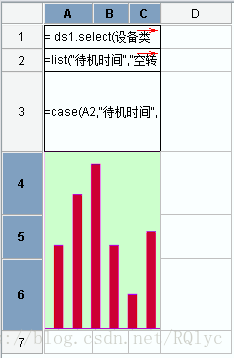
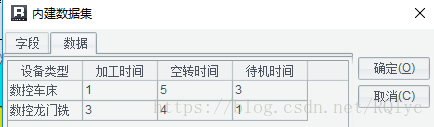
其中:
A1:= ds1.select(设备类型),扩展方向为横向。
A2:=list(“待机时间“,”空转时间“,”加工时间“),扩展方向为横向。
A3:=case(A2,”待机时间“,ds1. 待机时间,”空转时间“,ds1. 空转时间,”加工时间“, ds1. 加工时间)
这里用到了 list()和 case() 函数,是因为系列值实际上是分类轴的一个附属格,而报表画图的时候,只是把分类轴当成集合,系列值是当成一个值来画的,所以这里只取了 list 的第一个值。
看一下统计图中的设置:
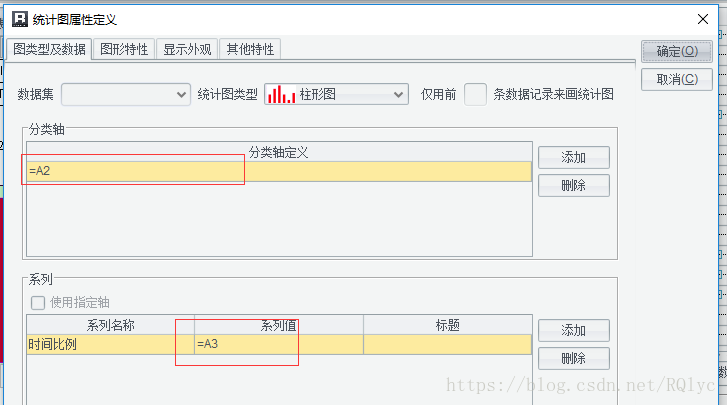
接下来,保存,看下展现的效果,如下图:
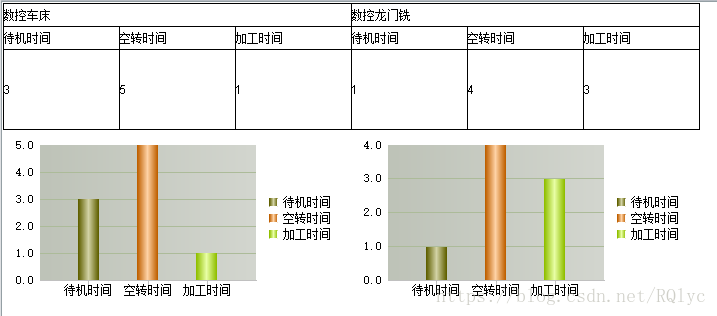
噹噹噹… 一个列名作为分类的统计图报表就完成了。
我们来回顾一下其中遇到的问题和解决的技巧:
1. 列名集合化
【技巧】使用 list() 函数获得一个枚举的数据集合。
2. 系列值正确匹配列名
【技巧】使用 case() 函数使数据与列名匹配。

















 2623
2623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









