




 本文探讨了在大数据处理中遇到的百亿级数据join导致的性能问题,通过调整SQL、表结构和参数优化,成功提升了处理效率。关键措施包括:按天分区join减少数据量,将user_article_tb转换为uid粒度,创建宽表减少join次数,以及通用的ODPS/Hive参数优化。这些方法在实际业务场景中显著提高了大数据处理的效率。
本文探讨了在大数据处理中遇到的百亿级数据join导致的性能问题,通过调整SQL、表结构和参数优化,成功提升了处理效率。关键措施包括:按天分区join减少数据量,将user_article_tb转换为uid粒度,创建宽表减少join次数,以及通用的ODPS/Hive参数优化。这些方法在实际业务场景中显著提高了大数据处理的效率。
最近在做大数据处理时,遇到两个大表 join 导致数据处理太慢(甚至算不出来)的问题。我们的数仓基于阿里的 ODPS,它与 Hive 类似,所以这篇文章也适用于使用 Hive 优化。处理优化问题,一般是先指定一些常用的优化参数,但是当设置参数仍然不奏效的时候,我们就要结合具体的业务,在 SQL 上做优化了。为了不增加大家的阅读负担,我会简化这篇文章的业务描述。
问题
这是一个离线数据处理的问题。在这个业务中有两张表,表结构及说明如下:
user_article_tb 表:
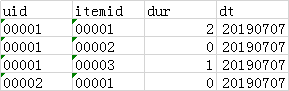
字段解释: uid: 用户标识,itemid:文章id,dur: 阅读文章时长,如果大于 0 代表阅读了文章,等于 0 代表没有点击文章 dt:天分区,每天 55 亿条记录 user_profile_tb 表:

字段解释: uid:用户标识,gender:性别,F 代表女,M 代表男,age:年龄,city:城市 dt:天分区字段,这是一张总表,每天存储全量用户画像属性,最新数据十亿级别
需求是这样的:计算 7 天中,女性用户在每篇文章上的 ctr (最终会按照降序进行截断)。直接写 SQL 很容易,如下:
select
itemid
, count(if(dur > 0, 1, null)) / count(1) ctr
from
(
select uid, itemid, dur
from u 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 701
701

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









