 简单线性模型的训练与可视化
简单线性模型的训练与可视化




import numpy as np
import matplotlib.pyplot as plt
# 数据
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
# 预测函数
def forward(x):
return x * w
# 损失函数
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
# 计算梯度
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
# 打印训练前预测值
print('Predict (before training)', 4, forward(4))
# 保存损失值以便绘图
cost_list = []
# 训练
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
cost_list.append(cost_val) # 记录损失值
print('Epoch:', epoch, 'w=', w, 'loss=', cost_val)
# 打印训练后预测值
print('Predict (after training)', 4, forward(4))
# 绘制损失值随 epoch 的变化
plt.plot(range(100), cost_list)
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.title('Cost in each epoch')
plt.grid()
plt.show()
- 导入必要的库:
import numpy as np
import matplotlib.pyplot as plt
这里导入了 numpy 库并简称为 np,它提供了强大的数值计算功能,常用于处理数组等数据结构。同时导入了 matplotlib.pyplot 库并简称为 plt,用于绘制图表来可视化数据和模型训练过程中的相关指标。
2. 数据准备:
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0
定义了输入数据 x_data 和对应的目标数据 y_data,这里是简单的三组数据点。还初始化了权重 w 的值为 1.0,这个权重将在后续的预测函数和模型训练中起到关键作用。
3. 预测函数:
def forward(x):
return x * w
forward 函数实现了简单的线性预测功能。它接受一个输入值 x,并根据当前的权重 w 计算预测值,即通过将输入 x 与权重 w 相乘得到预测结果 y_pred。
4. 损失函数:
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
cost 函数用于计算模型的损失。它通过遍历输入数据 xs 和目标数据 ys 中的每一对数据点,首先使用 forward 函数得到预测值 y_pred,然后计算预测值与实际目标值 y 的差的平方,并将这些平方差累加起来。最后将累加的结果除以数据点的数量 len(xs),得到平均损失值。损失函数的目的是衡量模型预测结果与实际目标值之间的差异程度,以便在训练过程中优化模型参数(这里就是权重 w)来减小损失。
##5. 计算梯度:
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
gradient 函数用于计算损失函数关于权重 w 的梯度。在每次迭代训练中,梯度指示了损失函数在当前权重值下的变化率,通过沿着梯度的反方向更新权重,可以使损失函数逐渐减小。它同样是遍历输入数据和目标数据的每一对数据点,根据当前的权重 w、输入值 x 和目标值 y,按照特定的公式计算梯度的一部分,并将这些部分累加起来,最后除以数据点的数量得到平均梯度值。
6. 打印训练前预测值:
print('Predict (before training)', 4, forward(4))
在训练开始之前,使用当前初始化的权重 w(值为 1.0)对输入值 4 进行预测,并打印出相关信息,包括提示文本 Predict (before training)、输入值 4 以及对应的预测值(通过调用 forward(4) 得到)。这可以让我们了解在未经过训练时模型的初始预测能力。
7. 保存损失值以便绘图:
cost_list = []
创建一个空列表 cost_list,用于在训练过程中保存每一轮迭代后的损失值。这样在训练完成后,就可以利用这些保存的损失值来绘制损失随训练轮次(epoch)变化的曲线,直观地观察模型训练的进展情况。
8. 训练过程:
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.01 * grad_val
cost_list.append(cost_val)
print('Epoch:', epoch, 'w=', w, 'loss=', cost_val)
这是一个循环进行 100 次的训练过程(epoch 表示训练轮次):
首先,通过调用 cost 函数计算当前轮次下模型在给定数据 x_data 和 y_data 上的损失值 cost_val。
接着,调用 gradient 函数计算损失函数关于权重 w 的梯度值 grad_val。
然后,根据梯度下降算法,以学习率 0.01(通过 0.01 * grad_val 来调整权重更新的步长)更新权重 w,即让权重 w 减去梯度乘以学习率的值,这样可以使权重朝着使损失函数减小的方向移动。
之后,将当前轮次计算得到的损失值 cost_val 保存到 cost_list 中,以便后续绘图使用。
最后,打印出当前轮次的相关信息,包括 epoch、更新后的权重 w 以及损失值 cost_val,这样可以在训练过程中实时查看模型的训练状态和参数变化情况。
9. 打印训练后预测值:
print('Predict (after training)', 4, forward(4))
在训练完成后,再次使用更新后的权重 w 对输入值 4 进行预测,并打印出相关信息,包括提示文本 Predict (after training)、输入值 4 以及对应的预测值(通过调用 forward(4) 得到)。通过与训练前的预测值对比,可以直观地看到模型经过训练后预测能力的变化情况。
10. 绘制损失值随 epoch 的变化:
plt.plot(range(100), cost_list)
plt.xlabel('Epoch')
plt.ylabel('Cost')
plt.title('Cost in each epoch')
plt.grid()
plt.show()
首先,使用 plt.plot 函数绘制损失值 cost_list 随训练轮次 epoch(这里通过 range(100) 表示 0 到 99 的轮次)变化的曲线。
然后,通过 plt.xlabel、plt.ylabel 和 plt.title 分别设置 x 轴标签、y 轴标签和图表标题,以便清晰地标识图表的含义。
接着,使用 plt.grid 函数添加网格线,使图表更加清晰易读。
最后,通过 plt.show 函数显示绘制好的图表,这样就可以直观地观察到在整个训练过程中损失值是如何随着训练轮次的增加而变化的,从而了解模型训练的收敛情况等信息。
运行结果: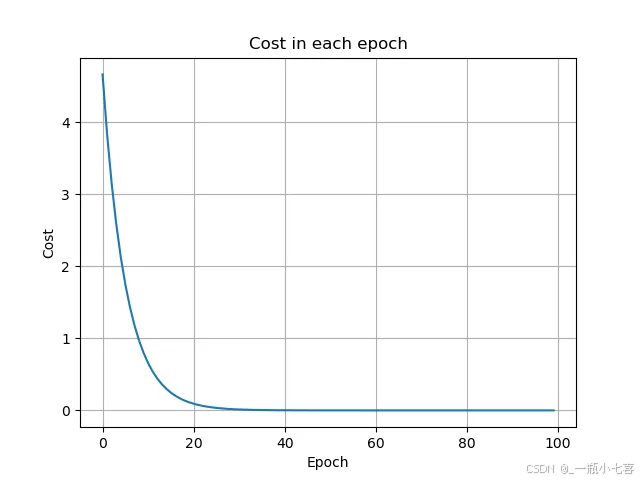

















 741
741

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









