






 本文详述了从v1.0.5到v1.1.0的Go内存缓存性能提升过程,包括读取性能从100ns/op优化到40ns/op,以及减少GC耗时的策略。通过优化读取策略、减少临时对象和改进双链表结构,实现了性能的显著提升。此外,还解决了时间戳问题和并发安全性问题。
本文详述了从v1.0.5到v1.1.0的Go内存缓存性能提升过程,包括读取性能从100ns/op优化到40ns/op,以及减少GC耗时的策略。通过优化读取策略、减少临时对象和改进双链表结构,实现了性能的显著提升。此外,还解决了时间戳问题和并发安全性问题。
本文记录了ecache v1.0.5到v1.1.0的性能优化过程
背景介绍
ecache是一款极简设计、高性能、并发安全、支持分布式一致性的轻量级内存缓存,支持LRU和LRU-2两种模式项目地址:https://github.com/orca-zhang/ecache
准备工作
原则
基于真实的度量。——《重构——改善现有代码的设计》P69
哪怕你完全了解系统,也请实际度量它的性能,不要臆测。臆测会让你学到一些东西,但十有八九你是错的。
思路
我期望能够有一个仓库,每次优化以后,都能横向比较同类库之间的性能,并且通过直观的柱状图之类的图表展示出来,于是有了benchplus/gocache项目,它是一个持续基准测试的项目。
第一版我设计了写入和读取整型、写入1K/1M数据、写入小对象(
bigcache和freecache需要序列化)、写满以后继续写入整型等用例。第二版又增加了并发读写、GC耗时、命中率、内存占用等用例。
工具
golang pprof
graphivs(用来生成剖析结果图片)
mac下安装命令:
brew install graphviz
步骤
运行一次ecache的测试用例
sh>
GO111MOUDLE=off go test -bench=BenchmarkGetInt_ecache ecache_test.go -cpuprofile=cpu.prof剖析结果文件
sh>
go tool pprof benchplus.test cpu.prof
交互模式下:(pprof) svg分析生成的svg图
优化一:读取性能(从100ns/op到40ns/op)
总体还是比较符合预期的,毕竟在性能方面已经有所考量和侧重,但是在最初的测试中,优势依然不是特别明显,比如读取性能,最快的
bigcache读取整型值的性能在 80ns/op 左右,但是ecache在第一版只能跑出 100ns/op 左右的性能。
hashCode占了总耗时的50%

分析剖析结果,发现大部分时间花在了
string转[]byte产生临时对象的产生和销毁上优化思路:换一种hash方法,按照以前的经验,BKRD和AP的分布性比较好,BKRD实现更简单,性能也不错,所以选择BKRD替代CRC32【commit-0e7aaaae】
func hashBKRD(s string) (hash int32) { for i := 0; i < len(s); i++ { hash = hash*131 + int32(s[i]) } return hash }
继续剖析——time.Now()占了总耗时的33%
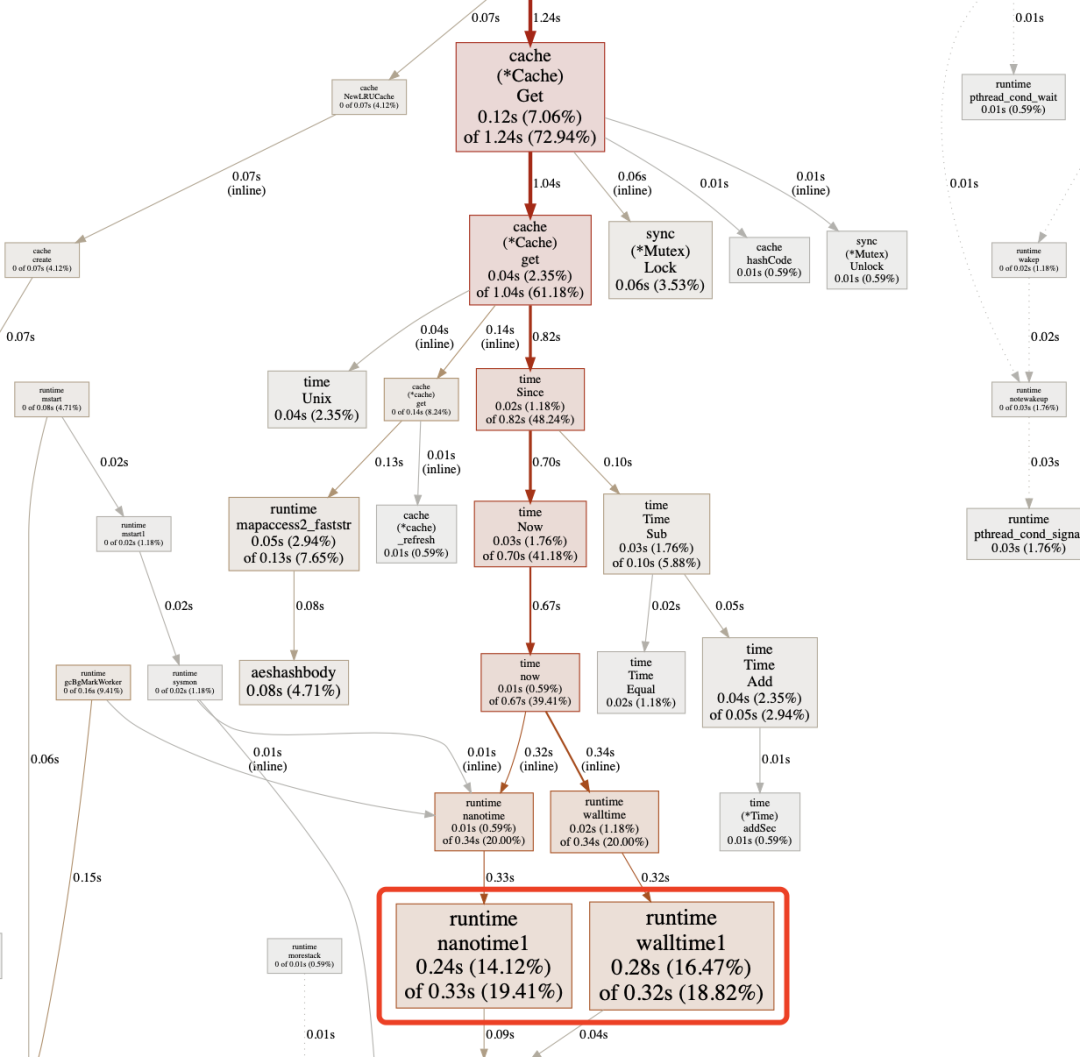
优化思路:由于内部只需要时间戳,并且缓存系统要求的时间戳并不一定那么精准,所以考虑用维护一个全局时间戳的方式来优化————短期自增(每100ms)、定期校准(约1s)
time.Now()【代码版本快照】改为内部计时器【commit-8dc1fa7d】,获取当前时间使用内部的now()方法可直接获得时间戳,而不再需要使用会产生临时对象的time.Now().UnixNano()内部计时器最初采用
time.Timer实现,实际测试发现定时器会受系统压力影响,精度无法保证,后改为time.Sleep【commit-92245e4b】var clock = time.Now().UnixNano() func now() int64 { return atomic.LoadInt64(&clock) } func init() { go func() { for { atomic.StoreInt64(&clock, time.Now().UnixNano()) // 每秒校准 for i := 0; i < 9; i++ { time.Sleep(100 * time.Millisecond) atomic.AddInt64(&clock, int64(100*time.Millisecond)) } time.Sleep(100 * time.Millisecond) } }() }本次优化完成以后,读取整型性能提升至40ns/op,从设计的指标来看,
ecache的数据都已名列前茅
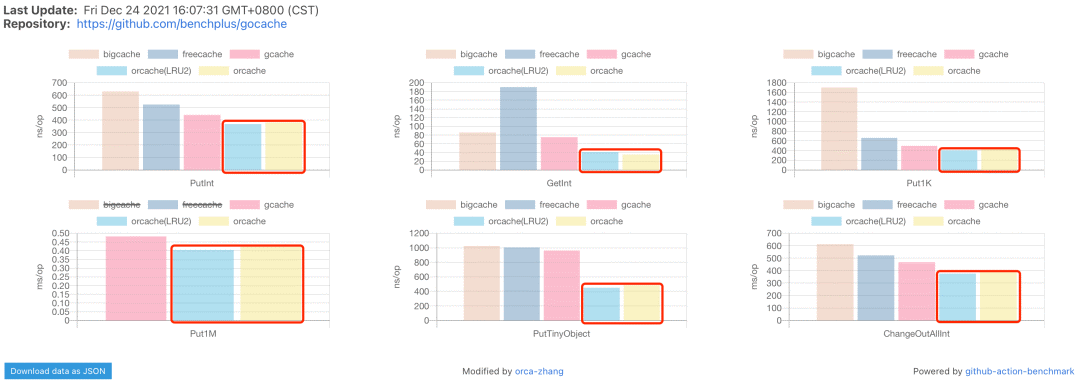
优化二:GC耗时(从3倍耗时到超越)
虽然通过
bigcache提供的bench,得到的数据比bigcache本身要好(后分析可能是因为在平时写入时把GC耗时分担到了总耗时,而bench里没有总耗时统计),但是随后又添加的并发读写测试和GC测试中发现ecache优势不明显,比如写整型值的GC耗时是当时最快的bigcache(80ms左右)的2倍多(200ms左右),写1K数据的GC耗时是当时最快的freecache的3倍多。从剖析结果来看,重点方向在三个方面
减少临时对象产生
减少栈对象逃逸到堆(避免返回指针)
interface性能较差(存储小对象时,相比拷贝没有优势)
针对双链表的改进思路
双链表节点实现成不需要产生临时节点指针的形式
用一次性预分配的连续区域存储节点
用索引列表来表达双链表
type node struct { k string v value expireAt int64 // 纳秒时间戳,为0说明被标记删除 }type cache struct { dlnk [][2]uint16 // 双链表索引列表,第0个元素存储{尾节点索引,头节点索引},其他元素存{前序节点索引,后继节点索引} m []node // 预分配连续空间内存 hmap map[string]uint16 // <key,dlnk中的位置> last uint16 // 没有满时,分配到的位置 }
一些取巧的设计
只用一个
last字段和连续节点空间的容量比较来判断是否分配满if c.last == uint16(cap(c.m)) // 分配满了用uint16类型存储索引,节省空间的同时,配合桶的数量,足够大
dlnk用n+1个元素来存储索引,每个元素都是{前序节点索引, 后继节点索引}索引为0代表空,刚好
dlnk[0]存储的是{尾节点索引,头节点索引}因为头尾节点和其他节点存储在一起,复用
adjust方法,通过参数就能实现将元素移动到头部还是尾部的功能ajust(x, p, n)移动到头部ajust(x, n, p)移动到尾部
删除元素时复用时间戳,设置为0代表删除,并且移动到链表尾部
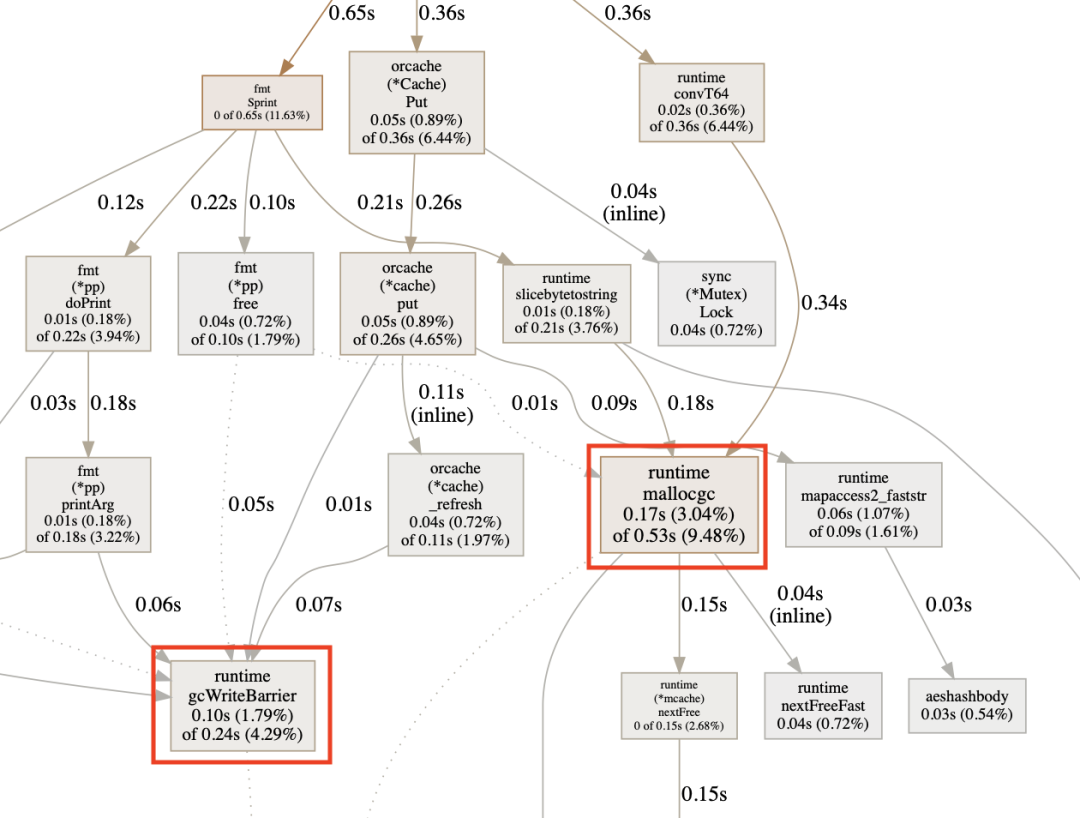
调整完效果还不错,
mallogc缩短了、_refresh时候的gcWriteBarrier也不见了
进一步优化
interface的问题还没有解决,尝试直接用
int64存储value,性能好很多,比bigcache要快,但是这并不是ecache设计的初衷,我们期望能够适应不同场景,并且能存储不同类型的对象先尝试用一个包装器把
interface类型和int64类型分开放置type value struct { v *interface{} // 存放任意类型 i int64 // 存放整型 }但是性能差很多,剖析发现是包装以后的临时对象太多,于是尝试用1000大小的
ringbuffer实现了一个对象池,优化了分配性能,结果能和bigcache相同了,感兴趣的可以了解一下源码不过最终没有使用,因为灵机一动,发现
node的value字段,不用对象指针(单纯栈对象拷贝赋值)和用指针加ringbuffer性能是一样的(好险!差点就变复杂了😅)
还差最后一步
整型的耗时问题优化完了,还有
freecache写入1K的问题不是吗,我一直在想,他为什么能这么快,甚至还看了他的源码,不过偷师没成经历了将近一整天的各种优化(尝试使用reflect2判断类型;cacheline优化)都没效果,差点就放弃了,终于找到了解决方案————用
[]byte类型直接接收!(PS:似曾相识的套路)type value struct { i *interface{} // 存放任意类型 b []byte // 存放字节数组 }测试结果很理想,总耗时和GC耗时都超越了最快的
freecache,PS:不过也是trade-off,只是较大的对象在ecacheGC上消耗的时间没有freecache拷贝消耗的时间多而已最后把整型也用
encoding/binary.LittleEndian.PutUint64合并进了[]byte,内存占用一样,性能稍慢一点点
其他改进
时间戳原来记录的是写入时间,群友review提出了时间回跳可能会有问题,改为
expireAt过期的时间点,保证一定会在设置的过期时间内过期仔细检查并发场景下
node复用可能导致取到错误值的情况
优化结果
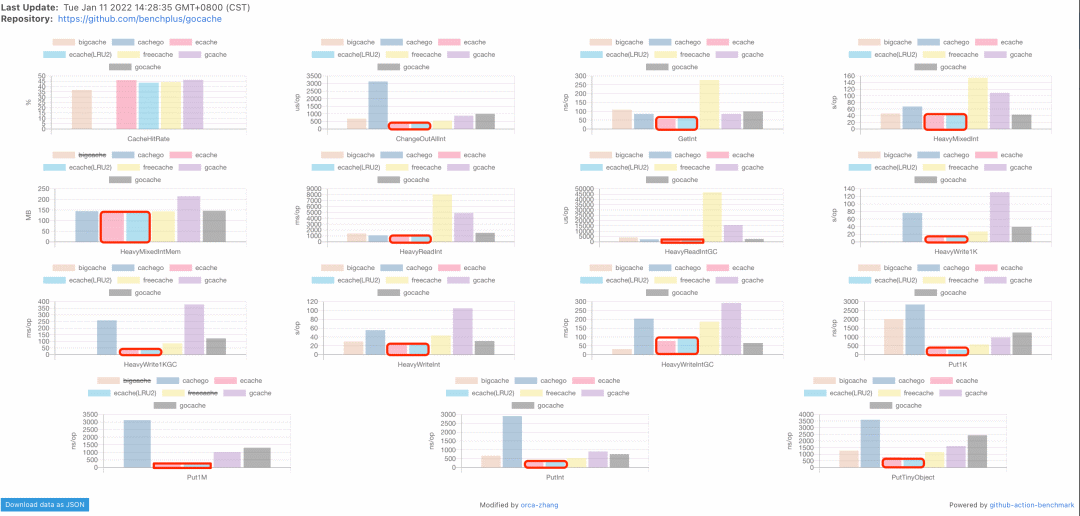
🐌 代表很慢,✈️ 代表快,🚀 代表非常快,可以看到优化以后的ecache,各项测试表现都不错(除大量并发写入整型的GC耗时无法超过bigcache外)。
| bigcache | cachego | ecache | freecache | gcache | gocache | |
| PutInt | ✈️ | 🚀 | 🚀 | ✈️ | ✈️ | |
| GetInt | ✈️ | ✈️ | 🚀 | ✈️ | ✈️ | |
| Put1K | ✈️ | ✈️ | 🚀 | 🚀 | 🚀 | ✈️ |
| Put1M | 🐌 | 🚀 | 🐌 | ✈️ | ✈️ | |
| PutTinyObject | ✈️ | 🚀 | 🚀 | ✈️ | ||
| ChangeOutAllInt | ✈️ | 🚀 | 🚀 | ✈️ | ✈️ | |
| HeavyReadInt | 🚀 | 🚀 | 🚀 | 🚀 | ||
| HeavyReadIntGC | ✈️ | 🚀 | 🚀 | ✈️ | ✈️ | |
| HeavyWriteInt | 🚀 | ✈️ | 🚀 | 🚀 | ✈️ | |
| HeavyWriteIntGC | 🚀 | ✈️ | ✈️ | |||
| HeavyWrite1K | 🐌 | ✈️ | 🚀 | 🚀 | ✈️ | |
| HeavyWrite1KGC | 🐌 | ✈️ | 🚀 | 🚀 | ✈️ | |
| HeavyMixedInt | 🚀 | ✈️ | 🚀 | ✈️ | 🚀 |
版本对比
基线版本v1.0.5 vs 优化版本v1.1.0:(https://github.com/orca-zhang/ecache/tree/68f69ca9cf3043bf3a9853d320389252e81310b9) vs (https://github.com/orca-zhang/ecache/tree/1cb426fe021959eacb86a675bebff69a2b430b6d
参考资料
TinyLFU: A Highly Efficient Cache Admission Policy:https://arxiv.org/abs/1512.00727
设计实现高性能本地内存缓存:https://blog.joway.io/posts/modern-memory-cache/
LRU算法及其优化策略——算法篇:https://juejin.cn/post/6844904049263771662


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









