




PALF: Replicated Write-Ahead Logging for Distributed Databases
PALF:分布式数据库的复制预写日志技术
注: 非校准状态,后续会详细研究该文章后再推出校准后的内容。如果不能等的朋友们可以先看看。
ABSTRACT(摘要)
Distributed databases have been widely researched and developed in recent years due to their scalability, availability, and consistency guarantees. The write-ahead logging (WAL) system is one of the most vital components in a database. It is still a non-trivial problem to design a replicated logging system as the foundation of a distributed database with the power of ACID transactions. This paper proposes PALF, a Paxos-backed Append-only Log File System, to address these challenges. The basic idea behind PALF is to co-design the logging system with the entire database for supporting database-specific functions and to abstract the functions as PALF primitives to power other distributed systems. Many database functions, including transaction processing, database restore, and physical standby databases, have been built based on PALF primitives. Evaluation shows that PALF greatly outperforms well-known implementations of consensus protocols and is fully competent for distributed database workloads. PALF has been deployed as a component of the OceanBase 4.0 database and has been made open-source along with it.
近年来,分布式数据库因其可扩展性、可用性和一致性保障而受到了广泛的研究和开发。预写日志(WAL)系统是数据库中最重要的组成部分之一。要设计一个具备 ACID 事务能力的分布式数据库的复制日志系统,这仍然是一个相当棘手的问题。本文提出了 PALF,这是一种基于 Paxos 的只追加日志文件系统,以解决这些挑战。PALF 的基本理念是将日志系统与整个数据库协同设计,以支持数据库特定的功能,并将这些功能抽象为 PALF 基本单元,为其他分布式系统提供支持。许多数据库功能,包括事务处理、数据库恢复和物理备用数据库,都是基于 PALF 基本单元构建的。评估表明,PALF 明显优于公认的共识协议实现,并且完全能够胜任分布式数据库工作负载。PALF 已作为 OceanBase 4.0 数据库的一个组件进行部署,并与之一同开源。
1 INTRODUCTION(简介)
The write-ahead logging (WAL) system was originally introduced to recover databases to their previous state after a failure. Beyond this initial purpose, more requirements have been gradually emerging from distributed databases. The logging system should be capable of replicating logs to multiple replicas for durability and failure tolerance. Several important database features rely on the design of the logging system, such as transaction processing [9, 50], redo log archiving [35], database backup/restore [37], and physical standby databases [36].
预写式日志系统最初是为了在发生故障后将数据库恢复到其先前的状态而被引入的。除此之外,随着分布式数据库的发展,越来越多的需求逐渐涌现出来。日志系统应当能够将日志复制到多个副本中,以确保数据的持久性和容错性。许多重要的数据库功能都依赖于日志系统的设计,例如事务处理[9, 50]、重做日志归档[35]、数据库备份/恢复[37]以及物理备用数据库[36]。
To keep consistent states of multiple database replicas, consensus protocols have been widely used to replicate logs in distributed databases [9, 42, 48]. Most of these databases were abstracted into replicated state machines (RSM) for integrating with consensus protocols. In the typical RSM model, the client first handles all intended operations and generates logs, these logs are then replicated to all replicas by consensus protocols. After operation logs have been persisted by majority of replicas, each replica applies them to its state machine.
为了保持多个数据库副本的统一状态,共识协议已被广泛用于在分布式数据库中复制日志[9, 42, 48]。这些数据库大多被抽象为复制状态机(RSM),以便与共识协议集成。在典型的 RSM 模型中,客户端首先处理所有预期的操作并生成日志,然后这些日志通过共识协议复制到所有副本中。在大多数副本保存了操作日志之后,每个副本都会将其应用到自身的状态机中。
The RSM model has been working well for operations that modify small datasets (e.g., setting a key-value to the Key-Value store). However, it may be unsuitable for operations that involves a large amount of data, an example is transactions in distributed databases. First, databases are usually required to equip additional buffer to cache temporary data from clients for log generation, therefore, it is difficult for databases to handle large transactions with data volume greater than its cache. A compromised approach is to limit the size of transactions and break up large transactions into small operating units[8], but at the cost of losing the atomicity of users’ original transactions. Second, reads in a transaction possibly cannot see previous writes in the transaction, because the writes may have not been applied to the database[9]. Reading from the cache is a possible approach; but this will introduce overhead of merging data from the storage engine and the cache, resulting in a decrease in read performance.
RSM 模型在处理修改小型数据集的操作(例如,将键值设置到键值存储中)时表现良好。然而,它可能不适用于涉及大量数据的操作,例如分布式数据库中的事务。首先,数据库通常需要配备额外的缓冲区来缓存来自客户端的临时数据以生成日志,因此,数据库难以处理数据量超过其缓存的大型事务。一种折中的方法是限制事务的大小,并将大型事务分解为较小的操作单元[8],但这样做会失去用户原始事务的原子性。其次,事务中的读取可能无法看到事务中的先前写入操作,因为这些写入可能尚未应用于数据库[9]。从缓存中读取是一个可能的方法;但这会引入从存储引擎和缓存合并数据的开销,从而导致读取性能下降。
To address above problems, our design choice is to integrate consensus protocols into the write-ahead logging model. In the WAL model, a database writes logs using local file system interfaces, the order of logging and applying operations can be reversed compared to RSM model. Writes are applied to the storage engine of database (in-memory state machine) directly, and then redo logs (operations) are generated and flushed. Therefore, the upper limit of transaction size is expanded and read requests just need to access the storage engine. However, designing such a replicated logging system which provides guarantees like local file system to support the WAL model still faces the following challenges:
为解决上述问题,我们的设计选择是将共识协议集成到预写式日志模型中。在预写式日志模型中,数据库使用本地文件系统接口来写入日志,与读写式存储模型相比,日志的记录顺序和应用操作的顺序可以颠倒。写入操作直接应用于数据库的存储引擎(内存状态机)中,然后生成重做日志(操作)并进行刷新。因此,事务的大小上限得到了扩展,读取请求只需访问存储引擎即可。然而,设计这样一个具有与本地文件系统类似保证的复制式日志系统以支持预写式日志模型仍然面临着以下挑战:
Leader Election. In practical deployments, the database leader is usually co-located with the logging system leader to reduce latency[9, 46, 48]. The requirements of the database should be considered when electing the leader of the logging system, for example, a replica located in the same region/IDC as the application system should be elected as the leader preferentially. However, whether a replica could be elected as the leader traditionally depends on the consensus protocol itself. A leadership transfer extension has been proposed in Raft [33], but it relies on an external coordinator to actively transfer leadership to the designated replica, which harms the availability of the distributed databases.
领导者选举。在实际部署中,数据库领导者通常会与日志系统领导者位于同一位置,以减少延迟[9, 46, 48]。在选举日志系统的领导者时,应考虑数据库的要求,例如,位于与应用系统位于同一区域/IDC 的副本应优先被选为领导者。然而,传统上,一个副本能否被选为领导者取决于共识协议本身。Raft 中提出了一种领导权转移扩展[33],但它依赖于外部协调员主动将领导权转移到指定的副本,这会损害分布式数据库的可用性。
Uncertain Replication Results. In WAL model, whether a transaction should be committed or aborted depends on whether its commit record has been persisted. Data may become inconsistent if the logging system returns an incorrect result to the transaction model due to exceptions (e.g., leadership transfer). Local file system indeed returns explicit write results. However, most consensus protocol implementations do not return explicit replication results when exceptions occur [2, 15]. For example, a previous leader had been transformed to a follower due to temporary network error. If the previous leader had not received acknowledgements for some in-flight logs before its retirement, it is not able to perceive whether the logs have been committed by majority. Therefore, transaction processing may get stuck because the transaction engine can not determine whether its commit record has been persisted.
不确定的复制结果。在 WAL 模型中,是否应提交或撤销一个事务取决于其提交记录是否已持久化。如果由于异常(例如领导权转移)导致日志系统向事务模型返回错误结果,数据可能会变得不一致。本地文件系统确实会返回明确的写入结果。然而,大多数共识协议实现在出现异常时不会返回明确的复制结果[2, 15]。例如,由于临时网络错误,之前的领导者已转变为从属节点。如果之前的领导者在退休前没有收到某些正在进行的日志的确认,它就无法感知这些日志是否已被多数人提交。因此,事务处理可能会陷入停滞,因为事务引擎无法确定其提交记录是否已持久化。
Data Change Synchronization. The log is the database, physical log synchronization is one of the most common approaches to export data changes from the database to downstream systems. For example, physical standby databases (e.g., Oracle Data Guard[36]) provide identical copies of the primary database by transporting and applying redo logs to standby databases. Unlike copying log files directly, log replication in distributed databases poses challenges in synchronizing logs from one replication group in the primary database to a downstream group in a standby database, moreover, these groups should be independently available. Some replication protocols [2, 15] embed cluster-specific information (e.g., membership) into logs, which breaks the continuity of data changes and makes the downstream replication groups unable to reconfigure the cluster independently.
数据变更同步。日志即为数据库,物理日志同步是将数据库中的数据变更导出至下游系统的最常见方法之一。例如,物理备用数据库(如 Oracle 数据守护[36])通过传输并应用重做日志来为主数据库提供完全相同的副本。与直接复制日志文件不同,分布式数据库中的日志复制在将主数据库中一个复制组的日志同步至备用数据库中的下游组方面存在挑战,而且这些组必须是独立可用的。一些复制协议[2, 15]将特定于集群的信息(例如成员身份)嵌入日志中,这破坏了数据变更的连续性,并使下游复制组无法独立重新配置集群。
Performance. For many log replication systems, throughput of a single replication group is limited. As a result, they resort to multiple groups to improve overall throughput by parallel writing [13, 15, 31]. However, numerous replication groups may incur additional overheads. A data partition in a database is usually bound with a replication group [9, 42, 46]; more replication groups imply smaller data partitions. This will result in more distributed transactions and degrade performance of the entire database [41].
性能。对于许多日志复制系统而言,单个复制组的吞吐量是有限的。因此,它们会采用多个组的方式来提高整体吞吐量,通过并行写入来实现[13, 15, 31]。然而,大量的复制组可能会带来额外的开销。数据库中的数据分区通常与一个复制组绑定[9, 42, 46];更多的复制组意味着更小的数据分区。这将导致更多的分布式事务,并降低整个数据库的性能[41]。
This paper presents PALF, a Paxos-backed Append-only Log File System. PALF has been co-designed with the OceanBase database to support its WAL model. It provides typical append-only logging interfaces, as a result, the database can interact with PALF much as it interacts with local files. PALF further abstracted database specific features into primitives, such a clear boundary between the log and the database brings benefits in maintainability for a practical database system, and makes PALF become a building block to construct higher-level distributed systems. These design choices led us to address above challenges by balancing the particularity of databases and the generality of logging systems.
本文介绍了 PALF,这是一种基于 Paxos 的只追加日志文件系统。PALF 是与 OceanBase 数据库共同设计的,以支持其日志写入(WAL)模型。它提供了典型的只追加日志接口,因此数据库可以像与本地文件交互一样与 PALF 进行交互。PALF 还将数据库特有的功能抽象为基本元素,这种清晰的日志与数据库之间的界限为实际的数据库系统带来了可维护性的优势,并使 PALF 成为构建更高级分布式系统的构建模块。这些设计选择使我们能够通过平衡数据库的特殊性和日志系统的通用性来解决上述挑战。
First, PALF decouples leader election from the consensus protocol to support database-related election priorities. For instance, a database replica that closer to upper applications could be elected as the leader by configuring its election priorities. As a result of independent election, a log reconfirmation stage is introduced to PALF for correctness.
首先,PALF 将领导者选举与共识协议相分离,以支持与数据库相关的选举优先级。例如,距离上层应用较近的数据库副本可以通过配置其选举优先级来被选为领导者。由于采用了独立选举,PALF 中引入了日志重新确认阶段以确保正确性。
Second, PALF returns explicit replication results to the log writer(database) unless its leader crashes, which makes PALF act like a local file. The log writer (database) will be notified of whether logs have been committed by PALF, even if the previous leader has lost its leadership. To achieve this, a novel role transition stage pending follower has therefore been introduced into the consensus protocol to determine the status of pending logs; the role of the previous leader will not be switched to follower until it receives logs from the new leader. After that, the state of transactions can be advanced. For example, the previous leader will roll back a transaction if its commit record has not been persisted by the new leader.
其次,PALF 会将明确的复制结果返回给日志写入器(数据库),除非其领导者出现故障,此时 PALF 就会像一个本地文件一样工作。日志写入器(数据库)会收到 PALF 是否已提交日志的通知,即便之前的领导者已经失去领导权也是如此。为了实现这一点,共识协议中引入了一个新的角色转换阶段“待跟从者”,用于确定待提交日志的状态;在接收到来自新领导者的日志之前,之前的领导者的角色不会切换为跟从者。此后,事务的状态可以向前推进。例如,如果新领导者的提交记录尚未保存该先前领导者的提交记录,则先前的领导者会回滚该事务。
Moreover, to synchronize data changes between distributed databases, a downstream Paxos group has been abstracted as a mirror of the primary Paxos group. It only accepts logs from the primary group and can be reconfigured independently. This feature has been used to synchronize redo logs from the primary database to standby databases in OceanBase. To the best of the authors’ knowledge, this is the first Paxos implementation that supports synchronizing proposals from one Paxos group to another group.
此外,为了在分布式数据库之间同步数据变化,一个下游的 Paxos 组被抽象为主 Paxos 组的镜像。它仅接受来自主组的日志,并且可以独立进行配置。这一特性已被用于将主数据库的重做日志同步到备用数据库中,在 OceanBase 中如此应用。据作者所知,这是首个支持将一个 Paxos 组的提议同步到另一个组的 Paxos 实现。
Finally, to reduce the overhead incurred by distributed transactions, we limit the number of log replication groups to the number of servers in a cluster. Fewer replication groups require higher throughput for a single group because it handles logs from multiple partitions. We maximize write performance with systematic optimizations such as pipeline replication, adaptive group replication, and lock-free write path.
最后,为了降低分布式事务所导致的开销,我们将日志复制组的数量限制为集群中的服务器数量。由于较少的复制组需要更高的吞吐量来处理单个组中的来自多个分区的日志,因此我们通过系统性的优化(如管道复制、自适应组复制和无锁写路径)来最大限度地提高写入性能。
To summarize, the contributions of this paper are:
总而言之,本文的贡献在于:
- • PALF is proposed as the replicated write-ahead logging system of OceanBase. Its high availability, excellent performance, and file-like interfaces are suitable for distributed databases (§3).
- • We abstract database-specific demands as PALF primitives, such as explicit replication results and change sequence number, which benefits OceanBase database greatly (§4).
- • A novel method has been proposed to synchronize logs from a Paxos group to others, which powers functions such as physical standby databases (§5).
- • We describe designs for building a high-performance consensus protocol in §6, discuss PALF’s design considerations in §7. Evaluations under both closed-loop clients and database workloads show excellent performance (§8).
- • PALF 被提出作为 OceanBase 的复制式预写日志系统。其高可用性、卓越性能以及类似文件的接口特性使其适用于分布式数据库(第 3 节)。
- • 我们将数据库特定的需求抽象为 PALF 基本元素,例如明确的复制结果和变更序列号,这极大地有利于 OceanBase 数据库(第 4 节)。
- • 提出了一种新颖的方法来将来自 Paxos 组的日志同步到其他组,这为诸如物理备用数据库等功能提供了支持(第 5 节)。
- • 在第 6 节中描述了构建高性能共识协议的设计方案,在第 7 节中讨论了 PALF 的设计考虑因素。在闭环客户端和数据库工作负载下的评估显示出了出色的性能(第 8 节)。
2 BACKGROUND(背景)
This section briefly describes the architecture of the OceanBase database to provide context for how PALF is designed.
本节简要介绍了 OceanBase 数据库的架构,以便为 PALF 的设计提供背景信息。
2.1 OceanBase Database(OB数据库)
OceanBase [46] is a distributed relational database system built on a shared-nothing architecture. The main design goals of OceanBase include compatibility with classical RDBMS, scalability, and fault tolerance. OceanBase supports ACID transactions, redo log archiving, backup and restore, physical standby databases, and many other functions. For efficient data writing, a storage engine based on log-structured merge tree (LSM-tree)[38] has been built from the ground up and co-designed with the transaction engine. The transaction engine ensures ACID properties by using a combination of pessimistic record-level locks[45] and multi-version concurrency control; it is also highly optimized for the shared-nothing architecture. For example, the commit latency of distributed transactions has been reduced to almost only one round of interaction by an improved two-phase commit procedure [46]. OceanBase relies on a Paxos-based write-ahead logging system to tolerate failures. This brings the benefits of distributed systems, but incurs log replication overhead at the same time.
OceanBase [46] 是一款基于无共享架构构建的分布式关系型数据库系统。OceanBase 的主要设计目标包括与传统关系型数据库管理系统(RDBMS)的兼容性、可扩展性和容错性。OceanBase 支持 ACID 事务、重做日志归档、备份与恢复、物理备用数据库以及许多其他功能。为了实现高效的数据写入,我们从零开始构建了一个基于日志结构合并树(LSM-tree)[38] 的存储引擎,并与事务引擎共同设计。事务引擎通过结合悲观记录级锁[45] 和多版本并发控制来确保 ACID 属性;同时,它还针对无共享架构进行了高度优化。例如,通过改进的两阶段提交程序[46],分布式事务的提交延迟已降低到几乎只有一次交互的时间。OceanBase 基于基于 Paxos 的预写式日志系统来容忍故障。这带来了分布式系统的优点,但同时也伴随着日志复制的开销。
2.2 Redesigned Architecture(重新设计架构)
In the previous version of OceanBase [46] (1.0-3.0), the basic unit of transaction processing, logging, and data storage was the table partition. As an increasing number of applications have adopted OceanBase, we found that the previous architecture is not as wellsuited to medium and small enterprises as to large-scale clusters of large companies. One of the problems is the overhead of log replication. OceanBase enables users to create tens of thousands of partitions in each server. This number of Paxos groups consume significant resources for no real purpose, therefore raising the bar for deployments and operations. Another challenge is the huge transaction problem. One such transaction probably spans tens of thousands of partitions, which means that there are tens of thousands of participants in the two-phase commit protocol, which will destabilize the system and sacrifice performance.
在 OceanBase 的前一版本(46)(1.0 - 3.0)中,事务处理、日志记录和数据存储的基本单元是表分区。随着越来越多的应用采用了 OceanBase,我们发现之前的架构对于中型和小型企业来说并不像对于大型公司的大规模集群那样适用。其中一个问题是日志复制的开销。OceanBase 允许用户在每个服务器上创建数万个分区。这些数量的 Paxos 组为了没有实际意义的目的而消耗了大量的资源,因此增加了部署和操作的门槛。另一个挑战是巨大的事务问题。这样的一个事务可能跨越数万个分区,这意味着在两阶段提交协议中有数万个参与者,这将使系统不稳定并牺牲性能。
To address these challenges, the internal architecture of version 4.0 of the OceanBase database was redesigned [47]. A new component, Stream, has been proposed, which consists of several data partitions, a replicated write-ahead logging system, and a transaction engine. The key insight of the Stream is that tables in a database are still partitioned, but the basic unit of transaction and logging is a set of partitions in a Stream, rather than a single partition. A table partition simply represents a piece of data stored in the storage engine. The transaction engine generates redo logs for recording modifications of multiple partitions within a Stream and stores logs in the WAL of the Stream. Multiple replicas of a Stream are created on different servers. Only one of them will be elected as the leader and serve data writing requests. The number of replication groups in a cluster can be reduced to the number of servers to eliminate the overhead incurred by massive replication groups.
为应对这些挑战,OceanBase 数据库 4.0 版本的内部架构进行了重新设计[47]。提出了一个新的组件Stream(流),它由多个数据分区、一个复制式预写日志系统以及一个事务引擎组成。流的关键理念在于,数据库中的表仍然被分区,但事务和日志的基本单元是流中的一个集合分区,而非单个分区。表分区仅仅代表存储在存储引擎中的数据的一部分。事务引擎为记录流中多个分区的修改生成重做日志,并将日志存储在流的 WAL 中。在一个服务器上创建多个流的副本。只会选择其中一个作为领导者并处理数据写入请求。集群中的复制组数量可以减少到服务器数量,以消除大量复制组所带来的开销。
With the abstraction of Stream, version 4.0 of the OceanBase database achieves comparable performance to centralized databases in stand-alone mode (for medium and small enterprises) and can be easily scaled out to distributed clusters by adding machines (for large enterprises). In default settings, each server has one Stream whose leader is elected just at the server, therefore, leaders of different Stream in multiple servers can process queries simultaneously as an active-active architecture. Besides strong consistency service provided by the leader, other replicas of OceanBase database can serve read requests with eventual consistency guarantee (§4.2).
通过引入“流”这一概念,OceanBase 数据库 4.0 版本在独立模式下(适用于中型和小型企业)的性能与集中式数据库相当,并且可以通过添加更多机器轻松扩展为分布式集群(适用于大型企业)。在默认设置下,每台服务器都有一个流,其领导者仅在该服务器上选举产生,因此,多个服务器中不同流的领导者可以同时处理查询,形成一种高可用的架构。除了由领导者提供的强一致性服务外,OceanBase 数据库的其他副本还可以以最终一致性保证的方式处理读请求(§4.2)。
3 DESIGN OF PALF(PALF的设计)
The design purpose of PALF is to provide a replicated write-ahead logging system, which should be capable of serving the OceanBase database and be general enough for building other distributed systems. This purpose of PALF drove its design: a hierarchical architecture for balancing particularity of database and generality of the logging system. Database-specific requirements have been abstracted as PALF primitives and integrated in different layers.
PALF 的设计目的是提供一个复制式的预写日志系统,该系统应当能够服务于 OceanBase 数据库,并且具有足够的通用性以用于构建其他分布式系统。PALF 的这一设计目的促成了其架构的形成:采用分层架构来平衡数据库的特性和日志系统的通用性。针对数据库的具体需求已被抽象为 PALF 基本元素,并整合到不同的层中。
This section first describes PALF as the replicated WAL system of the OceanBase database, and then introduces the interfaces provided by PALF. Finally, the implementation of the consensus protocol is described in detail.
本节首先介绍了 PALF 作为 OceanBase 数据库的复制型 WAL 系统,然后介绍了 PALF 提供的接口。最后,详细描述了共识协议的实现过程。
3.1 Replicated WAL Model(复制型事务日志模型)
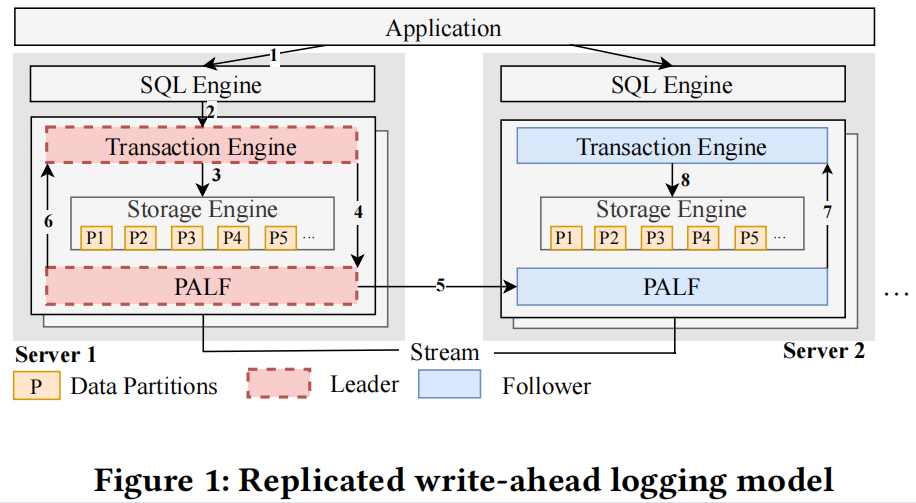
In OceanBase database, the replicated logging system is abstracted as an append-only log file, transaction engine interacts with PALF much as it interacts with local files. As depicted in Fig. 1, transactions modify data in the in-memory storage engine directly (step 2-3). Therefore, the upper limit of a transaction’s size is greatly expanded and is bounded only by the capacity of the storage engine. Log records are then generated and appended to PALF (step 4). The transaction engine of the leader treats PALF as a local log file system, and it is only concerned with whether log records have been flushed. The responsibility of PALF is to replicate modifications performed in the leader to followers (step 5). If a log has been committed by PALF, the leader will inform the transaction engine of the results (step 6), and followers will replay modifications that the leader has performed to itself (step 7-8).
在 OceanBase 数据库中,复制日志系统被抽象为一个只支持追加操作的日志文件,事务引擎与 PALF 的交互方式与与本地文件的交互方式非常相似。如图 1 所示,事务直接在内存存储引擎中修改数据(步骤 2 - 3)。因此,事务的大小上限得到了极大的扩展,并且仅受存储引擎容量的限制。然后生成日志记录并将其追加到 PALF 中(步骤 4)。领导者的事务引擎将 PALF 视为本地日志文件系统,并且只关心日志记录是否已刷新。PALF 的职责是将领导者执行的修改复制到从属节点(步骤 5)。如果 PALF 已将日志提交,则领导者会将结果通知事务引擎(步骤 6),从属节点将重放领导者执行的修改(步骤 7 - 8)。
3.2 PALF Architecture(PALF架构)
As depicted in Fig. 2, PALF is a replicated logging system consisting of multiple replication groups called PALF groups. In each PALF group, multiple PALF replicas are placed on different servers for fault tolerance. The transaction engine can append logs to a PALF group and read logs from it, just like a normal append-only file. PALF consists of three main layers: the interface layer, the PALF replicas layer, and the PALF runtime environment. The lower two layers take charge of log replication, reconfiguration, and log storage; the upper one provides user interfaces and coordinates the states of PALF and the transaction engine.
如图 2 所示,PALF 是一个基于复制的日志系统,它由多个称为 PALF 组的复制组构成。在每个 PALF 组中,多个 PALF 副本被放置在不同的服务器上,以实现容错。事务引擎可以向 PALF 组追加日志并从中读取日志,就像一个普通的只追加文件一样。PALF 由三个主要层组成:接口层、PALF 副本层和 PALF 运行环境。下两层负责日志复制、重新配置和日志存储;上一层提供用户界面并协调 PALF 和事务引擎的状态。
For each PALF group, records generated by the transaction engine are first appended to the leader. The log sequencer will assign a monotonically increasing log sequence number (LSN) to each record, which uniquely identifies a log entry within the PALF group. Records will be encapsulated as log entries and replicated to and persisted by other PALF replicas (followers) in the order of LSN through the Paxos protocol. A log entry is committed only when a majority of PALF replicas have persisted it. Unlike some Paxos variants that bind the leader election and log replication together[6, 24, 32, 34], the leader candidate in PALF is elected by an independent election module. The reconfiguration module manages membership of the PALF group (§5.3).
对于每个 PALF 组,由事务引擎生成的记录首先会被添加到领导者中。日志序列器会为每个记录分配一个单调递增的日志序列号(LSN),该序列号可唯一标识 PALF 组内的一个日志条目。记录将被封装为日志条目,并按照 LSN 的顺序通过 Paxos 协议复制到其他 PALF 副本(跟随者)中并进行持久化。只有当大多数 PALF 副本都已持久化该日志条目时,该日志条目才会被提交。与某些将领导者选举和日志复制绑定在一起的 Paxos 变体不同[6, 24, 32, 34],PALF 的领导者候选者是由一个独立的选举模块选举产生的。重新配置模块管理 PALF 组的成员关系(§5.3)。
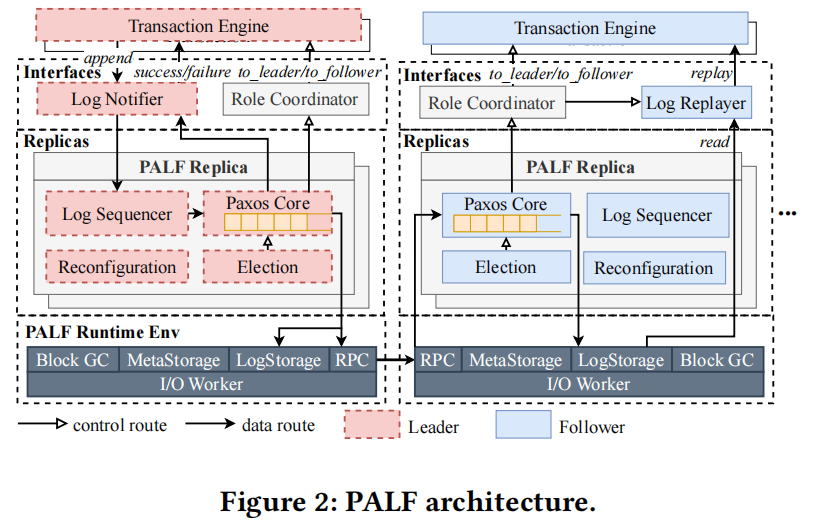
On each server, a PALF runtime environment called PALFEnv is activated to provide remote procedure call (RPC) interfaces and manage disk resources for PALF replicas. Specifically, all log entries in a PALF replica are stored as several constant-size blocks in a unique directory in LogStorage. MetaStorage stores metainformation such as membership of all PALF replicas. BlockGC is responsible for trimming log blocks when they are no longer required. All I/O requests issued by PALF replicas are processed by a uniform I/O worker pool in PALFEnv.
在每个服务器上,都会激活一个名为 PALFEnv 的 PALF 运行环境,以提供远程过程调用(RPC)接口并管理 PALF 副本的磁盘资源。具体而言,PALF 副本中的所有日志条目都以若干固定大小的块的形式存储在 LogStorage 中的一个独特目录中。MetaStorage 则存储诸如所有 PALF 副本的成员关系等元信息。BlockGC 负责在不再需要时修剪日志块。PALF 副本发出的所有 I/O 请求均由 PALFEnv 中统一的 I/O 工作池处理。
We generalize the interaction between PALF and the transaction engine into the interface layer. This isolates the impact of database features on PALF and improves PALF’s generality. The log notifier in the leader informs the transaction engine of whether logs are committed. The log replayer in followers replays mutations recorded in log entries to the transaction engine. If the role of a PALF replica has been switched (i.e., leader to follower or follower to leader), it will throw a role-changing signal to the role coordinator, the role coordinator forwards signals to transform the role of the transaction engine.
我们将 PALF 与事务引擎之间的交互扩展到了接口层。这一做法将数据库特性对 PALF 的影响隔离开来,并提高了 PALF 的通用性。在领导者中,日志通知器会告知事务引擎日志是否已提交。在从属节点中,日志回放器会将日志条目中记录的变更内容回放给事务引擎。如果 PALF 副本的角色发生了切换(即从领导者变为从属节点,或者从从属节点变为领导者),它会向角色协调器发送角色变更信号,而角色协调器会将这些信号转发给事务引擎,以改变其角色。
3.3 System Interfaces(系统接口)
Figure 3 shows a set of data-related APIs, omitting the interfaces for system management such as bootstrapping and reconfiguration. PALF offers two methods for writing logs: append and mirror. The append method submits a record �� to the leader of a PALF group, it returns an LSN to identify the log entry. LSNs of log entries are monotonically increasing, it represents the physical offset of the log entry on the log block. The change sequence number (CSN) is another log entry identifier and will be discussed in §4.2. To achieve high throughput, the append method is asynchronous. When it returns, the transaction engine is simply guaranteed that the log entry has been assigned a unique LSN and submitted to the buffer of the leader. The transaction engine will be informed whether the log entry has been committed through the callback function AppendCb. Specifically, the success method will be invoked when the log entry is committed, meaning that it has been persisted by a majority of replicas and must not be lost; otherwise, the failure method will be called. PALF guarantees that the callback function of a log entry will be called at most once.
图 3 展示了一组与数据相关的 API,其中省略了诸如启动和重新配置等系统管理接口。PALF 提供了两种记录日志的方法:追加和镜像。追加方法将一条记录 r 提交给 PALF 组的领导者,它会返回一个 LSN 以标识日志条目。日志条目的 LSN 是单调递增的,它代表了日志条目在日志块上的物理偏移量。变更序列号(CSN)是另一个日志条目标识符,将在第 4.2 节中进行讨论。为了实现高吞吐量,追加方法是异步的。当它返回时,事务引擎仅保证日志条目已被分配一个唯一的 LSN 并提交给领导者的缓冲区。事务引擎将通过回调函数 AppendCb 接收关于日志条目是否已提交的信息。具体来说,当日志条目被提交时,会调用成功方法,这意味着它已被大多数副本持久化且不会丢失;否则,会调用失败方法。PALF 保证日志条目的回调函数最多只会被调用一次。

The mirror method offers another approach for writing logs to PALF, it is designed for mirrors of the PALF group and only accepts log entries committed by another PALF group. Only one of these two methods can write logs to a given PALF group at the same time (See §5.2).
镜像方法为将日志写入 PALF 提供了另一种方式,它专为 PALF 集群的镜像而设计,并且只接受由其他 PALF 集群提交的日志条目。这两种方法中只有其中一种能够同时向给定的 PALF 集群写入日志(见第 5.2 节)。
The read method enables random access to log entries by a given LSN. A locate method is provided to map the change sequence number to a log sequence number. To facilitate real-time log consumption in all replicas (e.g., log replayer), the monitor_tail method is provided to register a callback function TailCb to monitor the tail of the PALF group. When new logs are committed, PALF replicas invoke the tail method to notify log consumers of current tail of logs. The RoleCb function is used to coordinate the role of PALF replicas and the transaction engine. When the role of a PALF replica switches from leader to follower (follower to leader), the to_follower (to_leader) method will be invoked. Finally, the trim method is designed to indicate useless log entries before the given LSN. BlockGC is responsible for reclaiming these logs.
“read”方法允许根据给定的 LSN 对日志条目进行随机访问。还提供了“locate”方法,用于将变更序列号映射为日志序列号。为了便于在所有副本中实现实时日志消费(例如,日志重放器),提供了“monitor_tail”方法,用于注册回调函数 TailCb 来监控 PALF 组的尾部。当新日志被提交时,PALF 副本会调用 tail 方法通知日志消费者当前的日志尾部位置。RoleCb 函数用于协调 PALF 副本的角色和事务引擎。当一个 PALF 副本的角色从领导者切换到跟随者(或者从跟随者切换到领导者)时,将调用 to_follower(to_leader)方法。最后,trim 方法用于指示给定 LSN 之前的无用日志条目。BlockGC 负责回收这些日志。
3.4 Implementation of Consensus(共识的实施)
The Paxos protocol and its variants [6, 24, 26, 27, 32, 34] are widely recognized for resolving consensus in distributed systems [5, 9, 14, 23, 42, 48]. Raft[33] is a typical implementation of Paxos, which offers good understandability and builds a solid foundation for practical systems. PALF implements Paxos with a strong leader approach, it keeps the log replication of Raft for simplicity. Different from Raft, PALF decouples leader election from the consensus protocol to manipulate the location of the database leader without sacrificing availability. More differences are summarized in §7.
Paxos协议及其变体[6, 24, 26, 27, 32, 34]在分布式系统中解决共识问题方面得到了广泛认可[5, 9, 14, 23, 42, 48]。拉夫[33]是帕索斯协议的典型实现,它具有良好的可理解性,并为实际系统奠定了坚实的基础。PALF 采用强有力的领导者方法来实现帕索斯协议,它保留了拉夫的日志复制以保持简单性。与拉夫不同,PALF 将领导者选举与共识协议分离,从而能够在不牺牲可用性的情况下调整数据库领导者的位置。更多差异总结在第 7 节中。
Demands for Leader Election. In distributed databases, the location of the leader affects almost all functions, such as failure recovery, maintenance operations, and application preference. For example, in cross-region deployment, users tend to make the upper application and the database leader in the same region to reduce latency. Raft has provided a leadership transfer extension to manipulate the location of the leader[33]. However, the leadership transfer extension only works when both the previous leader and the desired leader are alive. If the previous leader crashed, whether a replica can be elected as the leader is completely restricted by the logs that it stores, rather than users’ desires. If an undesired replica is elected as the new leader, this relies on an external coordinator to detect failure and execute leadership transfer operation. This approach may incur availability risks to databases if the coordinator crashes.
关于领导选举的需求。在分布式数据库中,领导者的位置几乎会影响所有功能,例如故障恢复、维护操作以及应用程序偏好等。例如,在跨区域部署中,用户倾向于将上层应用和数据库的领导者置于同一区域,以减少延迟。Raft 提供了一个领导权转移扩展功能,用于调整领导者的位置[33]。然而,领导权转移扩展功能仅在前一领导者和目标领导者都存活的情况下才有效。如果前一领导者崩溃,是否可以选举一个副本作为领导者完全取决于它所存储的日志,而不是用户的意愿。如果一个不合适的副本被选举为新的领导者,这将依赖于外部协调器来检测故障并执行领导权转移操作。如果协调器崩溃,这种方法可能会给数据库带来可用性风险。
To address the problem, PALF decouples leader election from the consensus protocol. Users own the flexibility to specify the priorities of replicas elected as the leader. If the previous leader crashed, replicas with second-highest priority will be preferentially elected as the new leader without any external operations. If the previous leader recovers from failure and its priority is still higher than current leader’s, leadership can be automatically transferred back to the recovered replica.
为了解决这个问题,PALF 将领导者选举与共识协议分离开来。用户能够自主设定所选举为领导者的副本的优先级。如果之前的领导者出现故障,具有第二高优先级的副本将优先被选为新的领导者,而无需任何外部操作。如果之前的领导者从故障中恢复且其优先级仍高于当前领导者,领导权可以自动转移回恢复的副本。
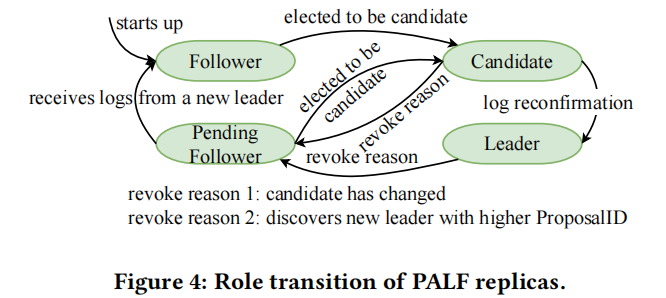
Role Transition. At any given time, each replica is in one of four roles: leader, follower, candidate, or pending follower. Figure 4 shows these roles and the transitions among them. The role of a replica is initiated to be follower when it starts up. Each replica periodically polls the election algorithm about whether the candidate is itself. If a follower finds that itself has become the candidate, it switches to candidate role and performs log reconfirmation, before taking over as a normal leader. We will introduce why the log reconfirmation is needed and its procedure in the following paragraph. If the leader finds that the candidate is not itself anymore or the leader receives messages from a new leader, it will revoke its leadership and switch to pending follower. The reason for switching to pending follower rather than follower is that the transaction engine may have appended some logs to the leader before the leadership transfer. To determine the replication results of these pending logs, the previous leader must enter the pending follower role and wait for logs from the new leader (§4.1). After the status of all pending logs is clear, the replica will switch to follower.
每个副本会定期向选举算法查询候选者是否就是它自己。如果一个跟随者发现自身已成为候选者,它就会切换到候选者角色并执行日志确认操作,然后接管为正常的领导者。我们将在接下来的段落中介绍为什么需要进行日志确认以及其具体流程。如果领导者发现候选者不再是它自己,或者领导者收到了来自新领导者的消息,它就会撤销其领导权并切换到待定跟随者状态。切换到待定跟随者而非跟随者的原因是,在领导权转移之前,事务引擎可能已向领导者附加了一些日志。为了确定这些待定日志的复制结果,前一领导者必须进入待定跟随者角色并等待来自新领导者的日志(§4.1)。在所有待定日志的状态都明确之后,副本将切换为跟随者。
Leader Election. The candidate is elected by a lease-based election algorithm, which ensures that no two or more replicas will be elected as candidates at the same time. Replicas can be assigned different election priorities by users, the election algorithm guarantees that the replica with the highest priority in a majority of replicas will be elected as a candidate. The election algorithm is essentially a variant of Basic Paxos, it reaches a consensus about which replica owns the highest priority in a majority. To ensure that, each replica tries to broadcast its priority to all replicas before proposing a new round of election; A replica will respond to a request which has the highest priority among all requests the replica has received in a certain duration. Besides that, the election algorithm utilizes monotonic timing in each replica to guarantee that a candidate will be elected within a certain time if any majority of replicas survives. This paper focuses the design of the replicated logging system, therefore, we leave implementation details of the election algorithm for another paper.
领导者选举。候选者通过基于租约的选举算法来选出,该算法确保不会有两个或更多的副本同时被选为候选者。用户可以为副本分配不同的选举优先级,选举算法保证在大多数副本中具有最高优先级的副本将被选为候选者。该选举算法本质上是基本帕克斯算法的一种变体,它就大多数副本中哪个副本拥有最高优先级达成共识。为了确保这一点,每个副本在提议新一轮选举之前都会尝试向所有副本广播其优先级;一个副本会响应在一定时间内它所收到的所有请求中优先级最高的请求。此外,该选举算法在每个副本中利用单调时间来保证,如果任何多数副本存活下来,那么在一定时间内将选举出一个候选人。本文专注于复制日志系统的设计,因此,我们将选举算法的实现细节留到另一篇论文中讨论。
Log Reconfirmation. Due to flexible leader election, the candidate may have fewer logs than other replicas. Before taking over as a leader, the candidate should re-confirm the logs appended by the previous leader to guarantee that its logs are not fewer than any replica in a majority. The log reconfirmation (Alg.1) is essentially a complete instance of Basic Paxos [27]. Specifically, the candidate broadcasts the advanced ProposalID(identifier for the leader’s term) pid + 1 to all replicas with Paxos Prepare messages (line 2). Each replica will store the pid of the Prepare message, and respond to the candidate with its logs, only if the pid in the Prepare message is larger than the maximum ProposalID pidmax the replica has seen (line 9). To avoid transporting useless logs, the acknowledgement of Prepare message only contains the tail LSN of logs.
日志确认。由于领导选举具有灵活性,候选者拥有的日志数量可能少于其他副本。在接任领导角色之前,候选者应重新确认由前领导者添加的日志,以确保其日志数量不低于大多数副本中的任何一份。日志确认(算法 1)本质上是基本帕索斯算法[27]的一个完整实例。具体而言,候选者通过发送 Paxos 准备消息(第 2 行)将“提议 ID(领导者的任期标识符)pid + 1”广播给所有副本,并且每个副本都会存储准备消息中的 pid,并仅在准备消息中的 pid 大于该副本已见过的最大提议 ID pidmax 时(第 9 行)向候选者返回其日志。为了避免传输无用的日志,准备消息的确认仅包含日志的尾部 LSN。

Once the candidate receives votes from any majority of replicas (line 3), it starts the Paxos accept phase: selecting the replica with the longest logs (line 4), getting logs from it (line 5), and replicating these logs to all replicas (line 6). Finally, the candidate replicates a StartWorking log to all replicas (line 8). Note that the StartWorking log is a special reconfiguration log (§5.3), it is used to roll back the possible uncommitted membership of the previous leader. The candidate will serve as the leader as long as the StartWorking log reaches majority.
一旦候选节点从任何多数的副本那里获得投票(第 3 行),它就会启动帕克斯协议的接受阶段:选择具有最长日志的副本(第 4 行),从该副本获取日志(第 5 行),并将这些日志复制到所有副本(第 6 行)。最后,候选节点会将一个“开始工作”日志复制到所有副本(第 8 行)。请注意,“开始工作”日志是一种特殊的重新配置日志(第 5.3 节),用于回滚前一领导者的可能未提交的成员资格。只要“开始工作”日志达到多数,该候选节点就会担任领导角色。
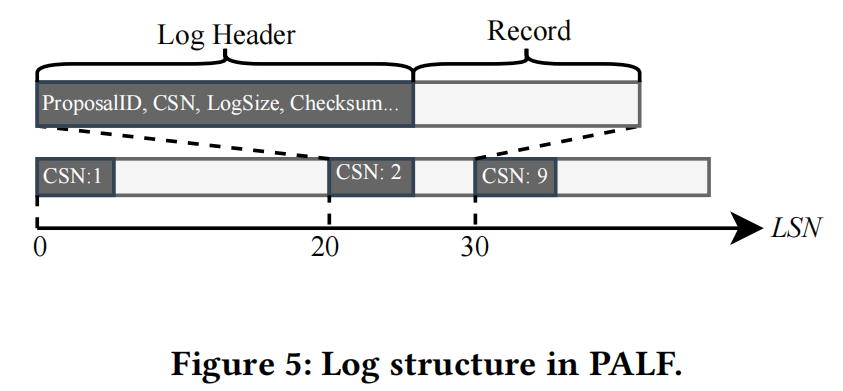
Log Replication. Once a leader takes over successfully, it takes the responsibility for replicating and committing logs. Log replication in PALF resembles that in Raft [34]. Briefly, log entries are appended to the leader, replicated by the leader, acknowledged by followers, and committed by the leader in the order of LSN. When records are appended to the leader, a log sequence number (LSN) will be assigned to each log entry by the log sequencer. The LSN indicates the physical offset at which the log entry is stored in log blocks. As shown in Fig. 5, log blocks in LogStorage continuously store log entries, the LSN of the next log entry is equal to the sum of the current log’s LSN and the log size. The way of identifying log entries with LSN makes clients operate PALF just like a normal file and facilitates redo log consumption in databases.
日志复制。一旦领导者成功接管任务,它便承担起复制和提交日志的责任。在 PALF 中的日志复制与 Raft 中的类似[34]。简而言之,日志条目会被添加到领导者那里,由领导者进行复制,由从属节点进行确认,并由领导者按照 LSN 的顺序进行提交。当向领导者添加记录时,日志序列器会为每个日志条目分配一个日志序列号(LSN)。LSN 表示日志条目在日志块中的物理偏移量。如图 5 所示,LogStorage 中的日志块持续存储日志条目,下一个日志条目的 LSN 等于当前日志的 LSN 与日志大小的总和。使用 LSN 标识日志条目的方式使客户端能够像操作普通文件一样操作 PALF,并有助于数据库中重做日志的消耗。
When a log entry arrives at a follower, the follower will not accept it until all preceding logs have been accepted. If existing logs conflict with new logs with higher proposal number, PALF will truncate the conflicting logs in the same way as Raft. This mechanism establishes the log matching property [34].
当一条日志条目到达从属节点时,该从属节点在未接收到所有前置日志之前不会接受该条目。如果现有的日志与具有更高提议编号的新日志存在冲突,PALF 将会像 Raft 那样对冲突的日志进行截断处理。这种机制确立了日志匹配特性[34]。
Correctness. Benefiting from the safety argument in Raft, we simply need to validate whether PALF ensures the following properties: election safety, leader append-only, log matching, leader completeness, and state machine safety. The leader append-only and log matching are provided by PALF naturally because it borrows the same log replication scheme from Raft. The key difference between Raft and PALF is the log reconfirmation. The candidate performs an instance of Basic Paxos to learn missing logs from the replica that accepted the most logs in a majority. If a log entry submitted by the previous leader has been accepted by a majority, it must be seen and learned by the candidate, and therefore election safety and leader completeness are ensured. We leave the proof of the state machine safety property in §4.1, because it is related to the way of applying logs to the transaction engine.
正确性。得益于 Raft 中的安全性论证,我们只需验证 PALF 是否能确保以下特性:选举安全性、领导者只写日志、日志匹配、领导者完整性以及状态机安全性。领导者只写日志和日志匹配特性是由于 PALF 自然具备而得以实现的,因为它是借鉴了 Raft 中相同的日志复制方案。Raft 和 PALF 之间的关键区别在于日志确认。候选者会执行一次基本 Paxos 操作,从接受到最多日志的副本那里学习缺失的日志。如果先前领导者提交的日志条目已被多数节点接受,那么它就必须被候选者看到并学习,从而确保选举安全性和领导者完整性。我们将状态机安全性的证明留到第 4.1 节,因为这与将日志应用于事务引擎的方式有关。
4 INTERACTION WITH TRANSACTION ENGINE(与交易引擎的交互)
This section introduces the features of PALF designed for the transaction engine of OceanBase database based on the implementation of consensus protocol.
本节介绍基于共识协议的实现,专为 OceanBase 数据库事务引擎设计而开发的 PALF 特性。
4.1 Explicit Replication Results(明确的重复实验结果)
If the leadership has been transferred away due to a network hiccup, the previous leader may be unclear about whether appended log entries are committed, these logs are referred to as pending logs. Pending logs may incur complexities for the transaction engine. For example, the transaction engine generates a commit record of a transaction and appends it to PALF. If the leader loses its leadership unexpectedly, the transaction engine must decide whether to commit or rollback the transaction according to whether the commit record has been persisted.
如果由于网络故障导致领导权转移,那么前任领导可能不清楚附加的日志条目是否已成功提交,这些日志被称为待处理日志。待处理日志可能会给事务引擎带来复杂性。例如,事务引擎会生成一个事务的提交记录,并将其附加到 PALF 中。如果领导意外失去领导权,事务引擎必须根据提交记录是否已持久化来决定是提交还是回滚该事务。
PALF guarantees that the transaction engine will be explicitly notified of replication results unless the leader crashes or the network is interrupted permanently. The leader is responsible for committing logs and notifying of results. If the leadership has been transferred to another replica, the previous leader switches itself to pending follower. When the pending follower receives logs from the new leader, the replication results of pending logs become explicit (committed or truncated). Replication results of committed logs will be notified by calling the success function, truncated logs will be notified as failed replications by invoking the failure function. This is why the previous leader must switch to pending follower and wait for logs from the new leader before it becomes a follower. For each record, only one of the callback functions will be invoked, and it will be called at most once.
PALF 确保交易引擎会接收到复制结果的通知,除非领导者崩溃或者网络永久中断。领导者负责提交日志并通知结果。如果领导权已转移至另一个副本,之前的领导者会自动切换为待命的从机。当待命的从机从新领导者处接收日志时,待命日志的复制结果就会变得明确(已提交或已截断)。已提交日志的复制结果会通过调用成功函数来通知,而已截断的日志则会通过调用失败函数来表示失败的复制。这就是为什么之前的领导者必须切换为待命从机,并等待新领导者发送的日志之后才能成为从机。对于每条记录,只会调用其中一个回调函数,并且最多只会被调用一次。
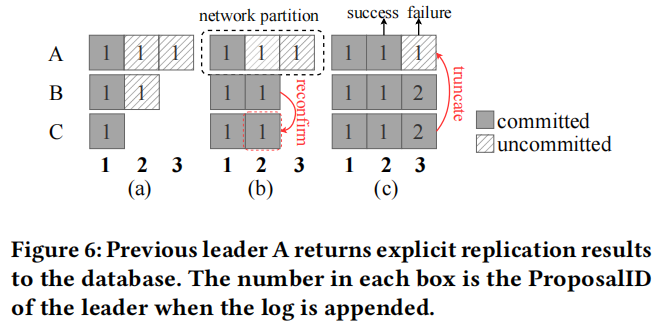
As depicted in Fig. 6a, the previous leader A committed log1, log2 and log3 have been appended to replica A, but have not been replicated. Then A has been partitioned off from B and C temporarily, C was elected as the leader and reconfirmed log2 from B (Fig. 6b). After the network recovers (Fig. 6c), replica A has been transformed to pending follower because its election lease has expired. It receives logs from the new leader C, log2 in A will be accepted because it has been committed by the new leader. As a result, replica A informs the database of replication results about log2 by calling success function. In contrast, log3 in A will be truncated because another log3 from C contains larger ProposalID. The log3 replicated by the previous leader A fails to reach consensus, therefore replica A invokes failure function to notify the database.
如图 6a 所示,先前的领导者 A 将 log1、log2 和 log3 添加到了副本 A 中,但并未进行复制。随后,A 与 B 和 C 分开暂时处于隔离状态,C 被选为领导者,并从 B 复核了 log2(图 6b)。在网络恢复后(图 6c),副本 A 已转变为待跟从状态,因为其选举租约已过期。它从新的领导者 C 处接收日志,因为 A 中的 log2 已被新领导者确认为已提交,所以会被接受。因此,副本 A 通过调用成功函数向数据库报告关于 log2 的复制结果。相比之下,A 中的 log3 将被截断,因为来自 C 的另一个 log3 包含更大的 ProposalID。先前领导者 A 执行的 log3 复制未能达成共识,因此副本 A 调用失败函数通知数据库。
Note that if the leader A crashes in Fig. 6a, PALF does not need to notify the database of replication results directly, because all states in memory will be lost. When it starts to recover, the transaction engine switches to follower, receives logs from the new leader, and replays local logs to recover transactions. The previous leader can not provide replication results if its network is interrupted, because the new leader can not reach it. If the network recovers, the previous leader can receive logs and determine whether in-flight logs have been committed.
请注意,如果图 6a 中的领导者 A 出现故障,PALF 不需要直接将复制结果通知给数据库,因为内存中的所有状态都会丢失。在开始恢复时,事务引擎会切换到从属节点,接收来自新领导者的日志,并重放本地日志以恢复事务。如果前一领导者的网络中断,它就无法提供复制结果,因为新领导者无法与它取得联系。如果网络恢复,前一领导者可以接收日志并确定正在进行的日志是否已提交。
The state machine safety property of the consensus protocol is ensured by the explicit replication results. If a log has been committed, it must have been applied to the leader and will be replayed to the follower. If PALF fails to reach consensus on the log, state machine of the previous leader will be rolled back by calling the failure function.
共识协议的状态机安全性特性通过明确的复制结果得以保障。如果一个日志已被提交,那么它必须已应用到领导者,并且还会被回放给从属节点。如果 PALF 未能就该日志达成共识,先前领导者的状态机将通过调用故障函数进行回滚。
4.2 Change Sequence Number(更改序列号)
Data synchronization tools (such as Change Data Capture) usually consume transactions in the order of logs; however, the LSN is incompetent for tracking the order of transactions because it is locally ordered within single PALF group. For scalability, data partitions are usually distributed among multiple Streams. If different transactions modify data partitions in different Streams, the LSNs of their logs are incomparable. To track the order of transactions with logs across PALF groups, a natural approach is to record commit versions of transactions in the payloads of log entries, as some systems have done [18, 42]. This approach does work, but it has disadvantages. For instance, commit versions may not strictly increase with LSN due to parallel executions of transactions (i.e.,assigning smaller LSN to logs of transactions with greater commit version). This approach requires log consumers to parse payloads of logs, which incurs additional overhead.
数据同步工具(例如变更数据捕获工具)通常会按照日志的顺序来处理事务;然而,LSN(逻辑序列号)无法用于追踪事务的顺序,因为其在单个 PALF 组内是本地有序的。为了实现可扩展性,数据分区通常会分布在多个流中。如果不同的事务在不同的流中修改数据分区,它们日志的 LSN 将无法进行比较。为了通过日志在不同 PALF 组之间追踪事务的顺序,一种自然的方法是在日志条目的数据包中记录事务的提交版本,一些系统已经采用了这种方法[18, 42]。这种方法确实有效,但也有缺点。例如,由于事务的并行执行(即为具有更高提交版本的事务分配较小的 LSN),提交版本可能不会严格随着 LSN 的增加而增加。这种方法要求日志消费者解析日志的数据包,这会带来额外的开销。
PALF provides another log entry identifier, Change Sequence Number (CSN), which maintains consistency with LSN and reflects the order of transactions across multiple PALF groups. CSN is a 64-bit integer stored in the header of each log entry. PALF does not infer the meaning of CSN, meaning that the overhead of maintaining and recognizing CSN is very small. The log sequencer in the leader allocates LSN and CSN to logs when the append method is invoked. PALF maintains an invariant on CSN: monotonic increasing within a PALF group. Within each PALF group, for any two logs α and β , if the LSN of α is greater or equal to the LSN of β , then the CSN of α must be greater or equal to the CSN of β . Formally,
PALF 还提供了另一种日志条目标识符——更改序列号(CSN),它与 LSN 保持一致,并能反映多个 PALF 组中事务的执行顺序。CSN 是一个 64 位整数,存储在每个日志条目的头部。PALF 不解释 CSN 的含义,这意味着维护和识别 CSN 所需的开销非常小。在领导者中的日志序列器在调用追加方法时为日志分配 LSN 和 CSN。PALF 对 CSN 保持一个不变的特性:在一个 PALF 组内是单调递增的。在每个 PALF 组中,对于任何两个日志 α 和 β ,如果 α 的 LSN 大于或等于 β 的 LSN ,那么 α 的 CSN 必须大于或等于 β 的 CSN 。理论上,
![]()
The invariant guarantees that CSN increases monotonically within PALF group and thereby keeps consistent with the order of LSN. Figure 5 shows a visualization of the relationship between LSN and CSN of logs. The CSN is persisted along with the log entry. As a result, the above invariant is always valid even if the leader crashes.
该不变量确保了在 PALF 组中,CSN 会单调递增,从而与 LSN 的顺序保持一致。图 5 展示了日志的 LSN 和 CSN 之间的关系可视化。CSN 会与日志条目一起被持久化。因此,即使领导者崩溃,上述不变量也始终有效。
PALF provides another key guarantee: for the append method, its input argument Re f CSN and its output argument CSN always follow CSN >= Re f CSN. Re f CSN serves as a causal reference; the guarantee indicates that the log entry must be appended after the event happened at Re f CSN. Therefore, the CSN of a log can reflect the system-wide order if the Re f CSN is a globally-meaningful value.
PALF 还提供了另一个关键保障:对于追加方法而言,其输入参数“ref CSN”以及其输出参数“CSN”始终满足“CSN >= ref CSN”。“ref CSN”起到了因果参考的作用;该保障意味着日志条目必须在事件发生在“ref CSN”处之后进行追加。因此,如果“ref CSN”是一个具有全局意义的值,那么日志的“CSN”就能反映整个系统的顺序。
The OceanBase database provides globally meaningful commit versions to transactions using CSN. When a transaction is going to be committed, the transaction engine fetches a timestamp from a global timestamp oracle and appends the commit record with the timestamp as Re f CSN. The CSN returned by the append method tracks the order indicated by Re f CSN and acts as the commit version of the transaction. Note that the CSN is not generated by the global timestamp oracle, which may have a value greater than the current global timestamp. As a result, the transaction may be invisible to a future read request that fetches a smaller readable version from the global timestamp oracle. To avoid this, the transaction engine will not respond to the client until the global timestamp is greater than the CSN. Through cooperation between the transaction engine and PALF, CSN successfully tracks the order of transactions across PALF groups.
OceanBase 数据库通过 CSN 为事务提供具有全球意义的提交版本。当一个事务即将被提交时,事务引擎会从全局时间戳数据库中获取一个时间戳,并将包含该时间戳的提交记录作为“引用 CSN”附加到提交记录中。通过该附加方法返回的 CSN 跟踪了“引用 CSN”所指示的顺序,并充当该事务的提交版本。请注意,CSN 并非由全局时间戳数据库生成,该数据库的值可能大于当前的全局时间戳。因此,如果未来的读取请求从全局时间戳数据库中获取较小的可读版本,则该事务可能对这些请求不可见。为了避免这种情况,事务引擎在全局时间戳大于 CSN 之前不会响应客户端。通过事务引擎与 PALF 的协作,CSN 成功地在 PALF 组之间跟踪事务的顺序。
Another database feature that benefits from CSN is follower reads. Follower reads enable follower replicas to serve read-only requests with an eventual consistency guarantee to reduce latency. Read requests with T that can read complete data in followers require that all logs with CSN less than T have been replayed in the follower and commit versions of any future write should be greater than T . The monotonic increasing property of CSN provides this guarantee naturally. Logs are replicated and replayed to followers in the order of LSN, which is consistent with the order of CSN. If the log with CSN T has been replayed in the follower, CSN of the following logs must be greater than T . Compared to other distributed databases that advance readable timestamps in followers by broadcasting special commands periodically (e.g., closed timestamps [43]), the follower read feature of the OceanBase database does not require additional mechanisms.
另一个得益于 CSN 的数据库特性是“跟随者读取”。跟随者读取功能使得跟随者副本能够以最终一致性的方式处理只读请求,并减少延迟。具有参数 T 的读取请求需要确保所有 CSN 小于 T 的日志已在跟随者中重放,并且任何未来的写入的提交版本都应大于 T 。CSN 的单调递增特性自然地提供了这种保证。日志按照 LSN 的顺序复制并重放到跟随者中,这与 CSN 的顺序是一致的。如果具有 CSN T 的日志已在跟随者中重放,那么后续的日志的 CSN 必须大于 T 。与那些通过定期广播特殊命令(例如关闭时间戳[43])在跟随者中逐步更新可读时间戳的其他分布式数据库相比,OceanBase 数据库的跟随者读取功能不需要额外的机制。
5 DATA CHANGE SYNCHRONIZATION(数据变更同步)
Besides serving transactions, distributed databases also act as the source of data flow. Downstream applications can be deployed to provide various services by synchronizing data changes recorded in physical logs. This section introduces two typical physical log synchronization scenarios in OceanBase, describes what challenges they bring to PALF, and depicts how to address these challenges by utilizing features of PALF.
除了用于处理事务之外,分布式数据库还充当数据流的来源。下游应用程序可以部署以提供各种服务,通过同步物理日志中记录的数据更改来实现这一功能。本节介绍了 OceanBase 中的两种典型的物理日志同步场景,描述了它们给 PALF 带来哪些挑战,并展示了如何利用 PALF 的功能来解决这些挑战。
5.1 Overview(概述)
When clients write data to databases, records of modifications are appended to the leader of the PALF group and replicated to followers. Besides replicating logs within the database, data changes can be synchronized out of the database for richer functions. There are two typical scenarios in the OceanBase database: physical standby databases and database restore.
当客户向数据库写入数据时,修改记录会被附加到 PALF 组的组长中,并复制给从属节点。除了在数据库内部复制日志外,还可以将数据更改同步到数据库之外以实现更丰富的功能。在 OceanBase 数据库中,有两种典型的场景:物理备用数据库和数据库恢复。
As shown in Figure 7, the physical standby database is an independent database in which the data are identical to the primary database. It could serve part of read requests to relieve pressure on the primary database. Compared to traditional primary-backup architecture, it offers higher availability because each database cluster can tolerate failures. One of the most important features of the physical standby database is database-level data protection and disaster recovery, a physical standby database can be switched to be the primary database by a failover operation if the original primary database becomes unavailable, which distinguish it from replicalevel protection such as Paxos learners [7]. In production databases, database restore is a core component of the high-reliability feature. If data have been lost due to storage media damage or human errors, archived logs stored in offline storage (such as NFS or Cloud Object Stores) could be used to restore an identical database.
如图 7 所示,物理备用数据库是一个独立的数据库,其数据与主数据库完全相同。它可以处理部分读取请求,以减轻主数据库的压力。与传统的主备架构相比,它提供了更高的可用性,因为每个数据库集群都能容忍故障。物理备用数据库最重要的特征是数据库级别的数据保护和灾难恢复。如果原主数据库不可用,通过故障转移操作,物理备用数据库可以切换成为主数据库,这使其与诸如 Paxos 学习者(7)这样的复制级别保护有所不同。在生产数据库中,数据库恢复是高可靠性功能的核心组件。如果由于存储介质损坏或人为错误导致数据丢失,存放在离线存储(如 NFS 或云对象存储)中的归档日志可用于恢复一个完全相同的数据库。
The basic idea behind physical standby databases or database restore is similar: synchronizing data changes recorded in physical logs from the primary database or external storage to the standby database or the restoring database. For the OceanBase database, one of the challenges in implementing these features is synchronizing logs from one PALF group (or external storage) to another PALF group. In addition, these PALF groups should be independently available. A naïve solution is to read log entries from the PALF group in the primary database and append the logs to the corresponding PALF group in the standby database as records (Fig. 3). However, the consensus protocol will attach a log header to the appended record for replication, which results in inconsistency between the log format of the primary database and that of the standby databases.
物理备用数据库或数据库恢复的基本思路是相似的:将主数据库或外部存储中记录的数据更改同步到备用数据库或恢复数据库中。对于 OceanBase 数据库而言,实现这些功能时面临的一个挑战是将一个 PALF 组(或外部存储)中的日志同步到另一个 PALF 组。此外,这些 PALF 组应独立可用。一个简单的解决方案是读取主数据库中的日志条目,并将这些日志附加到备用数据库中对应的 PALF 组中作为记录(图 3)。然而,共识协议会在附加的记录上附加一个日志头以进行复制,这导致主数据库的日志格式与备用数据库的日志格式不一致。
5.2 PALF Group Mirror(PALF组镜像)
We abstracted the requirements of synchronizing data changes across PALF groups as a primitive: the PALF group mirror, which is an independent PALF group that performs the same consensus protocol as described in §3.4. It maintains a mirror of the data change prefixes, which are stored in the primary PALF group or external storage. The PALF group mirror can be reconfigured independently and be switched to a primary group as needed.
我们将跨 PALF 组同步数据变更的需求抽象为一个基本单元:PALF 组镜像,这是一种独立的 PALF 组,其执行与第 3.4 节中所述相同的共识协议。它维护着数据变更前缀的镜像,这些前缀存储在主 PALF 组或外部存储中。PALF 组镜像可以独立进行重新配置,并根据需要切换为主组。
One of the most important differences between the primary PALF group and PALF group mirrors is the pattern of writing log records. In primary PALF group, a log record is appended to the PALF group, attached with a log header, and replicated to replicas by the consensus protocol. As for the PALF group mirror, it only accepts logs committed by a primary PALF group. When a committed log is mirrored to the leader, some fields of the log header (e.g., ProposalID) will be replaced with the leader’s own values. The leader reuses the LSN and CSN of the original log entries, stores logs to the LSN, and replicates logs to followers.
主 PALF 组与 PALF 组之间的最重要区别之一在于日志记录的写入模式。在主 PALF 组中,日志记录会被附加到 PALF 组中,并附带一个日志头,然后通过共识协议复制到副本中。而对于 PALF 组的镜像部分,它只接受由主 PALF 组提交的日志。当已提交的日志被镜像到领导者时,日志头的一些字段(例如 ProposalID)将被替换为领导者自身的值。领导者会重新使用原始日志条目的 LSN 和 CSN,将日志存储到 LSN 中,并将日志复制给从属节点。
Two access modes Primary and Mirror were proposed to differentiate the primary PALF group from its mirrors. The access mode of a PALF group can be switched by failover or switchover operations. The problem is how to broadcast the new access mode to all replicas atomically. Obviously, the atomic broadcast of access mode is equivalent to the consensus problem [12]. Hence, a basic Paxos was implemented to switch the access mode of PALF groups and store each replica’s access mode to MetaStorage.
提出了两种访问模式——“主模式”和“镜像模式”,以将主 PALF 组与其镜像区分开来。PALF 组的访问模式可以通过故障转移或切换操作进行切换。问题在于如何以原子方式将新的访问模式广播给所有副本。显然,访问模式的原子广播等同于共识问题[12]。因此,实现了一个基本的 Paxos 算法来切换 PALF 组的访问模式,并将每个副本的访问模式存储到元存储中。
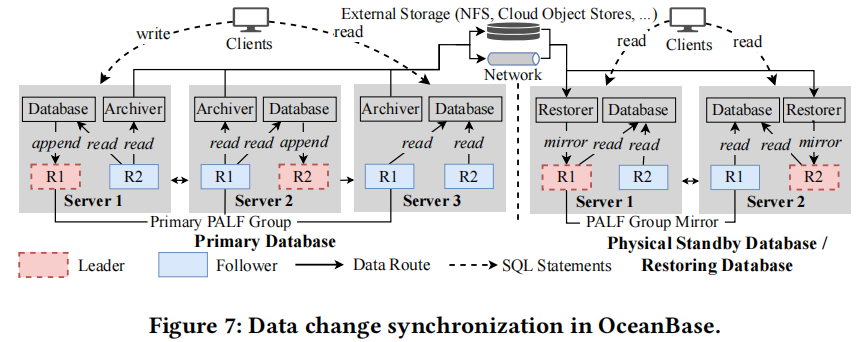
With the PALF group mirror primitive, constructing a data change synchronization architecture for OceanBase database becomes natural. As shown in Figure 7, all PALF groups in the physical standby database are mirrors of PALF groups in the primary database, and all PALF groups in the restoring database are mirrors of data changes stored in external storage. After transaction logs have been committed by the primary PALF group, log archivers read logs from each PALF group and then store them in external storage or transport them to the standby database. In the physical standby database, restorers receive logs from the archivers (fetch logs from external storage) and mirror logs to the leader of PALF group mirrors. After logs have been committed by the leader, they will be replayed to the transaction engine in all replicas (including the leader). As a result, transactions that execute in the primary database will be synchronized to the physical standby database; database restore performs a similar procedure.
借助 PALF 组镜像原语,为 OceanBase 数据库构建数据变更同步架构变得十分自然。如图 7 所示,物理备用数据库中的所有 PALF 组都是主数据库中 PALF 组的镜像,而恢复数据库中的所有 PALF 组都是外部存储中所存储数据变更的镜像。在主 PALF 组完成事务日志提交后,日志归档器从每个 PALF 组读取日志,然后将其存储在外部存储中或传输到备用数据库。在物理备用数据库中,恢复者从归档器处接收日志(从外部存储中获取日志),并将日志镜像到 PALF 组镜像的领导者。在领导者完成日志提交后,这些日志将被重放给所有副本(包括领导者)中的事务引擎。因此,主数据库中执行的事务将同步到物理备用数据库;数据库恢复则执行类似的流程。
It is worth noting that the interaction between the transaction engine and the PALF group in standby databases is different from that in primary databases. In standby databases, the transaction engines perform the standard RSM model, and all replicas simply read log records from PALF replicas and replay data changes to data partitions. Therefore, the role of a transaction engine is always follower, even though the role of the PALF replica may be leader.
值得注意的是,事务引擎与备用数据库中的 PALF 组之间的交互与在主数据库中的交互有所不同。在备用数据库中,事务引擎执行标准的 RSM 模型,而所有副本只是从 PALF 副本读取日志记录,并将数据更改重放到数据分区中。因此,事务引擎的角色始终是跟随者,尽管 PALF 副本的角色可能是领导者。
5.3 Independent Reconfiguration(独立重配置)
Many implementations of consensus protocols [2, 15] store and replicate reconfiguration commands as normal log entries; however, this embedded approach may be harmful to the usability of PALF group mirrors. First, the transaction engine must filter useless reconfiguration commands because they only concern the data changes that they wrote. Second, the membership of a PALF group mirror is different from that of the primary PALF group, and it should be capable of being reconfigured independently. However, a PALF group mirror can only accept logs from its primary group. As a result, physical standby databases cannot be reconfigured by writing reconfiguration commands as common log records.
许多共识协议的实现方式[2, 15]都将重新配置命令作为常规的日志条目进行存储和复制;然而,这种嵌入式的方法可能会对 PALF 集群镜像的可用性造成不利影响。首先,事务引擎必须过滤掉无用的重新配置命令,因为这些命令只涉及它们所写入的数据更改。其次,PALF 集群镜像的成员身份与主 PALF 集群的成员身份不同,并且它应该能够独立地进行重新配置。然而,PALF 集群镜像只能接受来自其主群的日志。因此,物理备用数据库无法通过将重新配置命令作为常规的日志记录进行写入来重新配置。
The reconfiguration of PALF resembles the single-server approach described in Raft [33], only one replica can be added or removed at a time. The leader replicates a reconfiguration log which records new membership and commits it with the acknowledgements of new membership. Each replica updates its own membership upon receiving a newer reconfiguration log. To make the PALF group mirror can be reconfigured independently, PALF stores the reconfiguration log in MetaStorage, which is separated from LogStorage.
PALF 的重新配置类似于 Raft 文中所描述的单服务器方法[33],即每次只能添加或删除一个副本。领导者会复制一个重新配置日志,该日志记录新的成员信息,并在获得新成员确认后进行提交。每个副本在接收到更新的重新配置日志后会更新自身的成员信息。为了使 PALF 集群镜像能够独立重新配置,PALF 将重新配置日志存储在 MetaStorage 中,而 LogStorage 则与之分离。
Independent meta-storage is not as simple as it seems, it may harm the safety of the consensus protocol, following examples demonstrate some thorny problems caused by independent metastorage. As shown in Figure 8a, all logs with LSN less than or equal to 5 has been committed by leader A, where A, D, and E have the latest logs, but B and C are behind. Leader A wants to remove replicas D and E from the group by replicating new membership to replicas that are in new membership; a safety risk that committed logs are lost may occur. Specifically, some committed logs (3, 4, 5) have not been flushed by any majority of new membership (A, B, C). If replica A crashes after D and E have been removed, these logs will be lost. Figure 8b illustrates a possible split-brain[11] situation when reconfiguring clusters successively. After replacing replica E with replica F by removing replica E and adding replica F, replica B and F could vote for A, but replica C and E vote for D. As a result, two leaders, A and D, will be elected.
独立的元存储并非像看起来那样简单,它可能会损害共识协议的安全性。以下示例展示了独立元存储所引发的一些棘手问题。如图 8a 所示,所有 LSN 小于或等于 5 的日志已被领导者 A 提交,其中 A、D 和 E 拥有最新的日志,而 B 和 C 则落后。领导者 A 试图通过向新的成员中已有的副本复制新的成员信息来从该组中移除副本 D 和 E;这可能会导致已提交的日志丢失的安全风险。具体而言,一些已提交的日志(3、4、5)尚未被任何多数的新成员(A、B、C)刷新。如果在 D 和 E 被移除后副本 A 出现故障,这些日志将会丢失。图 8b 展示了在依次重新配置集群时可能出现的“双脑”[11]情况。通过移除副本 E 并添加副本 F 来替换副本 E,副本 B 和 F 可以投票给 A,但副本 C 和 E 投票给 D。结果,将选举出两个领导者,A 和 D。

PALF introduces constraints on reconfiguration and leader election to address these anomalies. For reconfiguration, the leader issues a new configuration along with a log barrier to followers. The barrier is the tail of logs in the leader when it issued the configuration. Each follower refuses to accept a configuration until its flushed logs before the barrier. Therefore, replica B or C will not accept a new configuration until it accepts all logs (3, 4, and 5) before the barrier (Fig. 8a). For leader election, PALF maintains config version to indicate the version of membership; reconfiguration operation will increment it. The config version acts as the chief election priority, therefore replica D will not be elected as the leader because its config version is lower than that of replica C (Fig. 8b).
PALF 对重新配置和领导者选举进行了限制,以解决这些异常情况。对于重新配置,领导者会发布新的配置,并附上一个日志屏障给从属节点。该屏障是领导者在发布配置时所发出的日志尾部。每个从属节点在接收该配置之前,都会拒绝接受任何其在屏障之前已刷新的日志。因此,副本 B 或 C 会一直拒绝接受新的配置,直到它们接受了屏障之前的所有日志(3、4 和 5)(图 8a)。对于领导者选举,PALF 保持配置版本以指示成员关系的版本;重新配置操作会增加该版本。配置版本充当主要选举优先级,因此副本 D 由于其配置版本低于副本 C 的配置版本,所以不会被选举为领导者(图 8b)。
It is argued here that even though independent meta-storage incurs extra complexities to consensus protocol, it is advantageous because it makes meta-information invisible to log consumers and enables PALF group mirrors to reconfigure clusters independently.
在此文中,有人提出,尽管独立的元存储会增加与共识协议相关的复杂性,但这种做法是有益的,因为它使得元信息对日志消费者而言是不可见的,并且使 PALF 集群镜像能够独立地重新配置集群。
6 PERFORMANCE OPTIMIZATION(性能优化)
As described in §2.2, the transaction engine imposes massive redo logs of multiple data partitions on a single PALF group, which may make PALF become a bottleneck. This section introduces how PALF is designed systematically for maximizing the performance of PALF.
如第 2.2 节所述,事务引擎将多个数据分区的大量重做日志集中存储在一个 PALF 组中,这可能会使 PALF 成为性能瓶颈。本节将介绍如何系统地设计 PALF 以最大限度地提高其性能。
Pipelining Replication. To improve throughput, PALF processes and replicates logs concurrently by exploiting modern multicore processors. The consensus-related states of multiple logs are cached in an in-memory sliding window to avoid CPU cache miss. Therefore, replication stages of multiple logs can be overlapped.
流水线式复制。为了提高吞吐量,PALF 通过利用现代多核处理器来同时处理和复制日志。多个日志的相关共识状态被缓存在内存中的滑动窗口中,以避免 CPU 缓存未命中。因此,多个日志的复制阶段可以重叠进行。
Adaptive Group Replication The consensus protocol incurs additional overhead to database, which contains at least two network messages (log replication and acknowledgement) and some CPU cycles. Batching multiple log entries in one instance is a common way to dilute the overhead incurred by consensus. At the heart of batching logs lies how to determine an appropriate batch size. Batching logs periodically or batching logs immediately when the I/O worker is idle (feedback) are two common approaches. However, the former may incur additional latency under low concurrency. The latter may harm throughput because a massive number of small requests may overwhelm I/O devices under high concurrency.
自适应组复制 共识协议会为数据库带来额外的开销,其中包括至少两段网络消息(日志复制和确认)以及一些 CPU 资源。在一个实例中批量处理多个日志条目是减轻共识所带来开销的常见方法。批量处理日志的核心在于如何确定合适的批量大小。定期批量处理日志或在 I/O 工作器空闲时立即批量处理日志(反馈)是两种常见的方法。然而,前者在低并发情况下可能会导致额外的延迟。后者可能会降低吞吐量,因为在高并发情况下大量小请求可能会使 I/O 设备不堪重负。
PALF replicates logs with adaptive group size to balance latency and throughput. The leader caches appended logs within a group buffer. The freeze operation will pack cached logs into a group log entry and then replicates it to followers. The number of log entries within a group log entry (group factor) depends on how often the freeze operation is performed. The key idea of adaptive group replication is to freeze logs periodically under low concurrency and freeze logs according to I/O worker feedback under high concurrency, but the concurrency of clients is difficult to measure directly. Suppose that n clients are appending records r to PALF concurrently. If logs of all clients are appended, but have not been committed, these cached logs should be frozen to a group log gl immediately, without waiting for a constant interval. Therefore, the degree of concurrency (n) correlates with the group factor (gf , the number of cached logs), which is easy to measure by counting logs. The relation can be formalized as:
PALF 通过自适应的分组大小来复制日志,以平衡延迟和吞吐量。领导者会在组缓冲区中缓存一组中的附加日志。冻结操作会将缓存的日志打包成一个组日志条目,然后将其复制给从属节点。组日志条目内的日志条目数量(组因子)取决于冻结操作的执行频率。自适应分组复制的关键思想是在低并发情况下定期冻结日志,在高并发情况下根据 I/O 工作器的反馈来冻结日志,但客户端的并发程度难以直接测量。假设 n 个客户端同时向 PALF 追加记录 r。如果所有客户端的日志都已追加但尚未提交,那么这些缓存的日志应立即被冻结到一个组日志 gl 中,而无需等待固定的间隔时间。因此,并发程度(n)与组因子(gf,缓存的日志条目数量)相关,可以通过计数日志来轻松测量。这种关系可以形式化为:
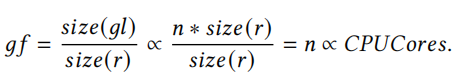
Experimentally, the degree of concurrency is proportional to the number of CPU cores occupied by PALF, and hence the group factor threshold could be determined by hardware resources rather than manually tuning a batch size. If the group factor is smaller than the threshold, this means that concurrency is low, and PALF will freeze logs if the I/O worker is idle, otherwise, PALF will freeze logs at a constant interval (1 ms by default). Compared to existing batching algorithms [20], adaptive group replication is simple and predictable enough, and is suitable for production deployment.
通过实验可知,并发程度与 PALF 占用的 CPU 核心数量成正比,因此组因子阈值可以由硬件资源来确定,而无需手动调整批处理大小。如果组因子小于阈值,这意味着并发程度较低,如果 I/O 工作器处于空闲状态,PALF 将会暂停日志记录;否则,PALF 将每隔固定时间(默认为 1 毫秒)暂停一次日志记录。与现有的批处理算法[20]相比,自适应组复制简单且具有可预测性,非常适合生产环境部署。
Lock-Free Write Path Instead of improving throughput, a high level of concurrency may degrade performance if severe contention occurs. A lock-free write path has therefore been designed for PALF to avoid contention among threads. The main components in the write path are the log sequencer and the group buffer. The log sequencer assigns LSNs to log entries sequentially. We have implemented a lock-free log sequencer to avoid it becoming a bottleneck. When a thread appends a log to PALF, it loads the value of the LSN tail atomically to a temporary variable, updates the temporary value, and stores it to the LSN tail with an atomic compare-andswap operation. If the compare-and-swap operation fails due to concurrent appending, then the thread reloads the LSN tail and loops around to acquire LSN again [21].
无锁写路径 与提高吞吐量相比,如果出现严重的竞争情况,过高的并发度可能会降低性能。因此,为 PALF 设计了无锁写路径,以避免线程之间的竞争。写路径的主要组成部分是日志序列器和组缓冲区。日志序列器按顺序为日志条目分配 LSN(逻辑序列号)。我们实现了一个无锁的日志序列器,以避免其成为瓶颈。当一个线程将日志添加到 PALF 时,它会原子地加载 LSN 尾部原子变量到一个临时变量,更新该临时值,并使用原子的比较与交换操作将其存储到 LSN 尾部。如果由于并发添加而导致比较与交换操作失败,则该线程会重新加载 LSN 尾部并再次循环以获取 LSN [21]。
After acquiring the LSN, multiple threads fill log entries into the group buffer concurrently. The LSN not only acts as a log entry’s address on disk, but also serves as the offset of the log entry in the group buffer, which means that the reserved buffer for a log entry never overlaps with another log entry. As a result, the group buffer is not a competing resource, and multiple threads can fill log entries to different offsets concurrently without any lock overheads.
在获取到 LSN 后,多个线程会同时将日志条目填入组缓冲区。LSN 不仅在磁盘上充当日志条目的地址,还作为组缓冲区中日志条目的偏移量,这意味着为一个日志条目预留的缓冲区永远不会与另一个日志条目重叠。因此,组缓冲区并非竞争资源,多个线程可以同时将日志条目填入不同的偏移量,而无需任何锁开销。
7 DESIGN CHOICES AND DISCUSSIONS(设计选择与讨论)
Raft vs. PALF. Raft and PALF are essentially implementations of the Paxos protocol[27]. PALF adopted the log replication of Raft for simplicity, here are some differences worth discussing.
Raft 与 PALF。Raft 和 PALF 实际上都是帕克斯协议的实现版本[27]。PALF 为了简便性采用了 Raft 的日志复制方式,以下是其中一些值得探讨的差异之处。
- State Machine Model. PALF adopt the replicated WAL model for serving OceanBase database (§3.1), Raft is built at the setting of RSM model.
- Leader Election. In Raft, leader’s logs must be at least as up-to-date as logs of any replica in a majority. In PALF, election priorities manipulate which replica can be elected as the leader, the config version acts as the chief election priority (§5.3). For correctness, the log reconfirmation is introduced (§3.4) to ensure that the candidate will hold the longest logs in a majority before it takes over as a leader.
- Pending Follower. PALF adds a new stage to the transition from leader to follower for determining the replication results of logs (§3.4) when some failures occur.
- Reconfiguration. A reconfiguration command of Raft is a normal log entry, but PALF decouples it as a meta entry for independent PALF group mirror (§5.3).
- Log Index. Raft adopts a continuous numeric log index for log replication. PALF adopts two log entry identifiers, LSN and CSN. The continuous LSN is used to replicate and store logs, the CSN is used to track the order of operations across multiple PALF groups.
- 状态机模型。PALF 采用复制的 WAL 模型来为 OceanBase 数据库提供服务(第 3.1 节),Raft 是在 RSM 模型的设定下构建的。
- 领导者选举。在 Raft 中,领导者的日志必须至少与大多数副本的日志保持同步。在 PALF 中,选举优先级用于决定哪个副本可以被选为领导者,配置版本充当主要的选举优先级(第 5.3 节)。为了保证正确性,引入了日志重新确认机制(第 3.4 节),以确保候选者在接管为领导者之前会持有大多数中最长的日志。
- 待处理从属节点。PALF 在从领导者到从属节点的转换过程中为确定日志的复制结果添加了一个新阶段(第 3.4 节),当出现某些故障时使用。
- 重新配置。Raft 的重新配置命令是一个正常的日志条目,但 PALF 将其作为独立 PALF 组镜像的元数据条目进行解耦(第 5.3 节)。
- 日志索引。Raft 采用连续的数字日志索引来进行日志复制。PALF 采用两个日志条目标识符,LSN 和 CSN。连续的 LSN 用于复制和存储日志,CSN 用于跨多个 PALF 组跟踪操作的顺序。
PALF Group Mirror vs. Paxos Learners. An intuitive question may be why we choose to construct physical standby databases by streaming between PALF groups, rather than synchronizing logs to physical standby databases as Paxos learners. In practice, two main reasons motivates the design of the PALF group mirror.
PALF 集群镜像与 Paxos 学习者。一个直观的问题可能是,为何我们选择通过在 PALF 集群之间进行数据流传输的方式来构建物理备用数据库,而非像 Paxos 学习者那样将日志同步到物理备用数据库。实际上,PALF 集群镜像的设计有两个主要原因。
The first reason is failover. If the primary database crashed, the standby database should be able to be switched as new primary database and start to serve user requests. However, it is complicated for Paxos learners to be elected as the leader of new primary database because learners are not the part of the Paxos membership. In contrast, PALF group mirror is an independent Paxos group, it can be easily switched to a primary PALF group by changing its access mode. The second reason is maintainability. Most reconfiguration algorithms in consensus protocols are executed by the leader. If the standby databases depend on Paxos learners, reconfiguring a standby database must require it to contact with the primary database, it is unacceptable when the network between them is broken. For PALF group mirror, independent reconfiguration enables administrators to reconfigure the standby database even if the primary database crashes.
第一个原因在于故障切换。如果主数据库崩溃,备用数据库应当能够被切换为新的主数据库并开始为用户请求提供服务。然而,对于帕索斯学习者来说,要被选为新主数据库的领导者是相当复杂的,因为学习者并非帕索斯成员的一部分。相比之下,PALF 组镜像是一个独立的帕索斯组,通过改变其访问模式就可以轻松地切换为一个主 PALF 组。第二个原因是可维护性。共识协议中的大多数重新配置算法都是由领导者执行的。如果备用数据库依赖于帕索斯学习者,重新配置一个备用数据库就必须要求它与主数据库进行联系,而当它们之间的网络中断时,这是不可接受的。对于 PALF 组镜像来说,独立的重新配置使管理员即使在主数据库崩溃的情况下也能重新配置备用数据库。
8 EVALUATION(评估)
In this section, we evaluate PALF performance experimentally. More specifically, we seek to answer the following questions:
- What level of performance could PALF achieve?
- How does the optimization in PALF impact its performance?
- Does log reconfirmation impact failure recovery?
- Is PALF competent as the WAL of OceanBase database?
在本节中,我们将通过实验来评估 PALF 的性能。更具体地说,我们旨在回答以下问题:
- PALF 能够达到何种性能水平?
- PALF 中的优化对其性能有何影响?
- 日志重新确认会影响故障恢复吗?
- PALF 是否能胜任 OceanBase 数据库的 WAL(日志写入器)角色?
8.1 Overall Performance(总体表现)
Testbed. All experiments (except §8.4) were performed on a cluster of three commodity servers. Each server is equipped with a 32-core 2.5GHz Intel Xeon CPU, 256 GB memory, and four SSD disks, all connected via 10 Gigabit Ethernet with 0.2 ���� average latency. Three replicas were placed on different servers.
测试平台。除了第 8.4 节的实验外,所有实验均在由三台商用服务器组成的集群上进行。每台服务器配备有 32 核 2.5GHz 的英特尔至强 CPU、256GB 内存以及四块 SSD 硬盘,所有设备均通过 10G 以太网连接,平均延迟为 0.2 微秒。三个副本分别放置在不同的服务器上。
Baselines. We compared PALF with etcd-raft[15] and braft[2], which are two open-source implementations of Raft[33], upon which some industrial distributed systems[14, 42] have been built. The main differences in system design are multicore scalability and group replication. For instance, in etcd-raft, clients propose logs to raft node through a Go channel, which facilitates its usage but limits throughput under high concurrency. Even though both etcd-raft and braft implement some batching optimizations, such as batching disk I/O requests and reducing the number of network packets, they still process log entries one by one in the consensus protocol, which limits throughput.
基准测试。我们将 PALF 与 etcd-raft[15] 和 braft[2] 进行了比较,这二者是 Raft[33] 的两种开源实现,一些工业分布式系统[14, 42]正是基于它们构建的。系统设计的主要差异在于多核可扩展性和群组复制。例如,在 etcd-raft 中,客户端通过 Go 通道向 raft 节点提交日志,这便于其使用,但在高并发情况下会限制吞吐量。尽管 etcd-raft 和 braft 都实现了某些批处理优化,例如批量处理磁盘 I/O 请求和减少网络数据包数量,但它们在共识协议中仍然一个一个地处理日志条目,这限制了吞吐量。
Client Model. We built closed-loop clients for PALF, etcd-raft, and braft. Each client does not append new logs to the leader until its previous appended log has been committed. To emulate common use cases of the write-ahead logging system (as an inner component of the distributed database), clients are co-located with the leader and append logs to the leader directly.
客户端模型。我们为 PALF、etcd-raft 和 braft 构建了闭环客户端。每个客户端在其先前添加的日志已提交之前,不会向领导者添加新的日志。为了模拟前向日志记录系统的常见使用场景(作为分布式数据库的内部组件),客户端与领导者位于同一位置,并直接向领导者添加日志。
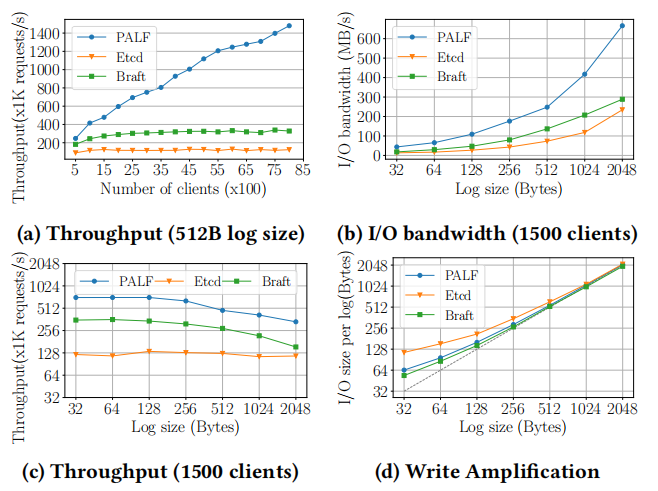
Throughput. PALF scales throughput greatly as the number of clients increases. As illustrated in Fig. 9a, PALF handles 478K append requests per second with 1500 clients and 1480K requests per second with 8000 clients. These throughput numbers are much higher than the baselines. The speedup ratio of PALF is 5.98 when the number of clients increases from 500 to 8000, whereas the speedup ratios of etcd-raft and braft are 1.386 and 1.8 respectively. This means that PALF can make full use of modern multicore hardware. There are several reasons for this. First, PALF’s lock-free write path minimizes the overhead caused by lock contentions. Second, the group buffer could be filled concurrently, and a fleet of cached logs could be replicated within one consensus instance.
吞吐量。随着客户端数量的增加,PALF 的吞吐量会大幅提高。如图 9a 所示,当有 1500 个客户端时,PALF 每秒可处理 478,000 次追加请求;当有 8000 个客户端时,每秒可处理 1480,000 次请求。这些吞吐量数据远高于基准值。当客户端数量从 500 增加到 8000 时,PALF 的速度提升比为 5.98,而 etcd-raft 和 braft 的速度提升比分别为 1.386 和 1.8。这意味着 PALF 能够充分利用现代多核硬件。造成这种情况的原因有以下几点。首先,PALF 的无锁写路径最大限度地减少了因锁竞争而产生的开销。其次,组缓冲区可以同时被填充,并且一组缓存日志可以在一个共识实例内进行复制。
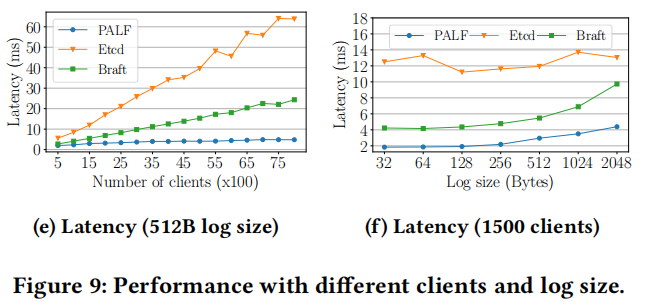
We further evaluated the impact of log size on I/O bandwidth and throughput. As shown in Fig. 9b, etcd-raft achieves comparable I/O bandwidth to braft and PALF, especially for small log sizes. This seems to be inconsistent with the result depicted in Fig. 9a. To discover the reason, we further plotted the relationship between throughput and log size in Fig. 9c. The result shows that the valid throughput of braft is much higher than that of etcd-raft, but that their I/O bandwidths are of the same order of magnitude. This implies that the real I/O size for each log may be amplified by etcdraft. Write amplification depicted in Fig. 9d validates the previous reasoning. It was also found that the real I/O size of each log in PALF is larger than that of each log in braft when log size is smaller than 128 bytes. The reason for this is group replication. Besides the log header (Fig. 5), an additional group log header will be attached to each group log, which amplifies the real I/O size of logs.
我们进一步评估了日志大小对 I/O 带宽和吞吐量的影响。如图 9b 所示,etcd-raft 的 I/O 带宽与 braft 和 PALF 相当,尤其是在日志大小较小时。这似乎与图 9a 中所示的结果不一致。为了找出原因,我们进一步在图 9c 中绘制了吞吐量与日志大小的关系。结果表明,braft 的有效吞吐量远高于 etcd-raft,但它们的 I/O 带宽处于相同数量级。这意味着每个日志的实际 I/O 大小可能因 etcdraft 而被放大。图 9d 中所示的写放大现象验证了之前的推理。还发现,当日志大小小于 128 字节时,PALF 中每个日志的实际 I/O 大小大于 braft 中每个日志的大小。其原因在于组复制。除了日志头(图 5)外,每个组日志还会附加一个额外的组日志头,从而放大了日志的实际 I/O 大小。
Latency. As illustrated in Fig. 9e, the latency of PALF is about 2 ms when the number of clients is less than 1500. Although PALF has been evaluated to be friendly to high concurrency, latency still increases slightly with the number of clients, up to 4.8 ms under 8000 clients. In the write path of PALF, LSN and CSN allocation is a procedure that must execute sequentially. If a thread fails to allocate LSN due to concurrent requests, the retry operation will incur additional latency. We performed an evaluation to determine whether the log sequencer is the bottleneck under high concurrency. Our evaluations showed that the log sequencer can handle 5.88 million requests per second under 1000 threads. Therefore, the LSN allocator is far from being a bottleneck. The replication latency consists of memory copy, disk flushing, and network transmission; these overheads are all correlated to the log size. Therefore, it is reasonable that larger logs incur higher latency (Fig. 9f).
延迟。如图 9e 所示,当客户端数量少于 1500 时,PALF 的延迟约为 2 毫秒。尽管 PALF 已经被评估为对高并发性友好,但随着客户端数量的增加,延迟仍会略有上升,在 8000 个客户端的情况下,延迟可达 4.8 毫秒。在 PALF 的写入路径中,LSN(逻辑序列号)和 CSN(快照序列号)的分配是一个必须按顺序执行的过程。如果由于并发请求而导致线程无法分配 LSN,重试操作将产生额外的延迟。我们进行了评估,以确定在高并发情况下日志序列器是否是瓶颈。我们的评估表明,在 1000 个线程的情况下,日志序列器每秒可以处理 588 万次请求。因此,LSN 分配器远非瓶颈。复制延迟包括内存复制、磁盘刷新和网络传输;这些开销都与日志大小相关。因此,较大的日志确实会导致更高的延迟(图 9f)。
8.2 Adaptive Group Replication(自适应组复制)
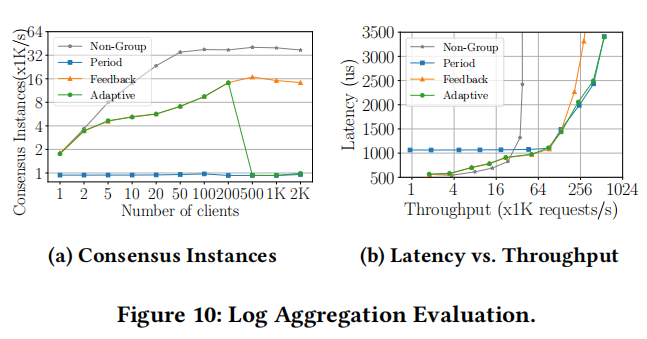
We evaluated the effect of adaptive group replication under different concurrency levels. The threshold of the group factor was set to 10 because 10 workers were handling clients’ requests. In Figure 10a, fewer consensus instances mean less overhead. PALF proposes more consensus instances when group replication is disabled; it must consume more computing resources than group replication. As the number of clients increases, adaptive group replication sharply reduces the number of consensus instances. The performance improvement is visually depicted in Fig. 10b. When throughput is low, the adaptive group replication tracks the low latency property of the feedback group replication. As the degree of concurrency increases, PALF switches to periodic group replication and achieves significant throughput. In conclusion, the adaptive group replication combines the advantages of two aggregation strategies, which allows PALF to perform well under different concurrency levels.
我们评估了在不同并发级别下自适应组复制的效果。由于有 10 名工作人员处理客户端请求,所以将组因子的阈值设为 10。在图 10a 中,共识实例数量越少意味着开销越小。当禁用组复制时,PALF 提出了更多的共识实例;它必须比组复制消耗更多的计算资源。随着客户端数量的增加,自适应组复制会大幅减少共识实例的数量。性能提升情况如图 10b 所示。当吞吐量较低时,自适应组复制会跟踪反馈组复制的低延迟特性。随着并发程度的增加,PALF 切换到周期性组复制,并实现了显著的吞吐量。总之,自适应组复制结合了两种聚合策略的优点,使 PALF 在不同的并发级别下都能表现良好。
8.3 Failure Recovery(故障恢复)
and recovery time when the leader crashes, which is critical for database availability. Figure 11a shows that PALF recovers from leader failure within a short time, and the new leader achieves equivalent throughput to the previous leader. PALF recovery consists of two stages: leader election and log reconfirmation. The duration of leader election is mainly subject to lease (4 s as default); log reconfirmation takes up extra time compared to Raft. Figure 11b illustrates the cumulative distribution function (CDF) of the reconfirmation time. The median and 90-th percentile were 32.2 ms and 32.5 ms respectively. Even the reconfirmation time is related to the gap of log size between the new leader and the replicas that own the most logs, election restriction (in §5.3) guarantees that the logs of the new leader will not fall far behind. Moreover, the efficient write path of PALF further shortens the recovery time. These optimizations make the overhead of log reconfirmation negligible.
并且在领导者崩溃时的恢复时间,这对于数据库的可用性至关重要。图 11a 显示,PALF 在短时间内就能从领导者故障中恢复过来,并且新的领导者能达到与之前领导者相同的吞吐量。PALF 的恢复过程分为两个阶段:领导者选举和日志重新确认。领导者选举的持续时间主要取决于租约(默认为 4 秒);而日志重新确认所花费的时间则比 Raft 更多。图 11b 展示了重新确认时间的累积分布函数(CDF)。中位数和 90 百分位数分别为 32.2 毫秒和 32.5 毫秒。即使重新确认时间也与新领导者与拥有最多日志的副本之间的日志大小差距以及选举限制(在第 5.3 节中)有关,选举限制确保新领导者的日志不会落后太多。此外,PALF 的高效写入路径进一步缩短了恢复时间。这些优化使得日志重新确认的开销可以忽略不计。
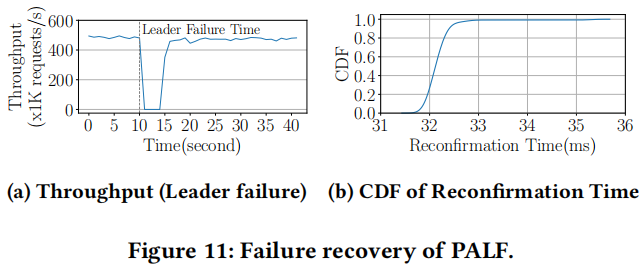
8.4 Evaluating PALF within OceanBase(在 OceanBase 中评估 PALF)
To validate how log replication affects database performance, we measured OceanBase 4.0 under both benchmarking tools and production environments. To exert enough pressure on PALF, we chose two Sysbench [25] cases (insert and update) and TPC-C[10] (200 warehouses) as workloads, evaluated PALF with key-value mode of OceanBase under YCSB batch insert workloads, and measured PALF performance in a production cluster. The benchmarking experiment was performed on a cluster of three commodity servers, which are equipped with a 96-core 2.5GHz Intel Xeon CPU and the same hardware as in the earlier experiments; The production cluster consists of 46 Aliyun ECS r5.16xlarge instances.
为了验证日志复制对数据库性能的影响,我们分别在基准测试工具和生产环境中对 OceanBase 4.0 进行了测试。为了给 PALF 带来足够的压力,我们选择了两个 Sysbench [25] 测试案例(插入和更新)以及 TPC-C [10](200 个仓库)作为工作负载,并在 YCSB 批量插入工作负载下使用 OceanBase 的键值模式对 PALF 进行评估,同时在生产集群中测量了 PALF 的性能。基准测试实验是在由三台商用服务器组成的集群上进行的,这些服务器配备了 96 核 2.5GHz 的英特尔至强 CPU,硬件与之前的实验相同;生产集群由 46 个阿里云 ECS r5.16xlarge 实例组成。
The results of transactional performance are depicted in Figure 12a and Figure 12b. Compared to stand-alone performance, log replication slightly reduces the performance of three-replica OceanBase by 8.8% on average (For fairness, only one replica of the database can process transactions). This result proves the efficiency of PALF. Note that the performance of OceanBase scales with the number of clients under Sysbench, but experiences a little decrease under TPC-C. The reason for this is the proportion of write transactions. The logging system greatly impacts the performance of write transactions, but have minimal impact on read transactions. Therefore, the performance of write-intensive workloads in Sysbench scales well due to the scalability of PALF. In comparison, the performance on hybrid workloads in TPC-C is limited to the database itself. This result shows that log replication is not a bottleneck for OceanBase.
交易性能的结果如图 12a 和图 12b 所示。与单独运行的性能相比,日志复制平均使三副本的 OceanBase 性能降低了 8.8%(为保证公平性,数据库仅能有一个副本处理事务)。这一结果证明了 PALF 的有效性。请注意,在 Sysbench 测试中,OceanBase 的性能会随着客户端数量的增加而提升,但在 TPC-C 测试中则略有下降。其原因在于写事务的比例。日志系统对写事务的性能影响很大,但对读事务的影响很小。因此,在 Sysbench 的写密集型工作负载中,由于 PALF 的可扩展性,其性能表现良好。相比之下,在 TPC-C 的混合工作负载中,其性能受限于数据库本身。这一结果表明,日志复制并非 OceanBase 的性能瓶颈。
The profiling of PALF within OceanBase during the benchmarking experiments (three-replica) and the production workloads are exhibited in Table 1, Figure 12c, and Figure 12d. The results are much lower than PALF’s peak performance described in §8.1, which can achieve 1.4 million append operations per second with 512-byte payloads. Therefore, the performance of PALF is more than sufficient for OceanBase to serve intensive writes.
在基准测试实验(三副本)以及生产工作负载中,OceanBase 中 PALF 的性能分析结果如表 1、图 12c 和图 12d 所示。这些结果远低于第 8.1 节中所描述的 PALF 的峰值性能,后者在使用 512 字节数据包的情况下能够实现每秒 140 万次追加操作。因此,PALF 的性能足以满足 OceanBase 承载高强度写入的需求。
9 RELATED WORK(相关工作)
In this section, we discuss other contributions and how they relate to the features of PALF.
在本节中,我们将探讨其他相关成果,并阐述它们与 PALF 特性之间的关系。
WAL in Distributed Databases. Many distributed databases have been built on top of replicated logging for fault tolerance and availability. The Raft protocol [33, 34] is widely used to synchronize logs among replicas, such as CockRoachDB [42] and YugabyteDB [48]. Spanner [9] implements a replicated state machine with Paxos on top of each tablet. Their transaction engines interact with the logging system through the replicated state machine model [39]. The choice made by PALF is to provide file-like interfaces, which makes the integration between consensus protocol and the typical WAL model possible. Aurora[44] is a shared-storage database, the database engine takes charge of log replication and offloads the log processing to log storage, by contrast, PALF fits in a shared-nothing architecture, the database appends logs to PALF by file-like APIs and is unaware of consensus protocol.
分布式数据库中的 WAL。许多分布式数据库都是基于复制日志构建的,以实现容错性和可用性。Raft 协议[33, 34]被广泛用于在副本之间同步日志,例如 CockRoachDB [42] 和 YugabyteDB [48]。Spanner [9] 在每个表片之上使用 Paxos 实现了一个具有复制状态机的分布式状态机。它们的事务引擎通过复制状态机模型与日志系统进行交互[39]。PALF 选择提供类似文件的接口,这使得共识协议与典型的 WAL 模型的集成成为可能。Aurora [44] 是一个共享存储数据库,数据库引擎负责日志复制,并将日志处理任务卸载到日志存储中,相比之下,PALF 适合于无共享架构,数据库应用程序通过类似文件的 API 将日志添加到 PALF 中,而不知道共识协议的存在。
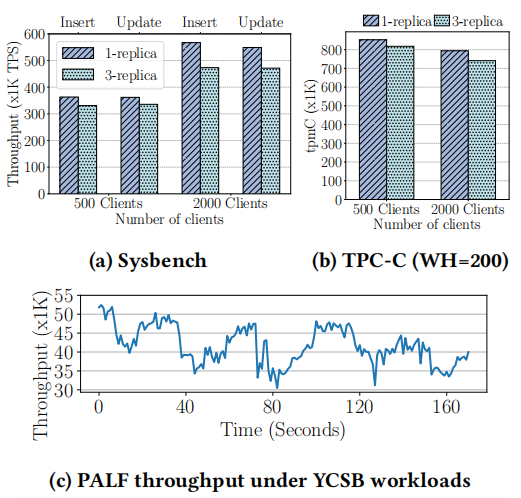
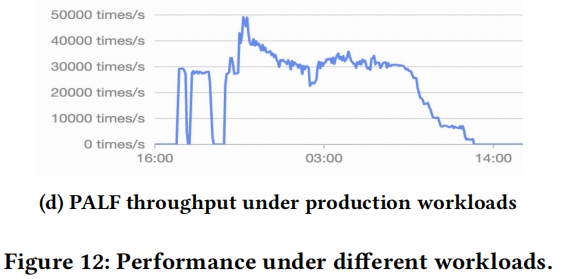
These distributed databases adopt the approach of bundling log replication with data partition (tablet in Spanner, range in CockRoachDB, etc.), which achieves high throughput by parallelizing multiple partitions, but incurs more distributed transactions. A single replication group of PALF provides excellent performance, it can replicate logs of multiple data partitions concurrently, this way indirectly reduces the number of distributed transactions.
这些分布式数据库采用了将日志复制与数据分区相结合的方法(在 Spanner 中为表分区,在 CockRoachDB 中为范围分区等),通过将多个分区并行化来实现高吞吐量,但会增加分布式事务的数量。PALF 的单个复制组具有出色的性能,它能够同时复制多个数据分区的日志,从而间接减少了分布式事务的数量。
Socrates [1] uses an unbundled log service XLOG built on the Azure storage service to support an upper database tier. FoundationDB [50] adopts another unbundled architecture in which log servers are decoupled from transaction processing and logs are replicated across log servers in the charge of proxies in the transaction system. PALF provides file-like interfaces for bundled architectures.
苏格拉底 [1] 利用基于 Azure 存储服务构建的非捆绑式日志服务 XLOG 来支持上层数据库层。FoundationDB [50] 采用了另一种非捆绑式架构,在这种架构中,日志服务器与事务处理相分离,日志在事务系统的代理负责的各个日志服务器之间进行复制。PALF 为捆绑式架构提供了类似文件的接口。
In bundled architectures, even if additional performance gains could be attained by coupling WAL and the database tightly (e.g. making WAL transaction-aware to commit buffered logs[29], distributed transaction optimizations [17, 19]), PALF still abstracts database-specific functions as filesystem-like APIs to keep a clear boundary between the log and the database, this will bring maintainability and stability benefits to a practical database system.
在集成式架构中,即便通过将写日志文件(WAL)与数据库紧密耦合(例如使 WAL 能够识别事务并提交缓冲的日志[29]、分布式事务优化[17, 19])能够获得更多的性能提升,但 PALF 仍然将数据库特有的功能抽象为类似于文件系统的 API,以保持日志与数据库之间的清晰界限,这将为实际的数据库系统带来可维护性和稳定性方面的优势。
xCluster[49] of YugabyteDB supports asynchronous replication between databases by transmitting logical logs with the change data capture tool, but imposing many constraints; for example, it does not support synchronizing DDL statements. CockroachDB[42] only supports replica-level asynchronous replication by non-voting replicas. These schemes are not suitable for physical standby databases, which provide an identical copy of the primary database and should be independently available. PALF offers the PALF group mirror to construct the standby database naturally.
YugabyteDB 的 xCluster[49] 支持在不同数据库之间进行异步复制,其方式是通过使用变更数据捕获工具来传输逻辑日志,并且会施加诸多限制;例如,它不支持同步 DDL 语句。CockroachDB[42] 仅通过非投票副本来支持副本级别的异步复制。这些方案并不适用于物理备用数据库,因为物理备用数据库应提供与主数据库完全相同的副本,并且应独立可用。PALF 提供了 PALF 组镜像来自然构建备用数据库。
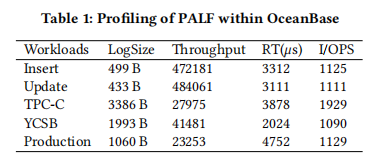
Replicated Logging Systems. Replicated logging systems are widely used to persist and order updates in distributed systems. Many replicated logging protocols sequence records by a distinguished leader [9, 18, 22, 30, 34]. A shared log abstraction has been proposed to funnel all updates through a global ordering layer, such as CORFU [4] and Scalog[13]. For distributed databases, the order of logs is essentially determined by the transaction engine rather than the logging system. Some logging systems [18, 42] pack transaction identifiers into log records, which may incur inconsistency between the transaction order and the logging order. PALF provides a change sequence number primitive that tracks the transaction order with the logging order.
复制式日志系统。复制式日志系统在分布式系统中被广泛用于保存和排序更新信息。许多复制式日志协议通过一个指定的领导者来对记录进行排序[9, 18, 22, 30, 34]。已提出了一种共享日志抽象概念,通过一个全局排序层(如 CORFU [4] 和 Scalog [13])来汇集所有更新。对于分布式数据库而言,日志的顺序本质上是由事务引擎而非日志系统决定的。一些日志系统[18, 42]将事务标识符打包进日志记录中,这可能会导致事务顺序和日志顺序之间的不一致。PALF 提供了一个变更序列号原语,用于跟踪事务顺序和日志顺序。
As for independent reconfiguration, another promising solution is separating configuration management from log replication, as in Vertical Paxos[28] and Delos[3]. Most of these studies give the responsibility for reconfiguring clusters to another service; the approach may introduce additional availability risk to systems [16]. These systems are often internal services of big companies rather than a common software product like the OceanBase database. The PALF approach achieves both independence and generality of reconfiguration. MongoRaftReconfig[40] also stores reconfiguration logs separately like PALF, but its motivation is to recover a consensus group from majority failures. In that scenario, safety properties of Raft reconfiguration may not be ensured; MongoRaftReconfig proposed an extended reconfiguration protocol and proved its safety.
至于独立的重新配置,另一个颇具前景的解决方案是将配置管理与日志复制相分离,例如在 Vertical Paxos[28] 和 Delos[3] 中所采用的方式。这些研究将重新配置集群的责任分配给了其他服务;这种方法可能会给系统带来额外的可用性风险[16]。这些系统通常是由大型公司内部提供的服务,而非像 OceanBase 数据库这样的通用软件产品。PALF 方法实现了重新配置的独立性和通用性。MongoRaftReconfig[40] 也像 PALF 一样将重新配置日志单独存储,但其动机是通过多数故障恢复共识组。在这种情况下,Raft 重新配置的安全属性可能无法得到保证;MongoRaftReconfig 提出了一个扩展的重新配置协议,并证明了其安全性。
10 CONCLUSION(结论)
This paper has presented PALF, which acts as the replicated writeahead logging system of OceanBase and is expected to serve as a building block for many other distributed systems. The key idea is to abstract database-specific requirements to PALF primitives. Specifically, PALF provides typical file system interfaces and explicit replication results at a consensus level, which facilitate the integration between the transactional system and WAL. The CSN primitive helps to track the order of transactions by the order of logs. Data change synchronization has been abstracted as PALF group mirrors; downstream applications would benefit from this. Under typical OLTP workloads, PALF serves the OceanBase database in a comfortable manner and offers space for future advances.
本文介绍了 PALF,它是 OceanBase 的复制式预写日志系统,有望成为许多其他分布式系统的组成部分。其核心思想是将数据库特定的需求抽象为 PALF 原语。具体而言,PALF 提供了典型的文件系统接口和共识级别的明确复制结果,这有助于将事务系统与 WAL 进行整合。CSN 原语通过日志的顺序来跟踪事务的顺序。数据变更同步已被抽象为 PALF 组合镜像;下游应用程序将从中受益。在典型的 OLTP 工作负载下,PALF 能以舒适的方式为 OceanBase 数据库服务,并为未来的进步提供空间。


















 400
400

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











