




 本文通过构建时间序列模型,使用历史销售数据预测未来销量,深入探讨特征工程的重要性,包括销量、价格趋势分析及商品销售间隔等特征的构建。
本文通过构建时间序列模型,使用历史销售数据预测未来销量,深入探讨特征工程的重要性,包括销量、价格趋势分析及商品销售间隔等特征的构建。
之前在广州时便看到kaggle上有一个根据过去的销售数据预测下个月的销量的竞赛,数据量也达到了293万条,本来想那个时候就摸索着尝试做一下,无奈上班时事情太多导致没法专心搞,现在离职不知不觉也有3个月了(忧桑,找了一个月了,发现居然没有多少合适的= =),趁着空档期决定撸一下学习一下时间序列模型,权当记录一下
项目简介
是一个Coursera课程里的作业,包含6个数据文件
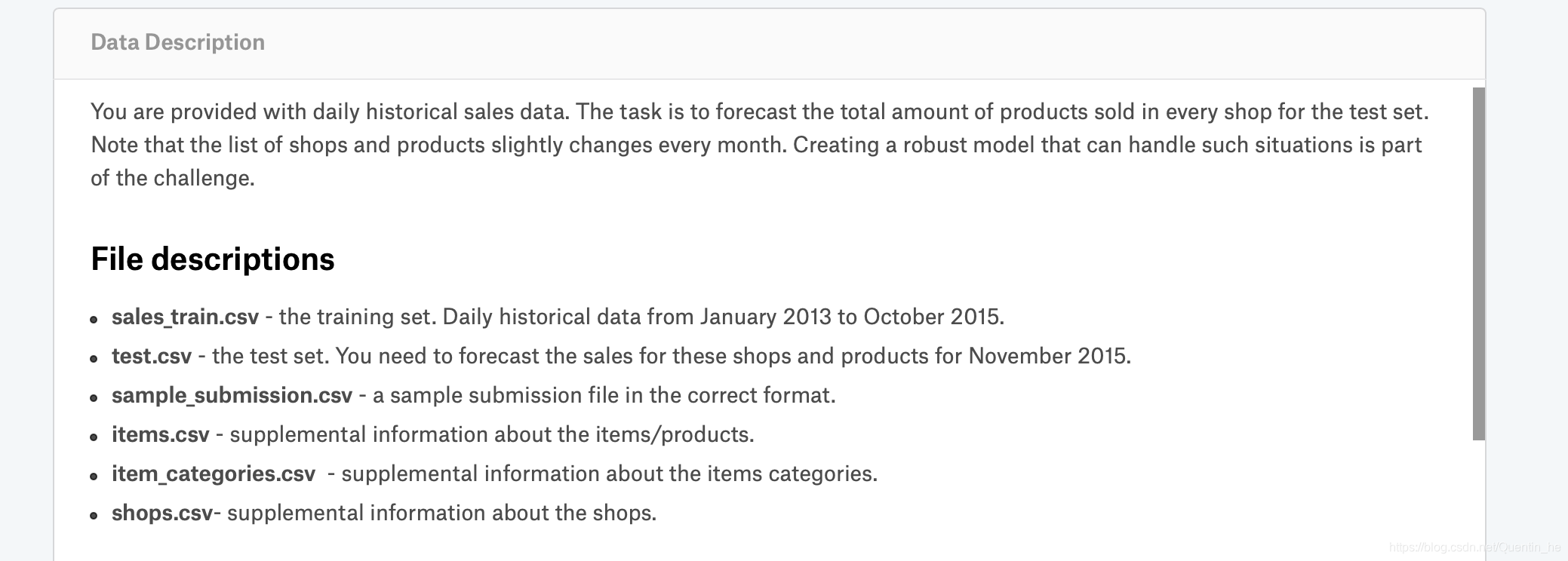
数据描述,另外为了简化将项目中的销量clip在[0,20]

数据探索
打开所有附件数据看看情况
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import *
from matplotlib.font_manager import _rebuild
mpl.rcParams['font.family'] = ['Arial Unicode MS']
mpl.rcParams['axes.unicode_minus'] = False
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 200)
sale_df = pd.read_csv(
'/Users/shaling/Downloads/competitive-data-science-predict-future-sales/sales_train.csv')
shop = pd.read_csv(
'/Users/shaling/Downloads/competitive-data-science-predict-future-sales/shops.csv')
item = pd.read_csv(
'/Users/shaling/Downloads/competitive-data-science-predict-future-sales/items.csv')
cats = pd.read_csv(
'/Users/shaling/Downloads/competitive-data-science-predict-future-sales/item_categories.csv')
test = pd.read_csv(
'/Users/shaling/Downloads/competitive-data-science-predict-future-sales/test.csv').set_index('ID')
print(sale_df.info())
print(sale_df.describe())
print(sale_df.head())
记录有293万条,发现价格和销量还有负数的,销量是负数还比较好理解,就是有退货的,但是价格负数应该就是记录错误了
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2935849 entries, 0 to 2935848
Data columns (total 6 columns):
date object
date_block_num int64
shop_id int64
item_id int64
item_price float64
item_cnt_day float64
dtypes: float64(2), int64(3), object(1)
memory usage: 134.4+ MB
None
date_block_num shop_id item_id item_price item_cnt_day
count 2.935849e+06 2.935849e+06 2.935849e+06 2.935849e+06 2.935849e+06
mean 1.456991e+01 3.300173e+01 1.019723e+04 8.908532e+02 1.242641e+00
std 9.422988e+00 1.622697e+01 6.324297e+03 1.729800e+03 2.618834e+00
min 0.000000e+00 0.000000e+00 0.000000e+00 -1.000000e+00 -2.200000e+01
25% 7.000000e+00 2.200000e+01 4.476000e+03 2.490000e+02 1.000000e+00
50% 1.400000e+01 3.100000e+01 9.343000e+03 3.990000e+02 1.000000e+00
75% 2.300000e+01 4.700000e+01 1.568400e+04 9.990000e+02 1.000000e+00
max 3.300000e+01 5.900000e+01 2.216900e+04 3.079800e+05 2.169000e+03
date date_block_num shop_id item_id item_price item_cnt_day
0 02.01.2013 0 59 22154 999.00 1.0
1 03.01.2013 0 25 2552 899.00 1.0
2 05.01.2013 0 25 2552 899.00 -1.0
3 06.01.2013 0 25 2554 1709.05 1.0
4 15.01.2013 0 25 2555 1099.00 1.0
(2935849, 6)
[Finished in 6.2s]
看一下价格为负数的数据并修正,用同店的同商品的中位数填充
# 修正价格为负数的数据
print(sale_df[sale_df.item_price < 0])
# date date_block_num shop_id item_id item_price item_cnt_day
484683 15.05.2013 4 32 2973 -1.0 1.0
sale_df.loc[(sale_df.date_block_num == 4) & (sale_df.shop_id == 32) & (sale_df.item_id == 2973), 'item_price'] = sale_df.item_price[(
sale_df.date_block_num == 4) & (sale_df.shop_id == 32) & (sale_df.item_id == 2973) & (sale_df.item_price > 0)].median()
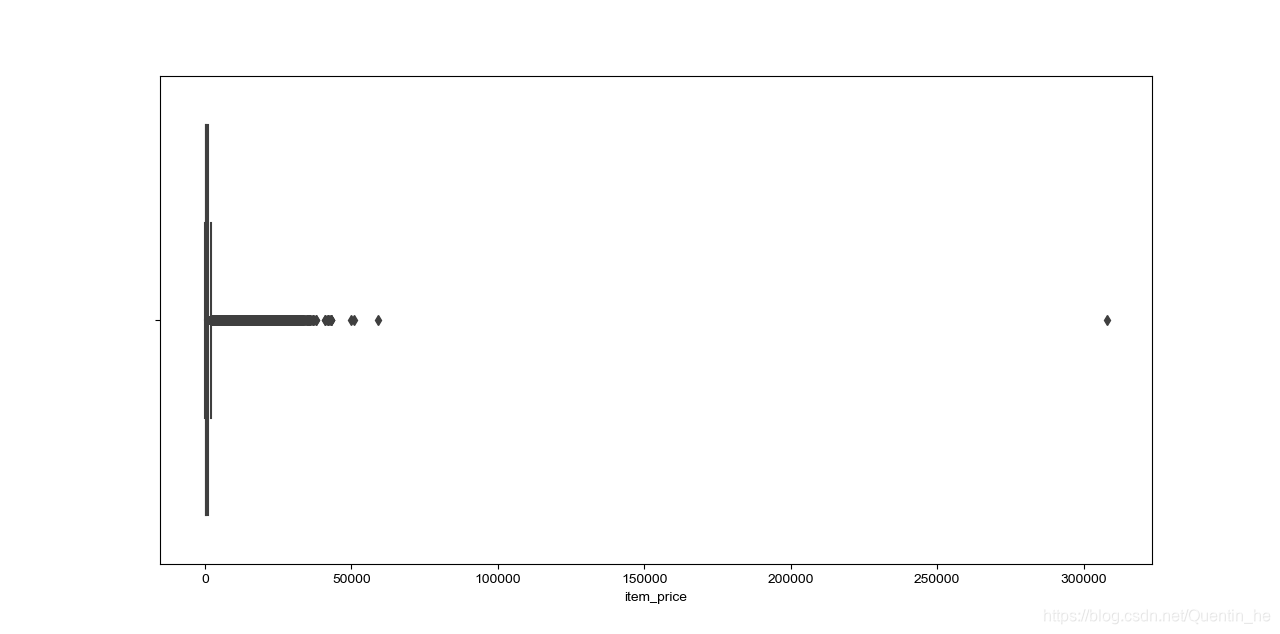
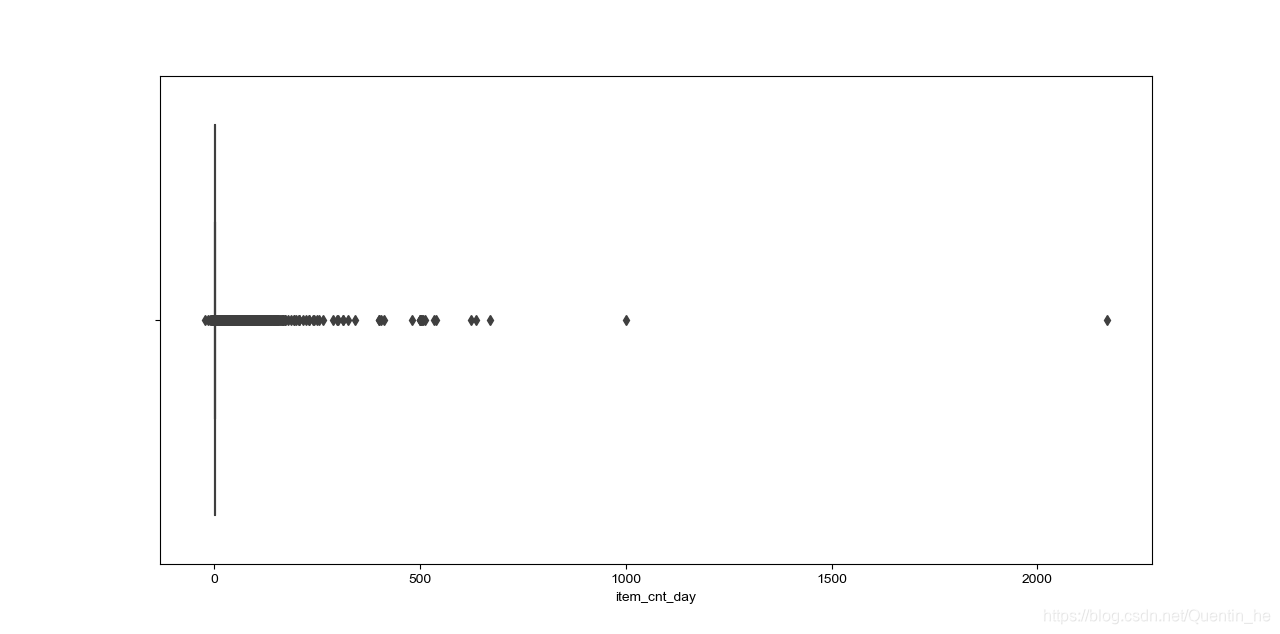
查看价格和销量数据,并剔除异常值
# 查看每日销量分布
plt.figure(figsize=(20, 8))
sns.boxplot(x=sale_df.item_cnt_day)
sale_df = sale_df[sale_df.item_cnt_day < 1000] # 剔除大于1000的异常值
# 查看价格分布
plt.figure(figsize=(20, 8))
sns.boxplot(x=sale_df.item_price)
sale_df = sale_df[sale_df.item_price < 100000] # 剔除大于100000的异常值
plt.show()
shops包含商品名称,观察发现商店名称的前缀代表着城市,可以分离出来作为一个特征并需要编码化(按常理离散无序的类型应该用one-hot编码,但是这里类别太多且数据量巨大,one hot编码会消耗过多内存,且主要原因是对于树模型,对分类变量进行标签化也能很好的处理,所以这里选用标签化编码),并且有几个是一模一样,需要合并(一直print是因为在Sublime里编写的==,或许应该考虑jupyter notebook)
print(shop) # [0,57],[1,58],[10,11]店名重复
sale_df.loc[sale_df.shop_id == 0, 'shop_id'] = 57
sale_df.loc[sale_df.shop_id == 1, 'shop_id'] = 58
sale_df.loc[sale_df.shop_id == 10, 'shop_id'] = 11
test.loc[test.shop_id == 0, 'shop_id'] = 57
test.loc[test.shop_id == 1, 'shop_id'] = 58
test.loc[test.shop_id == 10, 'shop_id'] = 11
shop['city'] = shop.shop_name.apply(lambda x: x.split(' ')[0].replace(' ', ''))
print(shop)
shop.loc[shop.city == '!Якутск', 'city'] = 'Якутск'
from sklearn.preprocessing import LabelEncoder
shop['city_code'] = LabelEncoder().fit_transform(shop.city)
shop = shop[['shop_id', 'city_code']]
print(shop)
然后是商品类别数据,观察数据(只能观察。。。)发现商品类别其实是由一个大类别和一个小类别构成,这里可以把两个类别分离出来分别作为两个新的特征,不过要注意的是有的类型名称就是一个,没有‘-’分开,所以在第一次做的时候不知道死活报错索引超出了范围
# categray文件处理
print(cats)
cats['type'] = cats.item_category_name.apply(
lambda x: x.split('-')[0].replace(' ', ''))
cats['type_code'] = LabelEncoder().fit_transform(cats.type)
def subtype(df):
ct = df.item_category_name.split('-')
if len(ct) > 1:
return ct[1]
else:
return ct[0]
cats['subtype'] = cats.apply(lambda x: subtype(x), axis=1)
cats['subtype_code'] = LabelEncoder().fit_transform(cats['subtype'])
cats = cats[['item_category_id', 'type_code', 'subtype_code']]
print(cats.head())
比较测试集中的商品是否都包含在训练集中,结果表明有363个商品完全是新的,商店倒是没有新的
# 看看预测集中的商品是否都存在于训练集中
print(len(list(set(test.item_id))) -
len(list(set(test.item_id).intersection(set(sale_df.item_id))))) # 有363个新商品
print(len(list(set(test.shop_id))) -
len(list(set(test.shop_id).intersection(set(sale_df.shop_id))))) # 没有新店铺
print(len(test), len(list(set(test.item_id)))) # 214200对数据需要预测,5100个商品
print(len(list(set(sale_df.item_id))))
# 增加营收列
sale_df['revenue'] = sale_df.item_cnt_day * sale_df.item_price
构造shop和item互不相同的数据集
#因为测试集中包含新商品,且训练集中的商品与商店组合都是过去的,会存在新的组合,将shop和item进行两两组合扩充,
from itertools import product
matrix = []
cols = ['date_block_num','shop_id','item_id']
for i in range(34):
sales = sale_df[sale_df.date_block_num==i]
matrix.append(np.array(list(product([i], sales.shop_id.unique(), sales.item_id.unique()))))
matrix = pd.DataFrame(np.vstack(matrix), columns=cols)
matrix.sort_values(cols,inplace=True)
group = sale_df.groupby(['date_block_num','shop_id','item_id']).agg({'item_cnt_day': ['sum']})
group.columns = ['item_cnt_month']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=cols, how='left')
matrix['item_cnt_month'] = (matrix['item_cnt_month'] .fillna(0) .clip(0,20))
print(matrix.shape)
将测试集中的月份数字设为34并加入到数据集中,再将shop和item,item_categories加入到数据集
# 将要预测的201511的date_block_num设为34并加入到matrix
test['date_block_num'] = 34
matrix = pd.concat([matrix, test], keys=['date_block_num',
'shop_id', 'item_id'], axis=0, ignore_index=True, sort=False)
matrix.fillna(0, inplace=True)
# 将shop,item,cats表加入matrix
matrix = pd.merge(matrix, shop, how='left', on=['shop_id'])
matrix = pd.merge(matrix, item, how='left', on=['item_id'])
matrix = pd.merge(matrix, cats, how='left', on=['item_category_id'])
matrix.drop(['item_name'], inplace=True, axis=1)
print(matrix.head())
特征工程
首先是构造销量和价格的滞后特征,其中重要的特征采取1、2、3、6、12个月的滞后特征,感觉不重要的特征采取1个月特征
#为每个样本增加同一商品在上个月、2个月前、3个月前、半年前、一年前的月销量字段,滞后特征
def lag_feature(df, lags, col):
tmp = df[['date_block_num', 'shop_id', 'item_id', col]]
for i in lags:
shifted = tmp.copy()
shifted.columns = ['date_block_num', 'shop_id',
'item_id', col + '_lag_' + str(i)]
shifted['date_block_num'] += i
df = pd.merge(df, shifted, on=[
'date_block_num', 'shop_id', 'item_id'], how='left')
return df
matrix = lag_feature(matrix, [1, 2, 3, 6, 12], 'item_cnt_month')
# 构造一个月后销量的平均值特征
group = matrix.groupby(['date_block_num']).agg({'item_cnt_month': ['mean']})
group.columns = ['date_avg_item']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, how='left', on=['date_block_num'])
matrix = lag_feature(matrix, [1], 'date_avg_item')
matrix.drop(['date_avg_item'], axis=1, inplace=True)
# 构成不同月份品不同商品在1236,12月后的特征
g1 = matrix.groupby(['date_block_num', 'item_id']).agg(
{'item_cnt_month': ['mean']})
g1.columns = ['date_item_avg']
matrix = pd.merge(matrix, g1.reset_index(), how='left',
on=['date_block_num', 'item_id'])
matrix = lag_feature(matrix, [1, 2, 3, 6, 12], 'date_item_avg')
matrix.drop(['date_item_avg'], axis=1, inplace=True)
# 构成不同月份不同商店在1236,12月的特征
g2 = matrix.groupby(['date_block_num', 'shop_id']).agg(
{'item_cnt_month': ['mean']})
g2.columns = ['date_shop_avg']
matrix = pd.merge(matrix, g2.reset_index(), how='left',
on=['date_block_num', 'shop_id'])
matrix = lag_feature(matrix, [1, 2, 3, 6, 12], 'date_shop_avg')
matrix.drop(['date_shop_avg'], axis=1, inplace=True)
# 构造不同的月份和item_category_id在过了1月后item_cnt_month的平均值的特征值
g3 = matrix.groupby(['item_category_id', 'date_block_num']
).agg({'item_cnt_month': ['mean']})
g3.columns = ['cat_date_avg']
matrix = pd.merge(matrix, g3.reset_index(), how='left', on=[
'item_category_id', 'date_block_num'])
matrix = lag_feature(matrix, [1], 'cat_date_avg')
matrix.drop(['cat_date_avg'], axis=1, inplace=True)
# 构造不同不同月份,不同商店,不同item_category_id的1个月后特征值
g4 = matrix.groupby(['item_category_id', 'date_block_num', 'shop_id']).agg(
{'item_cnt_month': ['mean']})
g4.columns = ['date_shop_cats_avg']
matrix = pd.merge(matrix, g4.reset_index(), how='left', on=[
'item_category_id', 'date_block_num', 'shop_id'])
matrix = lag_feature(matrix, [1], 'date_shop_cats_avg')
matrix.drop(['date_shop_cats_avg'], axis=1, inplace=True)
# 构造不同月份,不同type1个月后的平均值特征
g5 = matrix.groupby(['date_block_num', 'type_code']).agg(
{'item_cnt_month': ['mean']})
g5.columns = ['date_type_avg']
matrix = pd.merge(matrix, g5.reset_index(), how='left', on=[
'date_block_num', 'type_code'])
matrix = lag_feature(matrix, [1], 'date_type_avg')
matrix.drop(['date_type_avg'], axis=1, inplace=True)
# 构造不同月份,不同商店,不同type1个月后的平均特征值
g6 = matrix.groupby(['date_block_num', 'shop_id', 'type_code']).agg(
{'item_cnt_month': ['mean']})
g6.columns = ['date_shop_type_avg']
matrix = pd.merge(matrix, g6.reset_index(), how='left', on=[
'date_block_num', 'shop_id', 'type_code'])
matrix = lag_feature(matrix, [1], 'date_shop_type_avg')
matrix.drop(['date_shop_type_avg'], axis=1, inplace=True)
# 构造不同月份,不同subtype1个月后的平均值特征
g7 = matrix.groupby(['date_block_num', 'subtype_code']).agg(
{'item_cnt_month': ['mean']})
g7.columns = ['date_subtype_avg']
matrix = pd.merge(matrix, g7.reset_index(), how='left', on=[
'date_block_num', 'subtype_code'])
matrix = lag_feature(matrix, [1], 'date_subtype_avg')
matrix.drop(['date_subtype_avg'], axis=1, inplace=True)
# 构造不同月份,不同商店,不同subtype1个月后的平均值特征
g8 = matrix.groupby(['date_block_num', 'shop_id', 'subtype_code']).agg(
{'item_cnt_month': ['mean']})
g8.columns = ['date_shop_subtype_avg']
matrix = pd.merge(matrix, g8.reset_index(), how='left', on=[
'date_block_num', 'shop_id', 'subtype_code'])
matrix = lag_feature(matrix, [1], 'date_shop_subtype_avg')
matrix.drop(['date_shop_subtype_avg'], axis=1, inplace=True)
# 构造不同月份,不同City一个月后的平均值特征
g9 = matrix.groupby(['date_block_num', 'city_code']).agg(
{'item_cnt_month': ['mean']})
g9.columns = ['date_city_avg']
matrix = pd.merge(matrix, g9.reset_index(), how='left', on=[
'date_block_num', 'city_code'])
matrix = lag_feature(matrix, [1], 'date_city_avg')
matrix.drop(['date_city_avg'], axis=1, inplace=True)
# 构造不同月份,不同商品,不同City一个月后的平均值特征
g10 = matrix.groupby(['date_block_num', 'city_code', 'item_id']).agg(
{'item_cnt_month': ['mean']})
g10.columns = ['date_item_city_avg']
matrix = pd.merge(matrix, g10.reset_index(), how='left', on=[
'date_block_num', 'city_code', 'item_id'])
matrix = lag_feature(matrix, [1], 'date_item_city_avg')
matrix.drop(['date_item_city_avg'], axis=1, inplace=True)
print(matrix.info())
# 价格特征
group = sale_df.groupby(['item_id']).agg({'item_price': ['mean']})#创造每个商品的平均价格特征
group.columns = ['item_avg_price']
matrix = pd.merge(matrix, group.reset_index(), how='left', on=['item_id'])
#创造价格趋势特征,因为有的商品可能上个月没有卖,所以选择连续1个-6个月的滞后价格计算变化比例,再循环判断进行选择
group = sale_df.groupby(['date_block_num', 'item_id']
).agg({'item_price': ['mean']})
group.columns = ['date_item_avg_price']
matrix = pd.merge(matrix, group.reset_index(), how='left',
on=['item_id', 'date_block_num'])
matrix = lag_feature(matrix, [1, 2, 3, 4, 5, 6], 'date_item_avg_price')
for i in range(1, 7):
matrix['delta_price_lag_' + str(i)] = (matrix['date_item_avg_price_lag_' + str(
i)] - matrix['item_avg_price']) / matrix['item_avg_price']
print(matrix.info())
def select_trend(df):
for i in range(1, 7):
if df['delta_price_lag_' + str(i)]:
return df['delta_price_lag_' + str(i)]
return 0
matrix['delta_price_lag'] = matrix.apply(lambda x: select_trend(x), axis=1)#创造出价格趋势列
matrix.delta_price_lag.fillna(0,inplace=True)
feature_drop = ['item_avg_price', 'date_item_avg_price']
for i in range(1, 7):
feature_drop += ['date_item_avg_price_lag_' + str(i)]
feature_drop += ['delta_price_lag_' + str(i)]
matrix.drop(feature_drop, axis=1, inplace=True)
#营收趋势
group1=sale_df.groupby(['date_block_num','shop_id']).agg({'revenue':['sum']})#每个月每个商店的总销售额
group1.columns=['date_shop_rev']
matrix=pd.merge(matrix,group1.reset_index(),how='left',on=['date_block_num','shop_id'])
group=group1.groupby(['shop_id']).agg({'date_shop_rev':['mean']})
group.columns=['shop_rev_avg']#每个商店在所有月份的平均销售额
matrix=pd.merge(matrix,group.reset_index(),how='left',on=['shop_id'])
matrix['delta_rev']=(matrix['date_shop_rev']-matrix['shop_rev_avg'])/matrix['shop_rev_avg']
matrix=lag_feature(matrix,[1],'delta_rev')
matrix.drop(['date_shop_rev','shop_rev_avg','delta_rev'],axis=1,inplace=True)
构造商品之间销售的间隔
#加入月和天数特征
matrix['month']=matrix['date_block_num']%12
month_day=pd.Series([31,28,31,30,31,30,31,31,30,31,30,31])
matrix['days']=matrix.month.map(month_day)#增加每行对应的月份天数
#构造shop和item组合的相邻两次售出间隔
cache={}
matrix['item_shop_last_sale']=-1
for indx,row in matrix.iterrows():
key=str(row.item_id)+' '+str(row.shop_id)
if key not in cache:
if row.item_cnt_month!=0:
cache[key]=row.date_block_num
else:
last_date_block_num=cache[key]
matrix.at[indx,'item_shop_last_sale']=row.date_block_num-last_date_block_num
cache[key]=row.date_block_num
#构造item相邻两次售出间隔
cache={}
matrix['item_last_sale']=-1
for indx,row in matrix.iterrows():
key=row.item_id
if key not in cache:
if row.item_cnt_month!=0:
cache[key]=row.date_block_num
else:
last_item_sale_datenum=cache[key]
if row.date_block_num > last_item_sale_datenum:
matrix.at[indx,'item_last_sale']=row.date_block_num-last_item_sale_datenum
cache[key]=row.date_block_num
#构造与第一次售出的间隔
matrix['shop_item_fistsale']=matrix['date_block_num']-matrix.groupby(['shop_id','item_id'])['date_block_num'].transform('min')
matrix['item_firtsale']=matrix['date_block_num']-matrix.groupby(['item_id'])['date_block_num'].transform('min')
模型建立
#因为最多延后12个月,将0-11的数据删掉
matrix=matrix[matrix.date_block_num>11]
#将构造lag_feature的na值填充为0
matrix.fillna(0,inplace=True)
#转换格式
def type_feature(df):
for i in df.columns:
if i!='item_id':
if df[i].dtypes==np.int64:
df[i]=df[i].astype(np.int8)
elif df[i].dtypes==np.float64:
df[i]=df[i].astype(np.float16)
else:
df[i]=df[i].astype(np.int16)
return df
type_feature(matrix)
print(matrix.info())
#建模,34作为预测,12-32作为训练集,33作为验证集
x_train=matrix[matrix.date_block_num<33].drop(['item_cnt_month','date_item_avg_lag_12'],axis=1)
y_train=matrix[matrix.date_block_num<33]['item_cnt_month']
x_valid=matrix[matrix.date_block_num==33].drop(['item_cnt_month','date_item_avg_lag_12'],axis=1)
y_valid=matrix[matrix.date_block_num==33]['item_cnt_month']
x_test=matrix[matrix.date_block_num==34].drop(['item_cnt_month','date_item_avg_lag_12'],axis=1)
from xgboost import XGBRegressor
from xgboost import plot_importance
model=XGBRegressor(max_depth=8,n_estimators=1000,min_child_weight=200,colsample_bytree=0.8,subsample=0.8,eta=0.3,seed=1,n_jobs=-1)
model.fit(x_train,y_train,eval_metric='rmse',eval_set=[(x_train,y_train),(x_valid,y_valid)],verbose=True,early_stopping_rounds=10)
plot_importance(model)
plt.show()
predition_sale=model.predict(x_test).clip(0,20)
submission=pd.DataFrame({'ID':test.index,'item_cnt_month':predition_sale})
submission.to_csv('/Users/shaling/Downloads/competitive-data-science-predict-future-sales/submission.csv',index=False)
其实我原本是想用GridSearchCV进行搜索最佳参数的,然后被打脸了,实在跑的机器吭哧吭哧的,索性就按照常规型的估计着用了
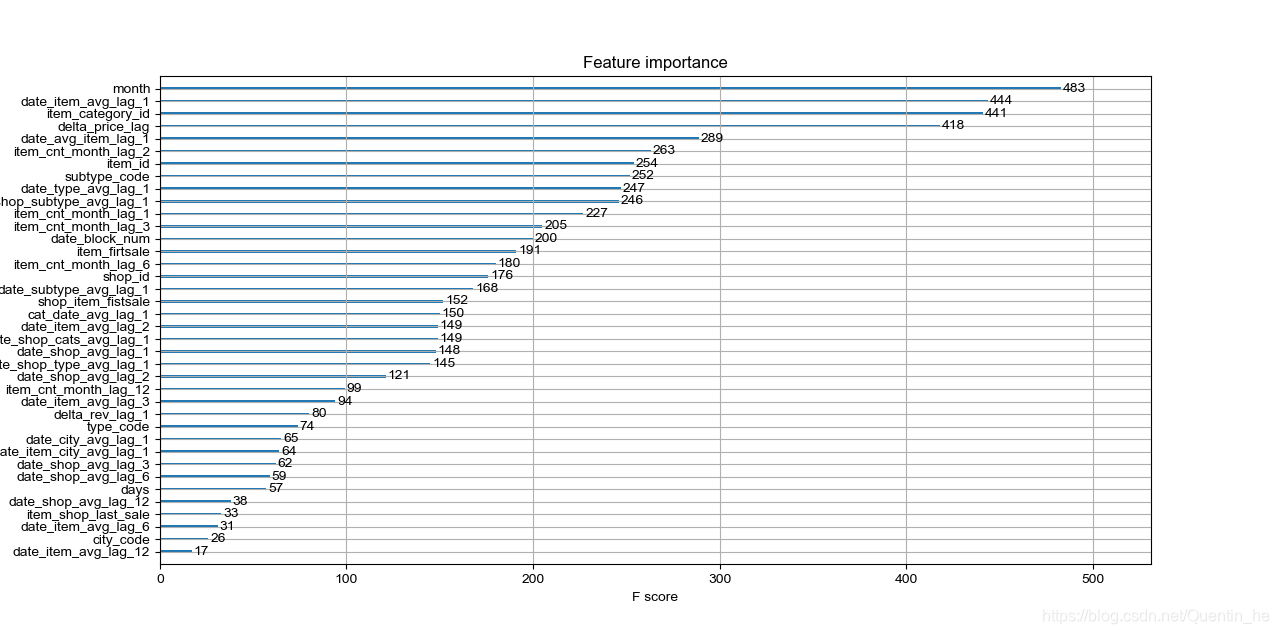
因为发现date_item_avg_lag_12(商品平均销量的12个月滞后特征)重要性不大,便去掉了,但是发现对分数并没有太大提高,kaggle上是按照RMSE标准,提交上去是0.91,排名top23%,不太理想,所以想利用随机森林再跑一下,乖乖,数据量实在太大了,小mac跑不出来,遂利用google的Colaboratory提供的TPU跑,结果也愣是跑不来,主要是内存提供的太少了,总是占满崩溃,或许取一部分数据跑呢?另外部分特征参考了一些Kaggle大神的思路(https://www.kaggle.com/dlarionov/feature-engineering-xgboost),
感受只有一个,特征工程实在太特么重要了!!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









