







 本文详细介绍了K-Means聚类算法,包括其工作原理、与分类算法的比较、K-Means的优缺点以及聚类评估指标。通过实例展示了算法的应用,并讨论了初始质心的选择、迭代问题以及如何处理K值选取等问题,强调了K-Means在数据挖掘和分析中的重要性。
本文详细介绍了K-Means聚类算法,包括其工作原理、与分类算法的比较、K-Means的优缺点以及聚类评估指标。通过实例展示了算法的应用,并讨论了初始质心的选择、迭代问题以及如何处理K值选取等问题,强调了K-Means在数据挖掘和分析中的重要性。
概述
众所周知,机器学习算法可分为监督学习(Supervised learning)和无监督学习(Unsupervised learning)。
监督学习常用于分类和预测。是让计算机去学习已经创建好的分类模型,使分类(预测)结果更好的接近所给目标值,从而对未来数据进行更好的分类和预测。因此,数据集中的所有变量被分为特征和目标,对应模型的输入和输出;数据集被分为训练集和测试集,分别用于训练模型和模型测试与评估。常见的监督学习算法有Regression(回归)、KNN和SVM(分类)。
无监督学习常用于聚类。输入数据没有标记,也没有确定的结果,而是通过样本间的相似性对数据集进行聚类,使类内差距最小化,类间差距最大化。无监督学习的目标不是告诉计算机怎么做,而是让它自己去学习怎样做事情,去分析数据集本身。常用的无监督学习算法有K-means、 PCA(Principle Component Analysis)。
聚类算法又叫做“无监督分类”,其目的是将数据划分成有意义或有用的组(或簇)。这种划分可以基于业务需求或建模需求来完成,也可以单纯地帮助我们探索数据的自然结构和分布。比如在商业中,如果手头有大量的当前和潜在客户的信息,可以使用聚类将客户划分为若干组,以便进一步分析和开展营销活动。再比如,聚类可以用于降维和矢量量化,可以将高维特征压缩到一列当中,常常用于图像、声音和视频等非结构化数据,可以大幅度压缩数据量。
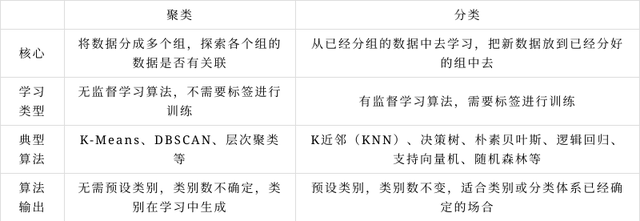
聚类算法与分类算法的比较:
K-Means详解
1. K-Means的工作原理
作为聚类算法的典型代表,K-Means可以说是最简单的聚类算法,那它的聚类工作原理是什么呢?

在K-Means算法中,簇的个数K是一个超参数,需要人为输入来确定。K-Means的核心任务就是根据设定好的K,找出K个最优的质心,并将离这些质心最近的数据分别分配到这些质心代表的簇中去。具体过程可以总结如下:
a.首先随机选取样本中的K个点作为聚类中心;
b.分别算出样本中其他样本距离这K个聚类中心的距离,并把这些样本分别作为自己最近的那个聚类中心的类别;
c.对上述分类完的样本再进行每个类别求平均值,求解出新的聚类质心;
d.与前一次计算得到的K个聚类质心比较,如果聚类质心发生变化,转过程b,否则转过程e;
e.当质心不发生变化时(当我们找到一个质心,在每次迭代中被分配到这个质心上的样本都是一致的,即每次新生成的簇都是一致的,所有的样本点都不会再从一个簇转移到另一个簇,质心就不会变化了),停止并输出聚类结果。K-Means算法计算过程如图1 所示:
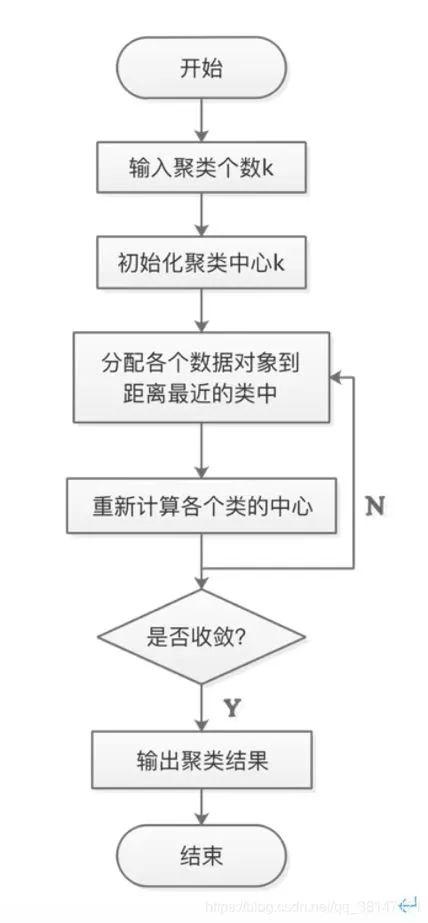
图1 K-Means算法计算过程
例题:
1. 对于以下数据点,请采用k-means方法进行聚类(手工计算)。假设聚类簇数k=3,初始聚类簇中心分别为数据点2、数据点3、数据点5。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









