







 本文介绍了使用Python爬取王者荣耀所有英雄皮肤的过程,包括目标设定、环境配置、网页分析、问题发现(官方json文件未及时更新皮肤信息)及解决方案。通过修改本地json文件,实现了完整皮肤图片的下载。代码示例展示了两种不同的实现方式,一种基于官方未更新的json,另一种基于作者手动更新的json。
本文介绍了使用Python爬取王者荣耀所有英雄皮肤的过程,包括目标设定、环境配置、网页分析、问题发现(官方json文件未及时更新皮肤信息)及解决方案。通过修改本地json文件,实现了完整皮肤图片的下载。代码示例展示了两种不同的实现方式,一种基于官方未更新的json,另一种基于作者手动更新的json。
文章目录
一、目标
爬取王者荣耀英雄的所有的皮肤保存到文件夹

二、环境
用到的爬虫的requests
三、分析网页和url
1.英雄库的url:https://pvp.qq.com/web201605/herolist.shtml
2.发现的英雄信息的json文件
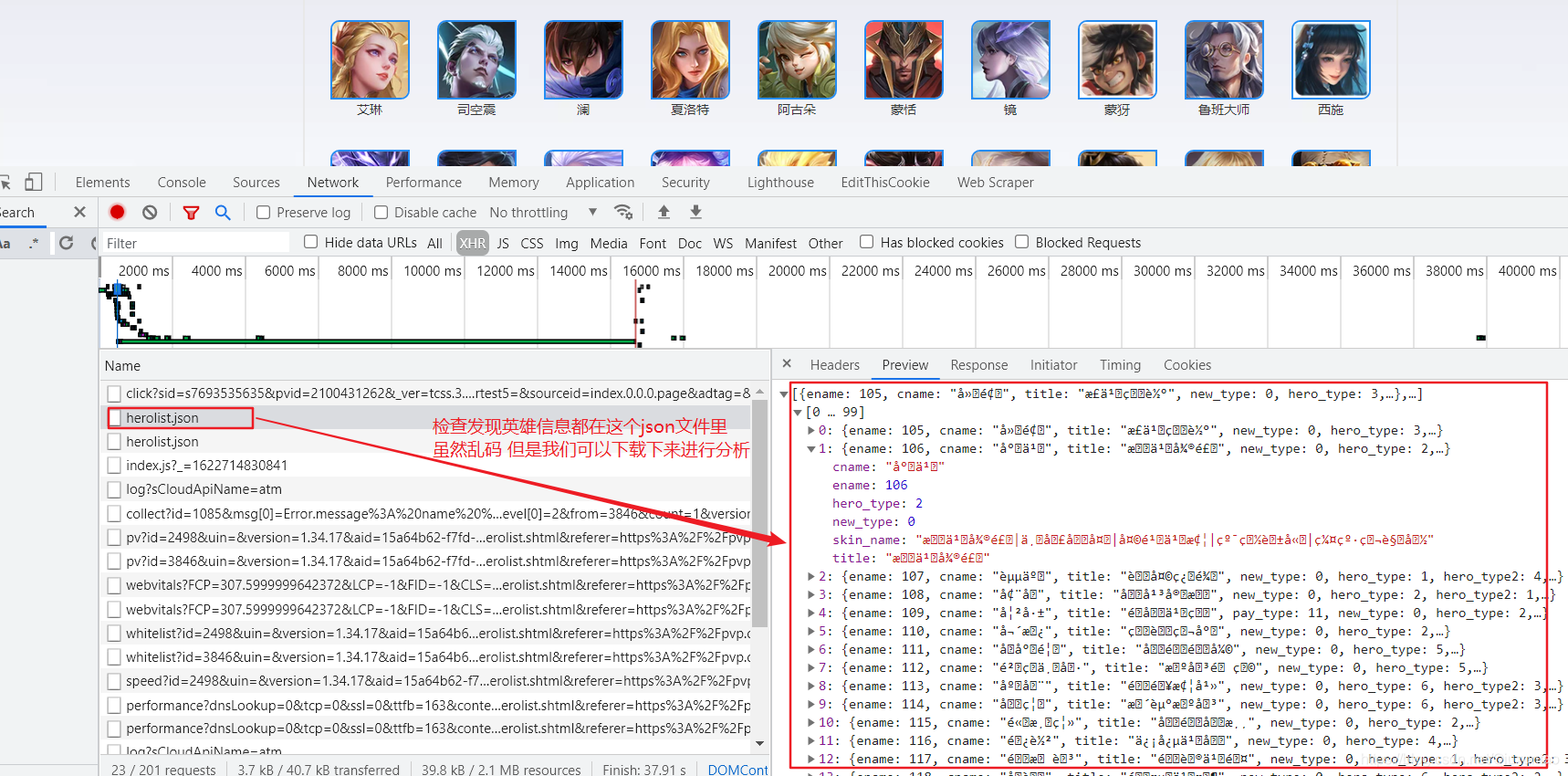
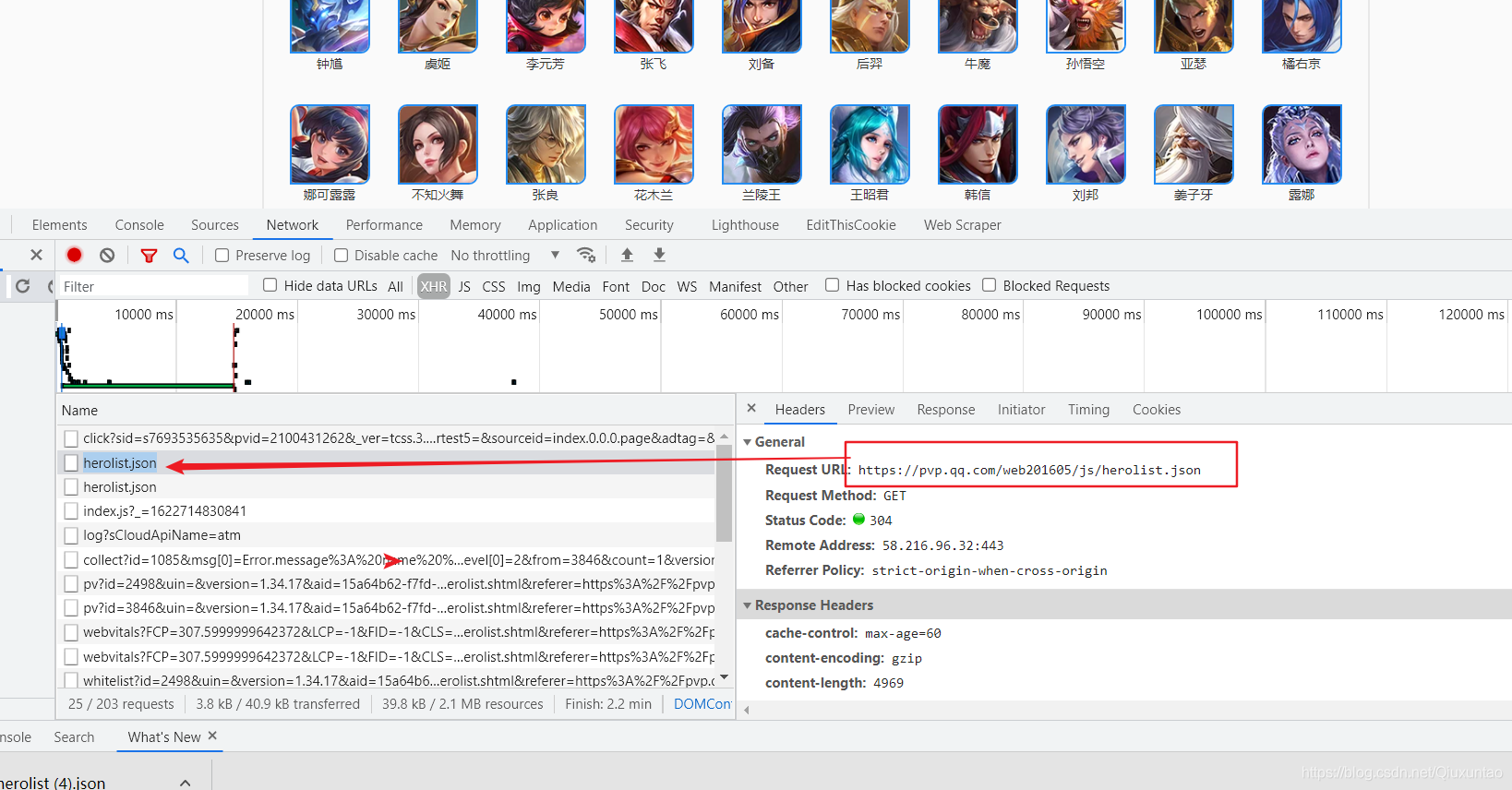
3.双击这个herolist.json文件直接把文件下载都本地,打开发现没有乱码
官方的url:http://pvp.qq.com/web201605/js/herolist.json
4.接着我们分析图片的url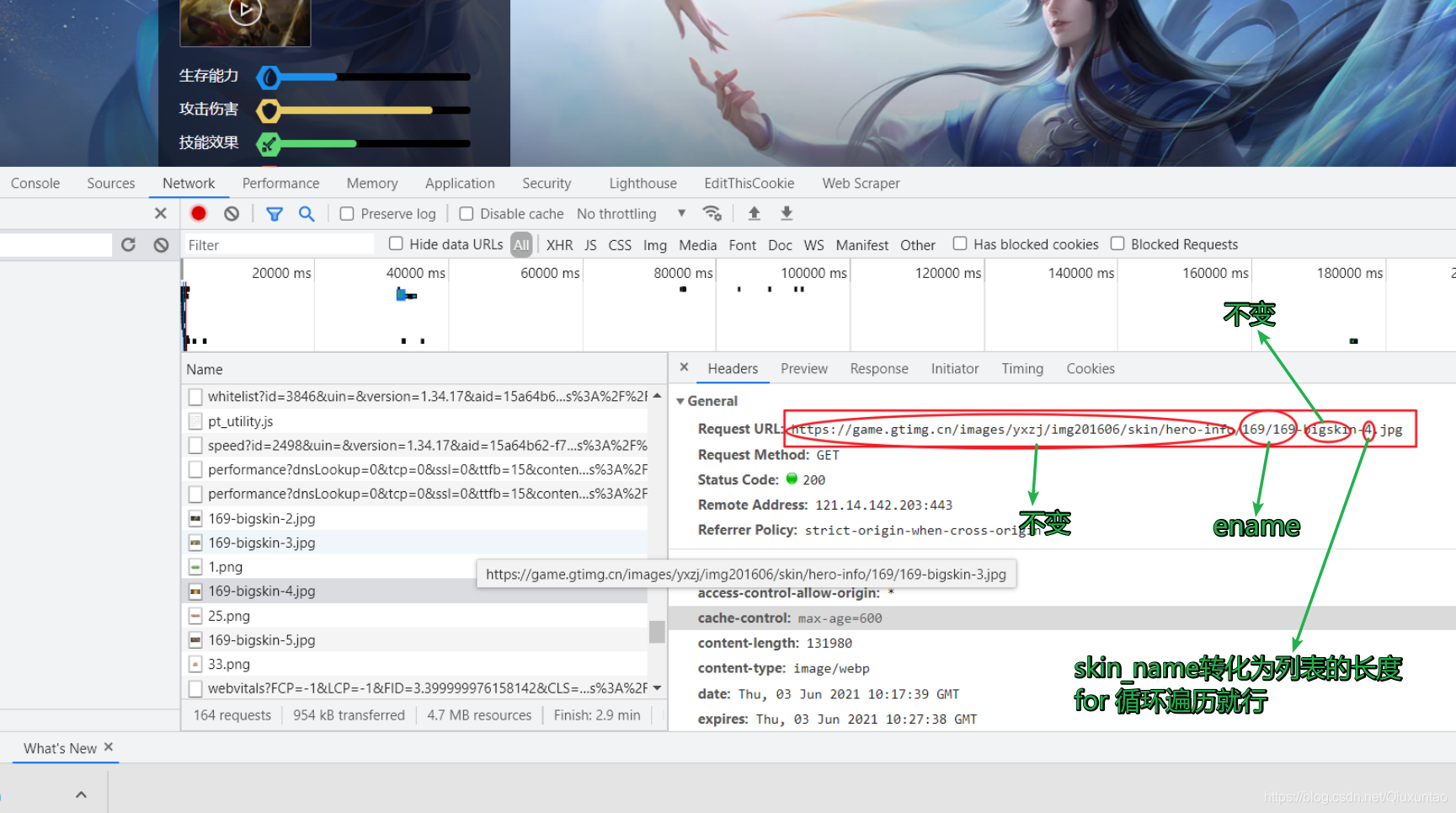
四、发现问题
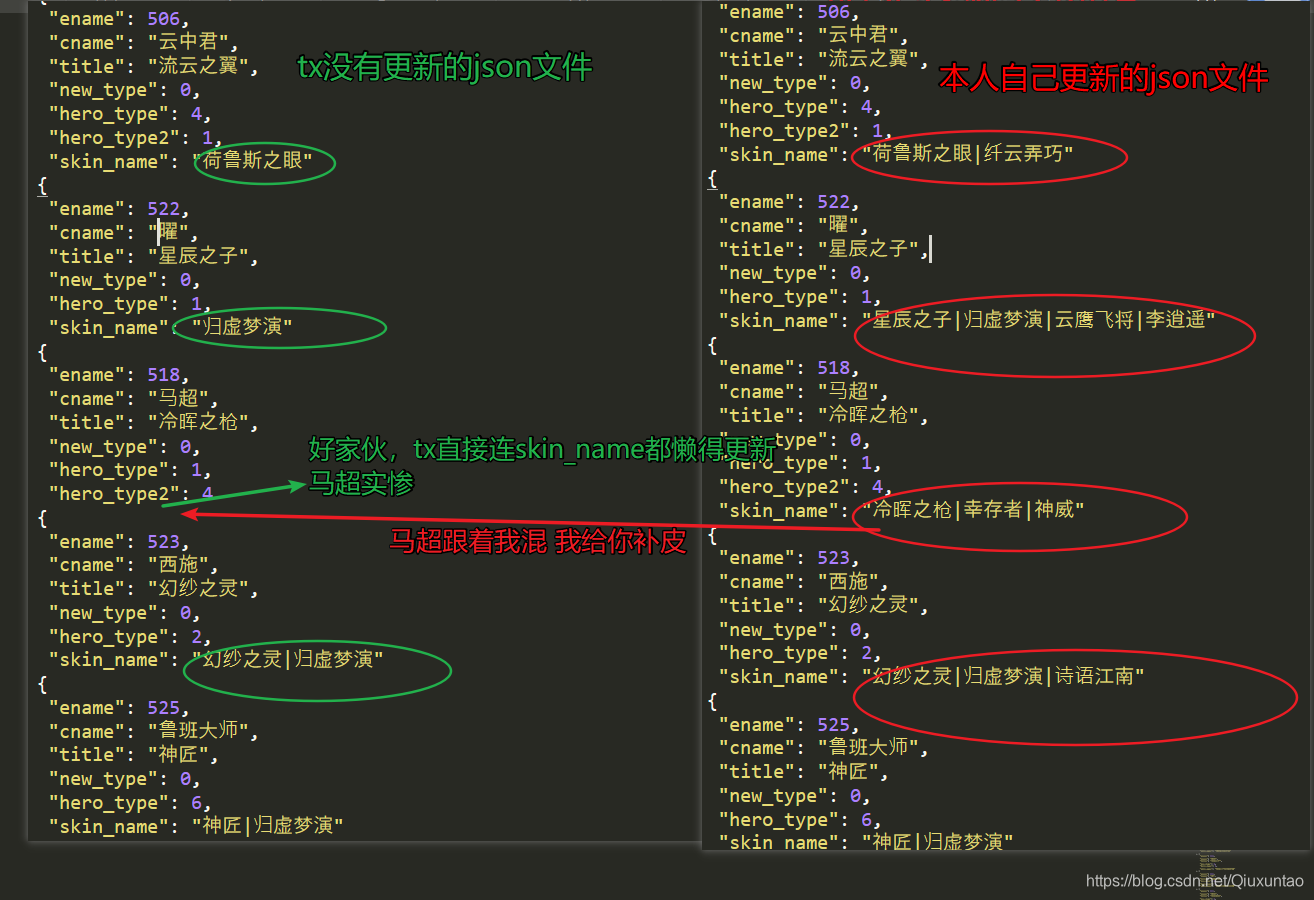
1.结果反复测试,发现由于tengxun自己很久没有更新json文件里面skin_name,导致没有办法把图片下载全,所以我直接手动添加更新了的皮肤的名字,直接用pycharm读取我更新了的本地的herolist.json文件,使得把所有皮肤都下载全了,tx工作人员好懒,点名批评
五、代码
代码1
1.代码1:通过官方的没有更新的url下载图片的代码,会缺少好多近期新出的图片
import requests
import json
import os
import time
from tqdm import tqdm
from time import sleep
# 程序开始时间
start = time.time()
# f = open('D:\Python2020-王明东\爬虫self\wzryskin.json', encoding='utf-8')
# # 将json格式的数据映射成list的形式
# json_file = json.load(f)
# print(json_file)
url = requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
# 提取json文件
jsonFile = json.loads(url)
# 打印json文件并且分析
print(jsonFile)
# 记录下载的王者荣耀图片张数
x = 0
# 如果目录不存在就重新创建
wzry_hero_skin_dir = 'D:/Python2020-王明东/爬虫self/王者荣耀/'
if not os.path.exists(wzry_hero_skin_dir):
os.mkdir(wzry_hero_skin_dir)
for m in range(len(jsonFile)):
# 英雄编号
ename = jsonFile[m]['ename']
# 打印编号和类型
print(ename, "-----", type(ename))
# 英雄名字
cname = jsonFile[m]['cname']
# 分类文件夹
hero_skin_dir = wzry_hero_skin_dir + cname + "/"
if not os.path.exists(hero_skin_dir):
os.mkdir(hero_skin_dir)
# 经过测试,因为编号518没有皮肤 ,需要用continue跳过,否则报错
if jsonFile[m]['ename'] == 518:
continue
# 分割皮肤的名字,用于计算每个英雄有多少个皮肤,后面对名字进行遍历下载
skinName = jsonFile[m]['skin_name'].split('|')
print(skinName) # ['和平守望', '金属风暴', '龙骑士', '进击墨子号']
skinNumber = len(skinName) # 4
print("长度是%s,%s有%s个皮肤" % (skinNumber, cname, skinNumber)) # 长度是4,墨子有4个皮肤
# 下载王者荣耀英雄图片,分析json文件和图片路由,对网址进行拼接
# 低奢的一种进度条显示的方法,就是利用tqdm库来实现
for bigskin in tqdm(range(1, skinNumber + 1)):
Pictrue_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(
ename) + '-bigskin-' + str(bigskin) + '.jpg'
# 获取王者荣耀英雄图片的二进制信息
skin_picture = requests.get(Pictrue_url).content
# 保存王者荣耀英雄图片
with open(hero_skin_dir + cname + "-" + skinName[bigskin - 1] + '.jpg', 'wb') as f:
f.write(skin_picture)
x = x + 1
print("正在下载....第%s张,--%s--%s--地址是:%s" % (x, cname, skinName[bigskin - 1], Pictrue_url))
# 显示间隔,sec越小,速度越快
sleep(0.01)
# 程序结束时间
end = time.time()
# 计算执行时间
time_second = end - start
print("本次服务共下载%s张王者荣耀皮肤图片,一共耗时%s秒,欢迎下次光临" % (x, time_second))
代码2
代码2:通过我自己修改的json文件下载的图片,基本上是一张不少,如果我没有漏的话
import requests
import json
import os
import time
from tqdm import tqdm
from time import sleep
# 程序开始时间
start = time.time()
f = open('D:\Python2020-王明东\爬虫self\wzryskin.json', encoding='utf-8')
# 将json格式的数据映射成list的形式
json_file = json.load(f)
print(json_file)
# url = requests.get('http://pvp.qq.com/web201605/js/herolist.json').content
# # 提取json文件
# jsonFile = json.loads(url)
# # 打印json文件并且分析
# print(jsonFile)
# # 记录下载的王者荣耀图片张数
x = 0
# 如果目录不存在就重新创建
wzry_hero_skin_dir = 'D:/Python2020-王明东/爬虫self/王者荣耀/'
if not os.path.exists(wzry_hero_skin_dir):
os.mkdir(wzry_hero_skin_dir)
for m in range(len(json_file)):
# 英雄编号
ename = json_file[m]['ename']
# 打印编号和类型
print(ename, "-----", type(ename))
# 英雄名字
cname = json_file[m]['cname']
# 分类文件夹
hero_skin_dir = wzry_hero_skin_dir + cname + "/"
if not os.path.exists(hero_skin_dir):
os.mkdir(hero_skin_dir)
# 经过测试,因为编号518没有皮肤 ,需要用continue跳过,否则报错
# if t[m]['ename'] == 518:
# continue
# 分割皮肤的名字,用于计算每个英雄有多少个皮肤,后面对名字进行遍历下载
skinName = json_file[m]['skin_name'].split('|')
print(skinName) # ['和平守望', '金属风暴', '龙骑士', '进击墨子号']
skinNumber = len(skinName) # 4
print("长度是%s,%s有%s个皮肤" % (skinNumber, cname, skinNumber)) # 长度是4,墨子有4个皮肤
# 下载王者荣耀英雄图片,分析json文件和图片路由,对网址进行拼接
# 低奢的一种进度条显示的方法,就是利用tqdm库来实现
for bigskin in tqdm(range(1, skinNumber + 1)):
Pictrue_url = 'http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/' + str(ename) + '/' + str(
ename) + '-bigskin-' + str(bigskin) + '.jpg'
# 获取王者荣耀英雄图片的二进制信息
skin_picture = requests.get(Pictrue_url).content
# 保存王者荣耀英雄图片
with open(hero_skin_dir + cname + "-" + skinName[bigskin - 1] + '.jpg', 'wb') as f:
f.write(skin_picture)
x = x + 1
print("正在下载....第%s张,--%s--%s--地址是:%s" % (x, cname, skinName[bigskin - 1], Pictrue_url))
# 显示间隔,sec越小,速度越快
sleep(0.01)
# 程序结束时间
end = time.time()
# 计算执行时间
time_second = end - start
print("本次服务共下载%s张王者荣耀皮肤图片,一共耗时%s秒,欢迎下次光临" % (x, time_second))
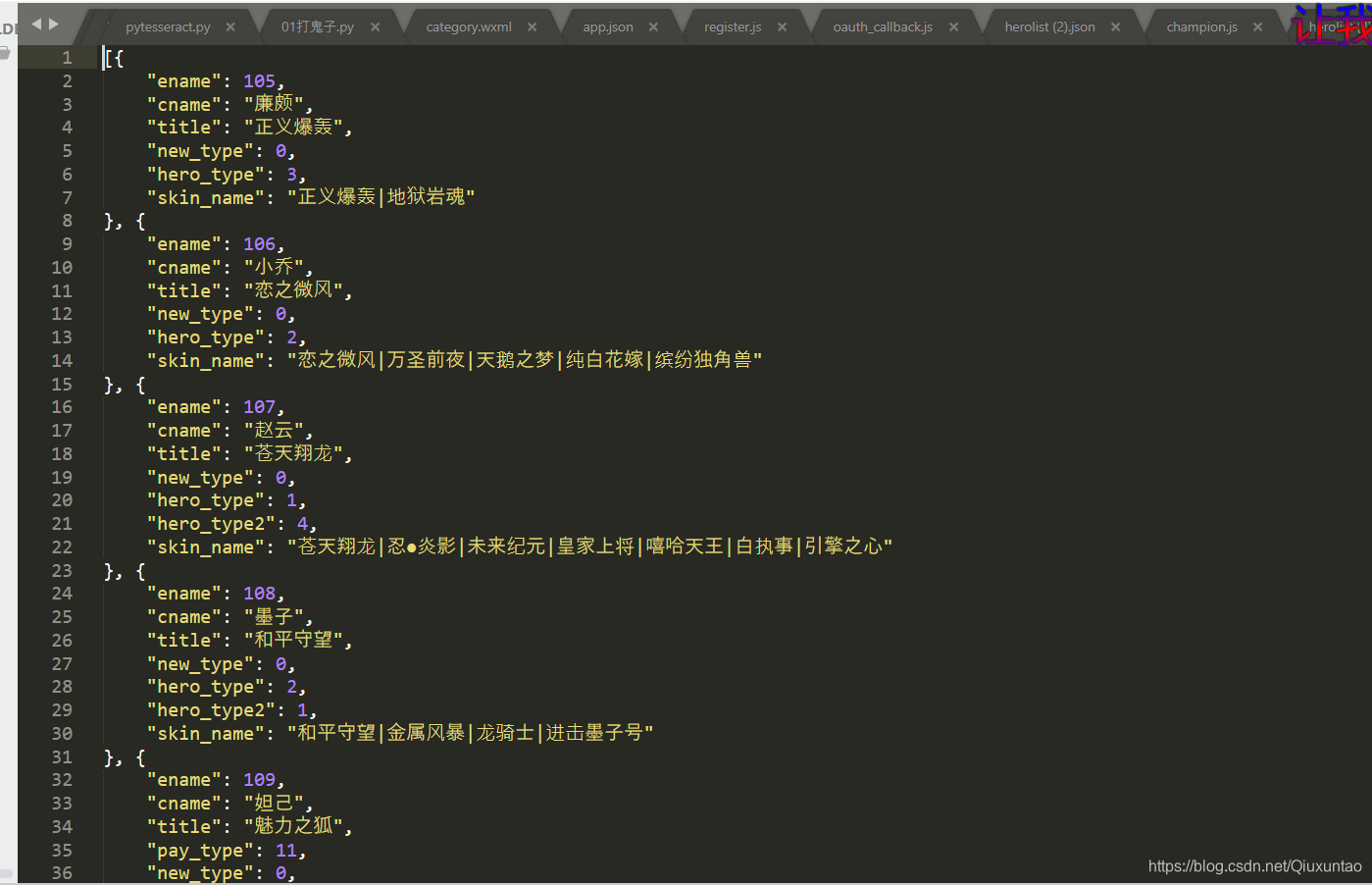
json文件夹代码:
[{
"ename": 105,
"cname": "廉颇",
"title": "正义爆轰",
"new_type": 0,
"hero_type": 3,
"skin_name": "正义爆轰|地狱岩魂"
}, {
"ename": 106,
"cname": "小乔",
"title": "恋之微风",
"new_type": 0,
"hero_type": 2,
"skin_name": "恋之微风|万圣前夜|天鹅之梦|纯白花嫁|缤纷独角兽|丁香结|青蛇|音你心动"
}, {
"ename": 107,
"cname": "赵云",
"title": "苍天翔龙",
"new_type": 0,
"hero_type": 1,
"hero_type2": 4,
"skin_name": "苍天翔龙|忍●炎影|未来纪元|皇家上将|嘻哈天王|白执事|引擎之心|龙胆"
}, {
"ename": 108,
"cname": "墨子",
"title": "和平守望",
"new_type": 0,
"hero_type": 2,
"hero_type2": 1,
"skin_name": "和平守望|金属风暴|龙骑士|进击墨子号"
}, {
"ename": 109,
"cname": "妲己",
"title": "魅力之狐",
"pay_type": 11,
"new_type": 0,
"hero_type": 2,
"skin_name": "魅惑之狐|女仆咖啡|魅力维加斯|仙境爱丽丝|少女阿狸|热情桑巴|时之彼端"
}, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









