







目录
1 表的键约束
主键约束
是一种特殊的唯一索引,在一张表中只能定义一个主键索引,主键用于唯 一标识一条记录
外键约束:
外键是表中的一个字段,可以不是本表主键,但对应另外一个表的主键。
定义外键后不允许删除在另一个表中具有关联关系的行。
外键主要作用是保证数据引用的完整性。
非空约束
唯一约束
唯一约束要求该字段唯一,允许为空但只能出现一次
默认约束
字段未赋值时的默认值
属性值自动增加
一个表只能有一个字段设置属性值自动增加,且该字段必须为主键的一部分,字段类型需要时任何整型
CREAT TABLE tb_emp
(
id INT(11) PRIMARY KEY ATUO_INCREMENT, # 主键约束,自增
name VARCHAR(25) NOT NULL, # 非空约束
id_card INT(13) UNIQUE, # 唯一约束
deptId INT(11) DEFAULT 111, # 默认约束
salary FLOAT,
// 定义完成后指定约束
CONSTRAINT fk_emp _empDept FOREIGN KEY(deptId) REFERENCES tb_dept(id) # 外键约束
[
PRIMARY KEY (name,id_card), # 联合主键
CONSTRAINT STH UNIQUE (id_card), # 唯一约束
]
)
2 表操作
查看表结构
DESC 表名
查看详细表结构
SHOW CREATE TABLE 表名\G
3 查询数据
3.1 模糊查询 like
支持两种通配符
(1)“%” 匹配多个
(2)“_” 匹配一个
SELECT name LIKE '%三_' FROM emp
3.2 查询结果不重复 DISTINCT
SELECT DISTINCT 字段名
SELECT DISTINCT name FROM emp; # 查询获取不重复的姓名
3.3 排序 sort
DESC ------- 降序
ASC --------- 升序(默认)
SELECT * FROM empt ORDER BY deptId,salary DESC; # 先按照deptId排序,后按照salary排序
3.4 分组查询
GROUP BY 经常与集合函数一起使用,例如:MAX() , MIN() , COUNT() , SUM() , AVG() 等
# 按照s_id排序 并统计种类大于1的每种水果
SELECT s_id, GROUP_CONCAT(f_name) AS name
FROM fruits
GROUP BY s_id HAVING COUNT(f_name) > 1;
SELECT s_id, COUNT(*) AS total
FROM fruits
GROUP BY s_id WITH ROLLUP; # WITH ROLLUP 对分组结果进行统计
SELECT * FROM fruits GROUP BY s_id, s_name; # 层次分组 先按 s_id 排序分组,后按 s_name 排序分组
对分组进行排序
SELECT s_id, SUM(quantity * item_price) AS total
FROM fruits
GROUP BY s_id
HAVING SUM(quantity * item_price) > 100
ORDER BY total ; # 按照总价格 total 排序分组结果
3.5 限制查询结果数量
SELECT * FROM fruits LIMIT 4; # 查询前四行
SELECT * FROM fruits LIMIT 4, 3; # 从第5条记录开始,查询三行(5,6,7)
3.6 连接查询
高并发环境下避免太多连接查询
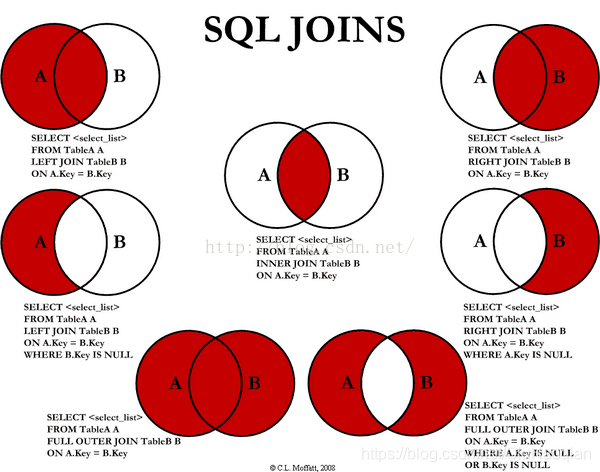
SELECT c.c_id, o.o_num
FROM customers c LEFT JOIN orders o
ON c.c_id = o.c_id
mysql不支持 FULL OUTER JOIN 可以使用 union 实现
3.7 子查询
子查询中结果常作为外层另一个查询的过滤条件
子查询常用的配套操作符有:ANY , ALL , IN , EXISTS
SELECT num1 FROM tb1 WHERE num1 > ANY(SELECT num2 FROM tb2);
# 如果suppliers表中存在 s_id = 107 的供应商,则查询 fruits表中 f_price > 10 的记录
SELECT * FROM fruits
WHERE f_price > 10 AND [NOT] EXISTS
(SELECT s_name FROM suppliers WHERE s_id = 107)
# 查询fruits中 由 suppliers 供应商提供的水果数据
SELECT * FROM fruits
WHERE s_name [NOT] IN
(SELECT s_name FROM suppliers)
3.8 合并查询 UNION
将多条SELECT 的结果组合成单个结果集,合并时两个表对应的列数和数据类型必须相同
UNION ----------- 删除重复记录,返回的行都是唯一的
UNION ALL------不删除重复行
SELECT s_id, f_name, f_price
FROM fruits
WHERE f_price < 9.0
UNION [ALL]
SELECT s_id, f_name, f_price
FROM fruits
WHERE s_id IN(101,103);
3.9 为字段或者表起别名 AS
SELECT f1.f_name AS fruit_name, f1.f_price AS fruit_price
FROM fruits AS f1
WHERE f1.f_price < 8;
3.9 使用正则表达式查询 REGEXP
SELECT * FROM fruits WHERE f_name REGEXP '^b';
4 增删改数据
4.1 插入
# 插入一条
INSERT INTO person (age,name,password) VALUES (22,'小明','123456');
# 插入多条
INSERT INTO person (age,name,password)
VALUES (22,'小明','123456'),
(23,'小红','123456'),
(24,'小白','123456');
# 将查询结果插入
INSERT INTO person (age,name,password)
SELECT age,name,password FROM person WHERE id = 5;
4.2 更新
注意更新不写条件子句会更新表中所有记录
UPDATE person SET info='student',password='12345 WHERE age BETWEEN 7 AND 18;
4.3 删除
注意删除不写条件子句会删除表中所有记录
DELETE FROM person WHERE id = 1;
5 索引
5.1 设计原则
(1) 索引并非越多越好,索引会影响增删改的性能,避免对经常增删改的表进行过多索引;
(2) 经常用于查询的字段应该创建索引,组合索引优于单列索引,组合索引的索引列尽可能少;
(3) 数据量小的表不要创建索引;
(4) 不同值很少的列上不要建立索引;
(5) 唯一性是某种数据的本质时,指定唯一索引;
(6) 频繁进行排序或分组的列上建立索引
索引命名规则: idx_字段名1字段名2字段名3
注意:索引的排序与索引建立时字段的顺序一致
5.2 建表时创建索引
CREAT TABLE tb_emp
(
id INT(11) PRIMARY KEY ATUO_INCREMENT, # 主键约束,自增
name VARCHAR(25) NOT NULL, # 非空约束
age INT(3),
idCard INT(13) UNIQUE, # 唯一约束
deptId INT(11) DEFAULT 111, # 默认约束
salary FLOAT,
address VARCHAR(250),
INDEX idx_name(name), # 单列索引
INDEX idx_nameAgeSalary(name,age,aslary), # 组合索引
UNIQUE INDEX idx_idCard(idCard) # 唯一索引
);
5.3 已经存在的表上创建索引
方式1:ALTER TABLE 语句
ALTER TABLE 表名 ADD INDEX 索引名 (字段); # 单列索引
ALTER TABLE 表名 ADD INDEX 索引名 (字段1,字段2,字段3); # 组合索引
ALTER TABLE 表名 ADD UNIQUE INDEX 索引名 (字段); # 唯一索引
方式2:CREATE INDEX 语句
CREATE INDEX 索引名 ON 表名(字段); # 单列索引
CREATE INDEX 索引名 ON 表名(字段1,字段2,字段3); # 组合索引
CREATE UNIQUE INDEX 索引名 ON 表名(字段); # 唯一索引
5.4 查看索引
SHOW INDEX FROM 表名 [\G];
5.5 删除索引
如果删除列为索引的组成部分,删除该列,该列也会从索引中删除;
如果索引的所有列都被删除,则该索引将被删除。
方式1:ALTER TABLE 语句
ALTER TABLE 表名 DROP INDEX 索引名;
方式2:DROP INDEX 语句
DROP INDEX 索引名 ON 表名
6 视图
视图是一个虚拟表,是从一个或多个表中导出来的表
视图作用:简单化(看到的就是需要的)、安全性(通过视图用户只能查询和修改他们能看到的数据)
当对视图看到的数据进行修改时相应的基本表的数据也要发生改变,关联的视图都会改变;基本表的数据发生改变时,这些变化会自动映射到视图中
6.1 创建视图
CREATE VIEW v_t AS SELECT name,age,salary FROM person;
创建视图时重命名
CREATE VIEW v_person(v_name,v_age,v_salary) AS SELECT name,age,salary FROM person;
基于多表创建视图
CREATE VIEW v_personDept(v_name,v_age,v_salary,v_dept) AS
SELECT p.name,p.age,p.salary,d.name FROM person p, dept d WHERE p.d_id = d.id;
6.2 查看视图
DESCRIBE 视图名称
6.3 修改视图
方法1
CREATE OR REPLACE VIEW 视图名称 AS 查询语句 # 视图存在则更新,不存在则创建
CREATE OR REPLACE VIEW view1 AS SELECT * FROM person
方法2
ALTER VIEW view1 AS SELECT * FROM person
6.4 删除视图
DROP VIEW [IF EXISTS] 视图1[,视图2,视图3...]
视图的增删改查同普通表
7 数据库备份
备份
mysqldump -u 用户名 -h 主机 -p 密码 数据库[表1[,表2,表3...]] > 文件全路径/文件名.sql
恢复
mysql -u 用户名 -p 密码 [数据库] < 文件全路径/文件名.sql


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









