




 本文介绍了如何利用Kubernetes和KubeSphere构建企业级机器学习平台,解决算力利用率低、存储运维成本高、数据集安全和测试成本高等问题。通过KubeSphere的多集群管理、自定义监控等功能,实现GPU资源的高效利用和安全管理,降低测试成本。同时,探讨了未来云原生AI平台的发展趋势,如Serverless在AI领域的应用。
本文介绍了如何利用Kubernetes和KubeSphere构建企业级机器学习平台,解决算力利用率低、存储运维成本高、数据集安全和测试成本高等问题。通过KubeSphere的多集群管理、自定义监控等功能,实现GPU资源的高效利用和安全管理,降低测试成本。同时,探讨了未来云原生AI平台的发展趋势,如Serverless在AI领域的应用。
人工智能与 Kubernetes
在国外众多知名网站 2021 年对 Kubernetes 的预测中,人工智能技术与 Kubernetes 的更好结合通常都名列其中。Kubernetes 以其良好的扩展和分布式特性,以及强大的调度能力成为运行 DL/ML 工作负载的理想平台。

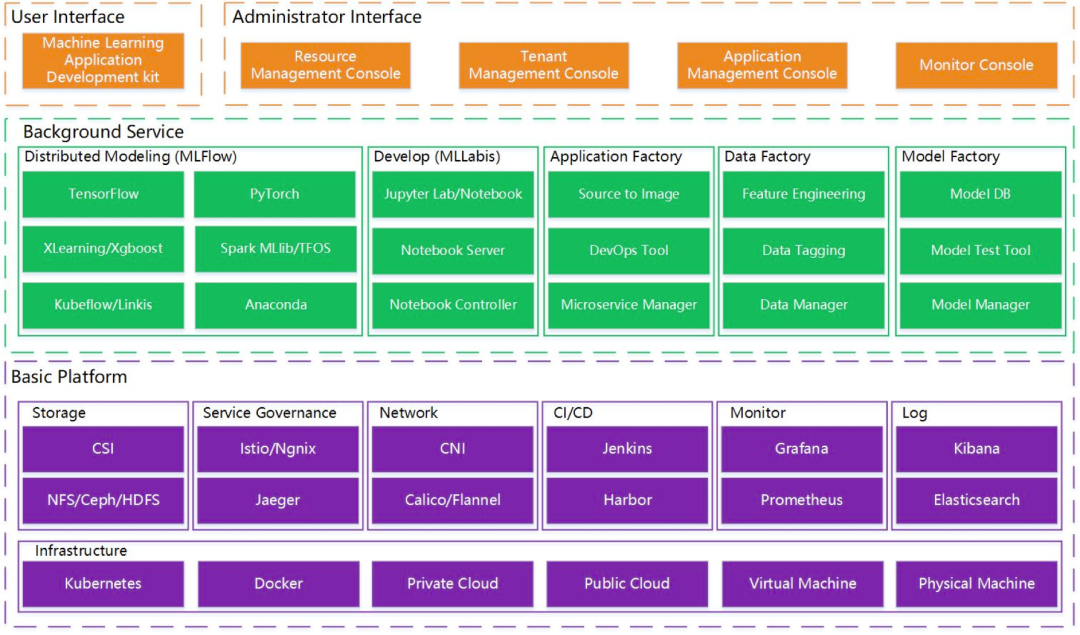
上面是微众银行开源的机器学习平台 Prophecis 的架构图,我们可以看到绿色的部分是机器学习平台通常都会有的功能包括训练、开发、模型、数据和应用的管理等功能。而通常这些机器学习平台都是运行在 Kubernetes 之上的,如紫色的部分所示:最底层是 Kubernetes,再往上是容器管理平台 (微众银行的开发者曾在 KubeSphere 2020 Meetup 北京站上提到这里采用的是 KubeSphere),容器管理平台在 Kubernetes 之上提供了存储、网络、服务治理、CI/CD、以及可观测性方面的能力。
Kubernetes 很强大,但通常在 Kubernetes 上运行 AI 的工作负载还需要更多非 K8s 原生能力的支持比如:
-
用户管理: 涉及多租户权限管理等
-
多集群管理
-
图形化 GPU 工作负载调度
-
GPU 监控
-
训练、推理日志管理
-
Kubernetes 事件与审计
-
告警与通知
具体来说 Kubernetes 并没有提供完善的用户管理能力,而这是一个企业级机器学习平台的刚需;同样原生的 K8s 也并没有提供多集群管理的能力,而用户有众多 K8s 集群需要统一管理;运行 AI 工作负载需要用到 GPU,昂贵的 GPU 需要有更好的监控及调度才能提高 GPU 利用率并节省成本;AI 的训练需要很长时间才能完成,从几个小时到几天不等,通过容器平台提供的日志系统可以更容易地看到训练进度;容器平台事件管理可以帮助开发者更好地定位问题;容器平台审计管理可以更容易地获知谁对哪些资源做了什么操作,让用户对整个容器平台有深入的掌控。
总的来说,K8s 就像 Linux/Unix, 但用户仍然需要 Ubuntu 或 Mac 。KubeSphere 是企业级分布式多租户容器平台,本质上是一个现代的分布式操作系统。KubeSphere 在 K8s 之上提供了丰富的平台能力如用户管理、多集群管理、可观测性、应用管理、微服务治理、CI/CD 等。
如何利用 K8s 和 KubeSphere 构建机器学习平台
极栈平台是一个面向企业或机构的机器学习服务平台,提供从数据处理、模型训练、模型测试到模型推理的 AI 全生命周期管理服务,致力于帮助企业或机构迅速构建 AI 算法开发与应用能力。平台提供低代码开发与自动化测试功能,支持任务智能调度与资源智能监控,帮助企业全面提升 AI 算法开发效率,降低 AI 算法应用与管理成本,快速实现智能化升级。
极栈 AI 平台迭代演变的挑战
在使用 Kubernetes 之前,平台使用 Docker 挂载指定 GPU 来分配算力,容器内置 Jupyter 在线 IDE 实现和开发者交互,开发者在分配的容器内完成训练测试代码编写、模型训练,当时存在四个问题需要解决:
-
算力利用率低:开发者在编码时,GPU 仅仅用于代码调试;同时开发者需手动开启或者关闭环境,如果开发者训练结束未关闭环境,将继续占用算力资源。以算法大赛的场景为例,算力利用率平均在 50%,算力资源浪费严重。
-
存储运维成本高:平台使用 Ceph 来存储数据集、代码,比如容器挂载了 Ceph 的块存储来持久化存储开发环境,方便再次使用时能在其他 node 还原。在大量开发者使用时,出现挂载卷释放不了、容器无法停止等问题,影响开发者使用。
-
数据集安全无法保障:商用算法数据集往往涉密,需要实现数据所有权和使用权分离,比如许多大型政企开发算法往往外包给专业的 AI 公司。怎么让外部 AI 公司的算法工程师在既能完成算法开发,又能不接触到数据集,是政企算法平台客户的迫切需求。
-
算法测试人力成本高:对于算法开发者提交的算法,要对精度和性能等指标进行评测,达到算法需求方要求的精度和性能指标后方可上线。还是以算法大赛的场景举例,一般
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









