







论文作者:Jinlong Li,Cristiano Saltori,Fabio Poiesi,Nicu Sebe
作者单位:University of Trento ;Fondazione Bruno Kessler
论文链接:http://arxiv.org/abs/2503.16707v1
项目链接:https://github.com/TyroneLi/CUA_O3D
内容简介:
1)方向:3D场景理解
2)应用:3D场景理解
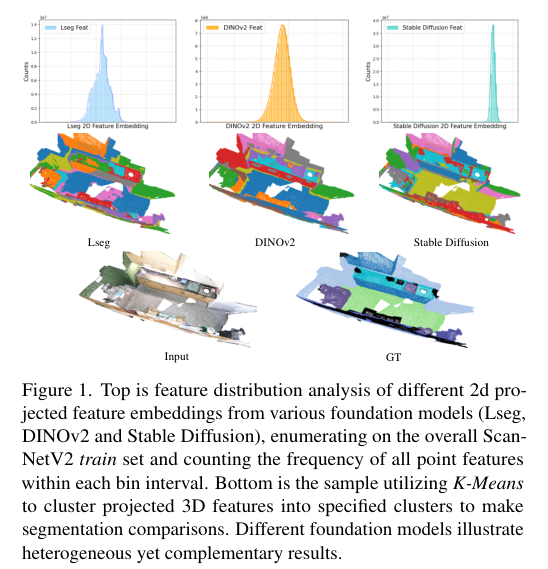
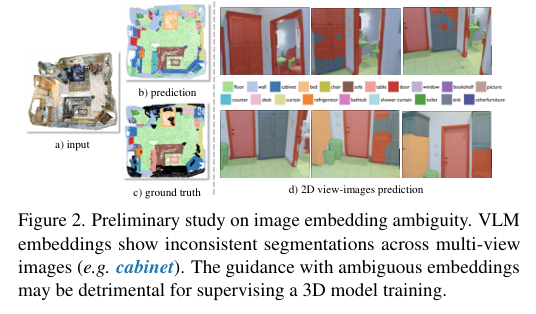
3)背景:目前缺乏大规模的3D文本语料库,这导致现有的研究通常依赖单一的视觉语言模型(VLM)来对齐3D模型的特征空间。但这种方法仅使用单一的VLM,限制了3D模型在多样化空间和语义能力上的潜力,未能充分利用不同基础模型所 encapsulated的空间和语义特性。
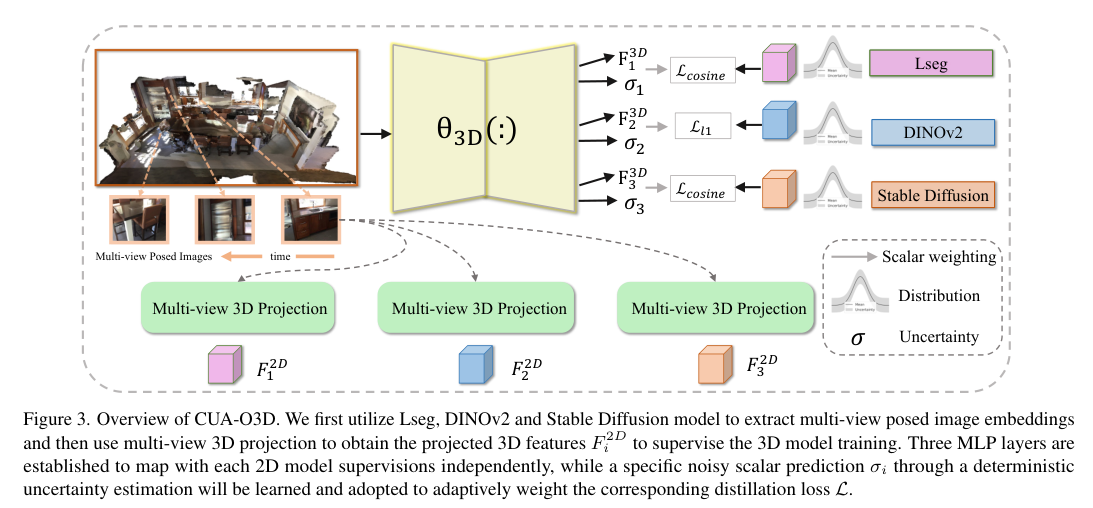
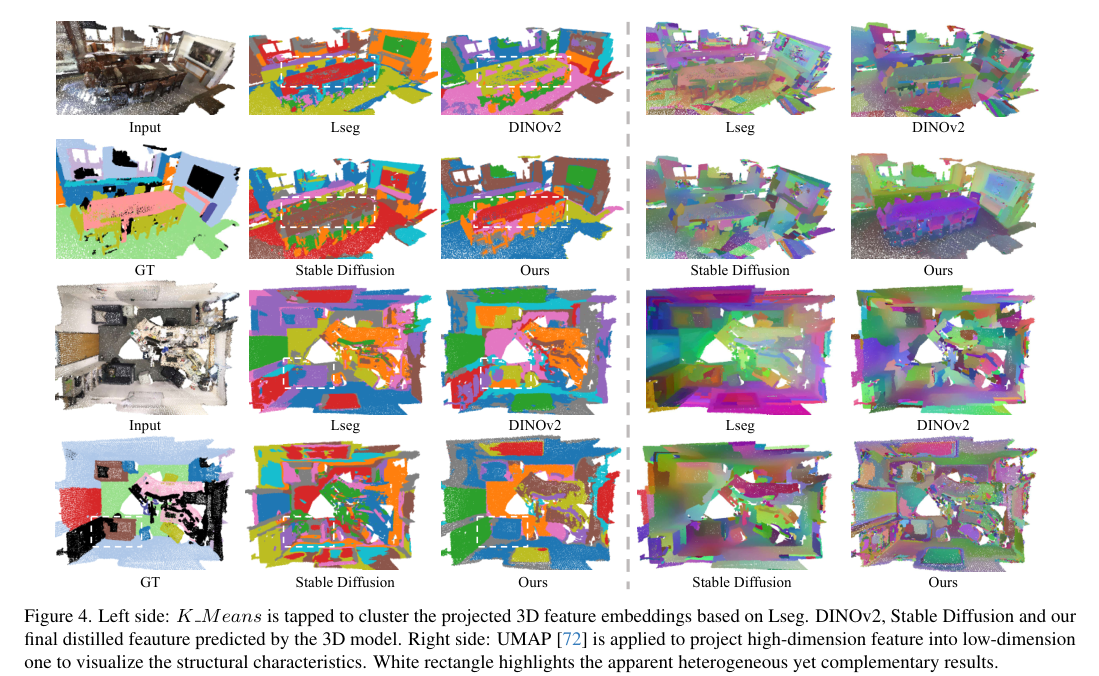
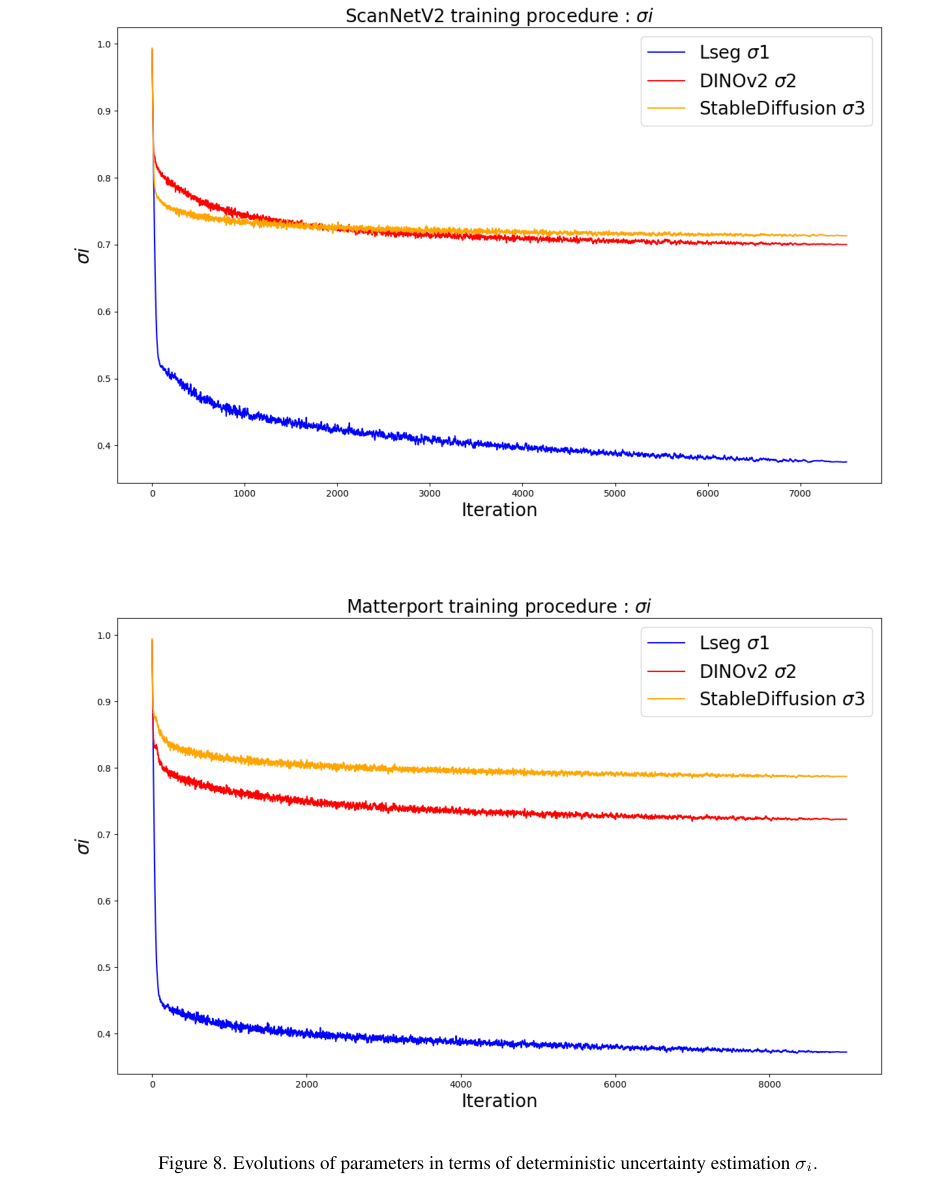
4)方法:为了克服这些挑战,提出了CUA-O3D方法,该方法是第一个将多个基础模型(如CLIP、DINOv2和Stable Diffusion)整合到3D场景理解中的模型。此外,还引入了确定性的不确定性估计方法,用于自适应地提炼和协调来自不同模型的异构2D特征嵌入。该方法解决了两个关键问题:(1)将VLM中的语义先验与空间感知视觉基础模型的几何知识结合,(2)通过创新的确定性不确定性估计,捕捉不同模型在语义和几何敏感度上的特定不确定性,帮助在训练过程中协调异构表示。
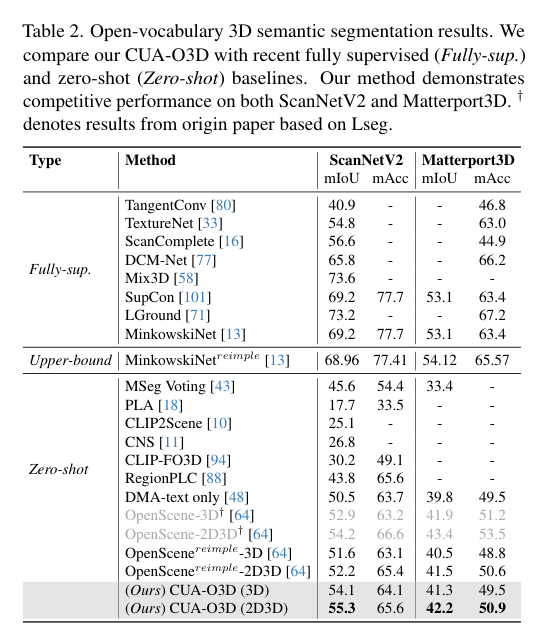
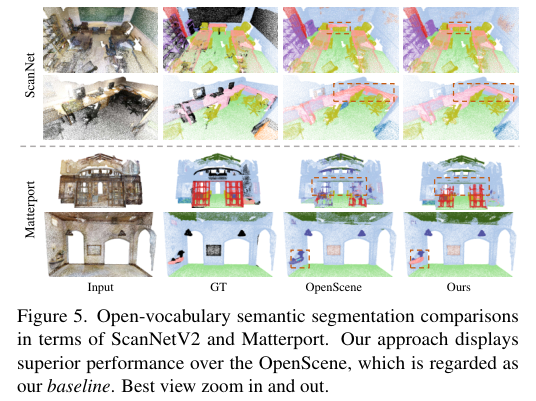
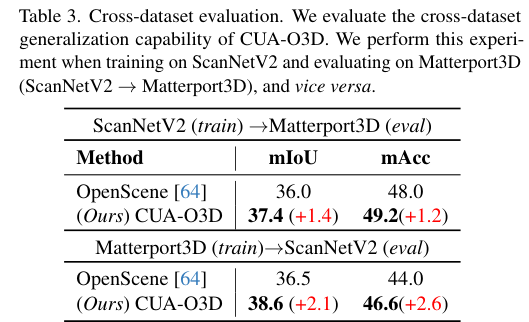
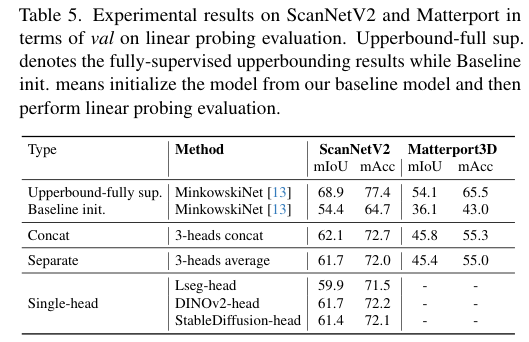
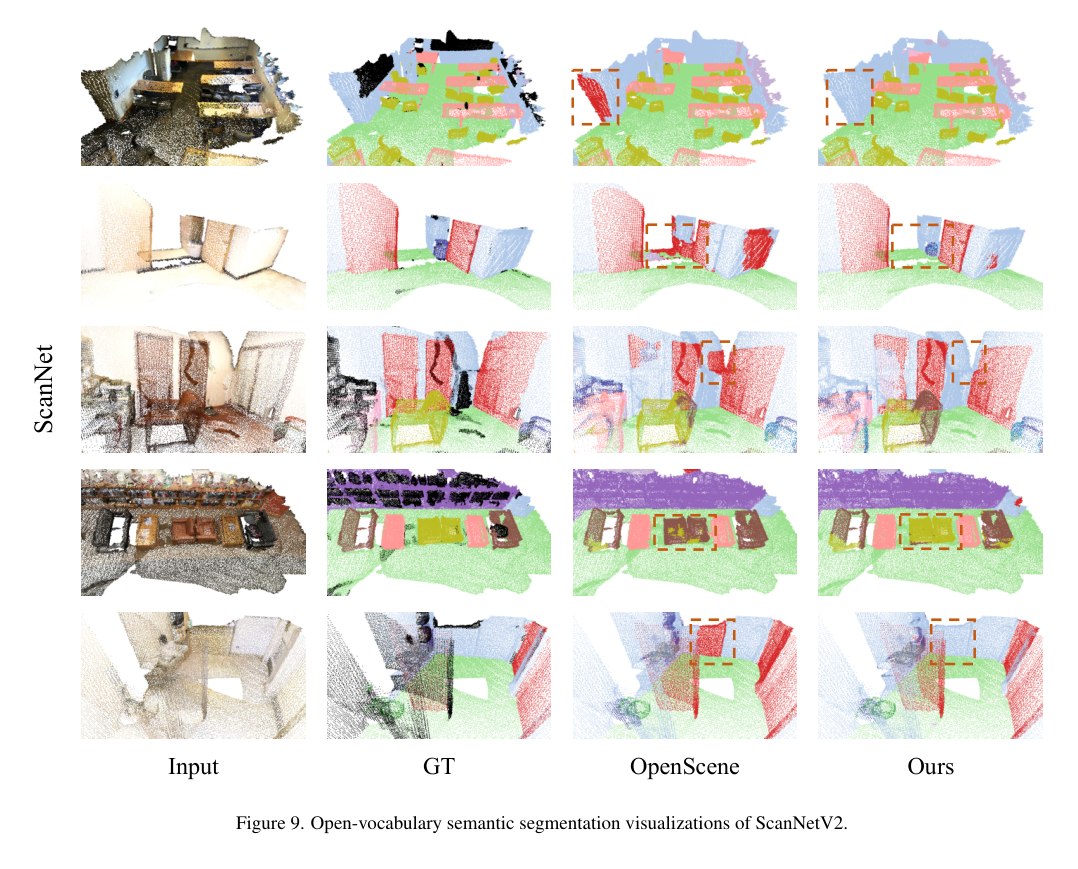
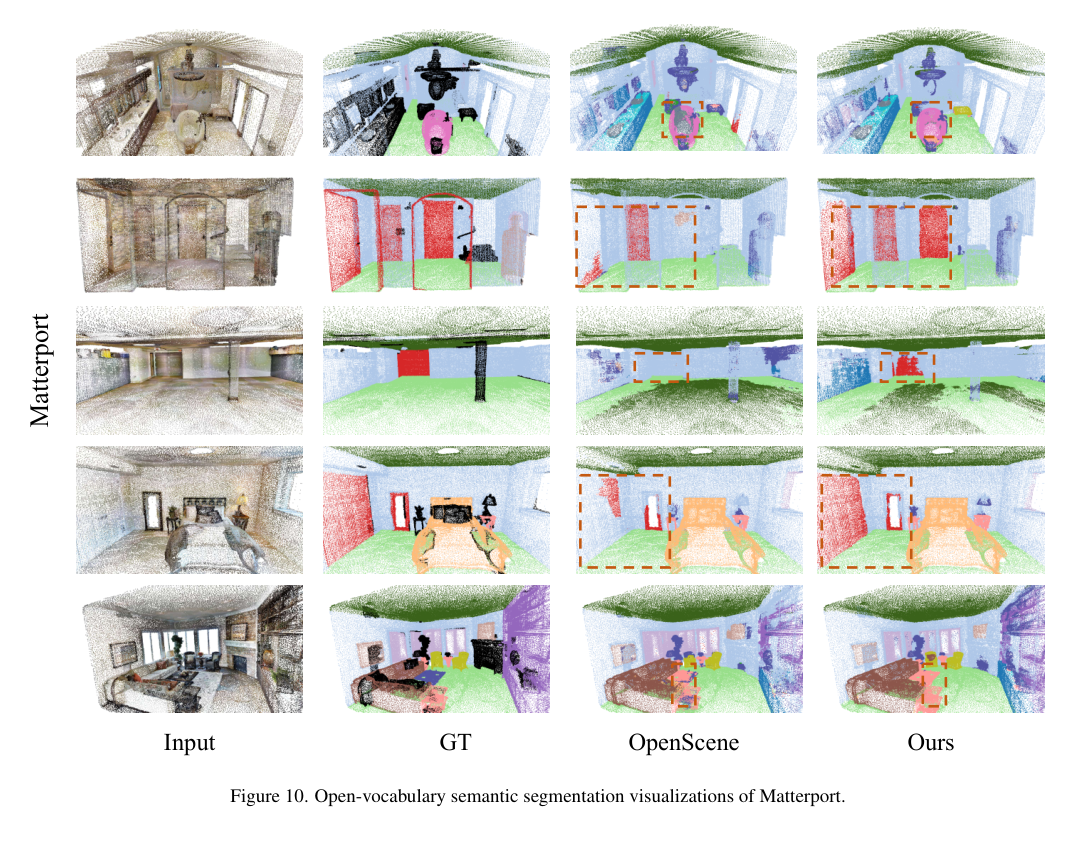
5)结果:在ScanNetV2和Matterport3D数据集上的广泛实验结果表明,该方法不仅在开词汇分割上取得了进展,还实现了稳健的跨领域对齐和具有竞争力的空间感知能力,展示了其在3D场景理解中的优势和创新性。代码:https://github.com/TyroneLi/CUA_O3D





























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











