







论文作者:Shiyuan Yang,Zheng Gu,Liang Hou,Xin Tao,Pengfei Wan,Xiaodong Chen,Jing Liao
作者单位:City University of Hong Kong ;Tianjin University;Shenzhen University;Kuaishou Technology;
论文链接:http://arxiv.org/abs/2503.11412v1
项目链接:https://mtv-inpaint.github.io/
内容简介:
1)方向:视频修复
2)应用:视频修复
3)背景:现有的视频修复方法大多集中在场景补全(即填补缺失区域),而无法在可控的方式下向场景中插入新对象。尽管最近文本到视频(T2V)扩散模型取得了进展,但直接应用T2V模型进行修复存在完成与插入任务无法统一、缺乏输入可控性及无法处理长视频等问题,限制了其应用和灵活性。
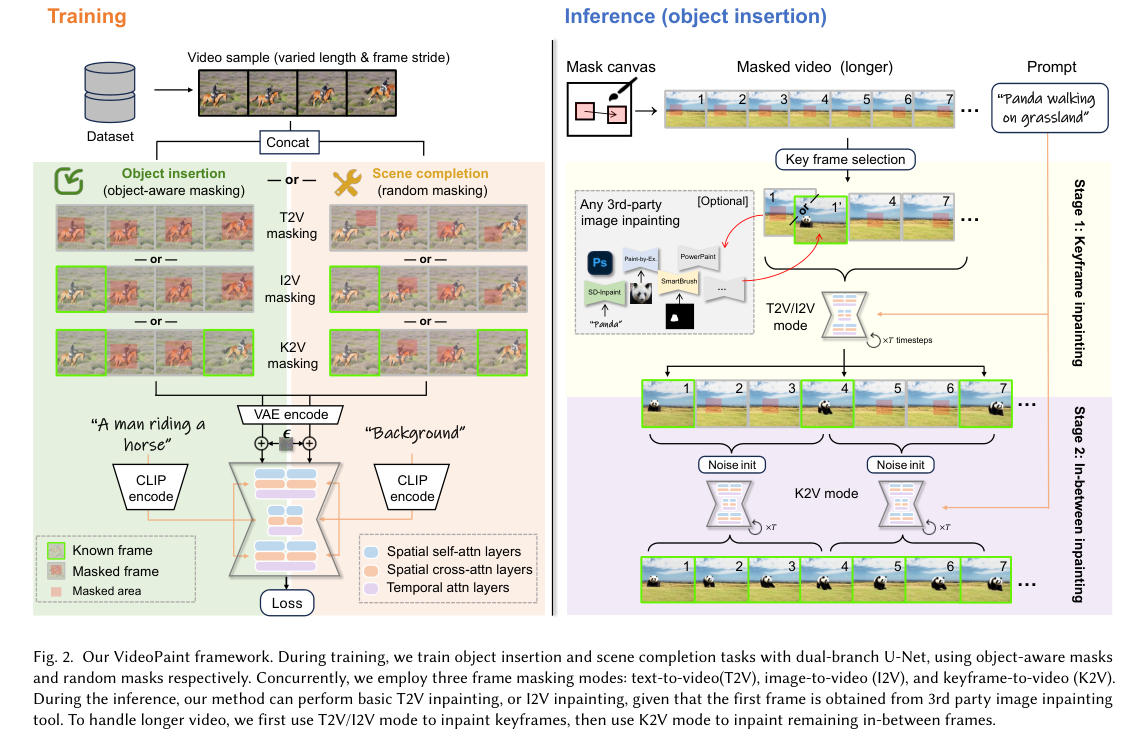
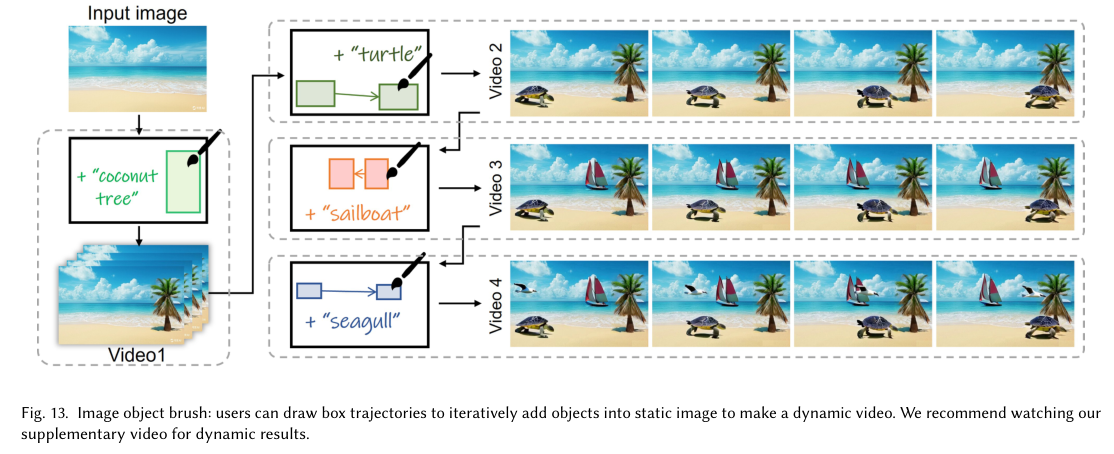
4)方法:本文提出了MTV-Inpaint,一个统一的多任务视频修复框架,能够处理传统的场景补全任务以及新对象插入任务。MTV-Inpaint采用了双分支空间注意力机制,集成了T2V扩散U-Net模型,能够无缝地在单一框架中同时进行场景补全和对象插入。此外,MTV-Inpaint支持通过我们提出的图像到视频(I2V)修复模式,结合多种图像修复模型进行多模态控制。框架还采用了两阶段流水线,将关键帧修复与帧间传播结合起来,能够有效处理包含数百帧的长视频。
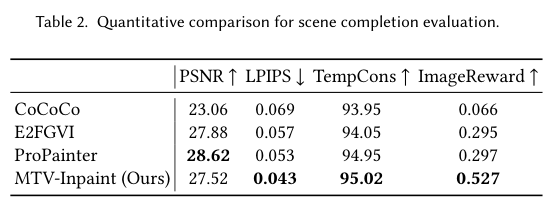
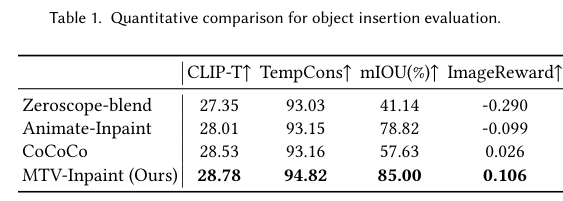
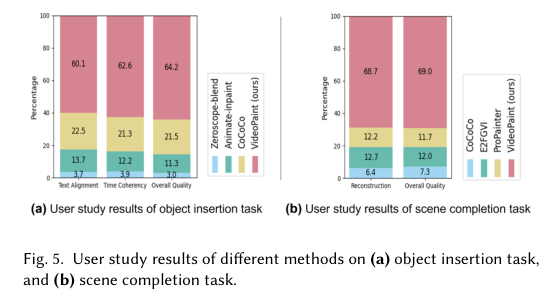
5)结果:通过大量实验验证,MTV-Inpaint在场景补全和对象插入任务中取得了最先进的性能。此外,MTV-Inpaint在多模态修复、对象编辑、移除、图像对象刷等派生应用中展示了出色的多功能性,并能够处理长视频。






























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











