




作者:余天予,清华大学博士生
原文:https://mp.weixin.qq.com/s/xy3ghQydsR-fe4NkNnD3KQ
加入青稞AI技术交流群,与青年AI研究员/开发者交流最新AI技术
Deepseek 的R1、OpenAI 的o1/o3等推理模型的出色表现充分展现了RLVR(Reinforcement Learning with Verifiable Reward,基于可验证奖励的强化学习)的巨大潜力。
然而,现有方法的应用范围局限于数学和代码等少数领域。面对自然语言固有的丰富多样性,依赖规则验证器的方法难以拓展到通用领域上。
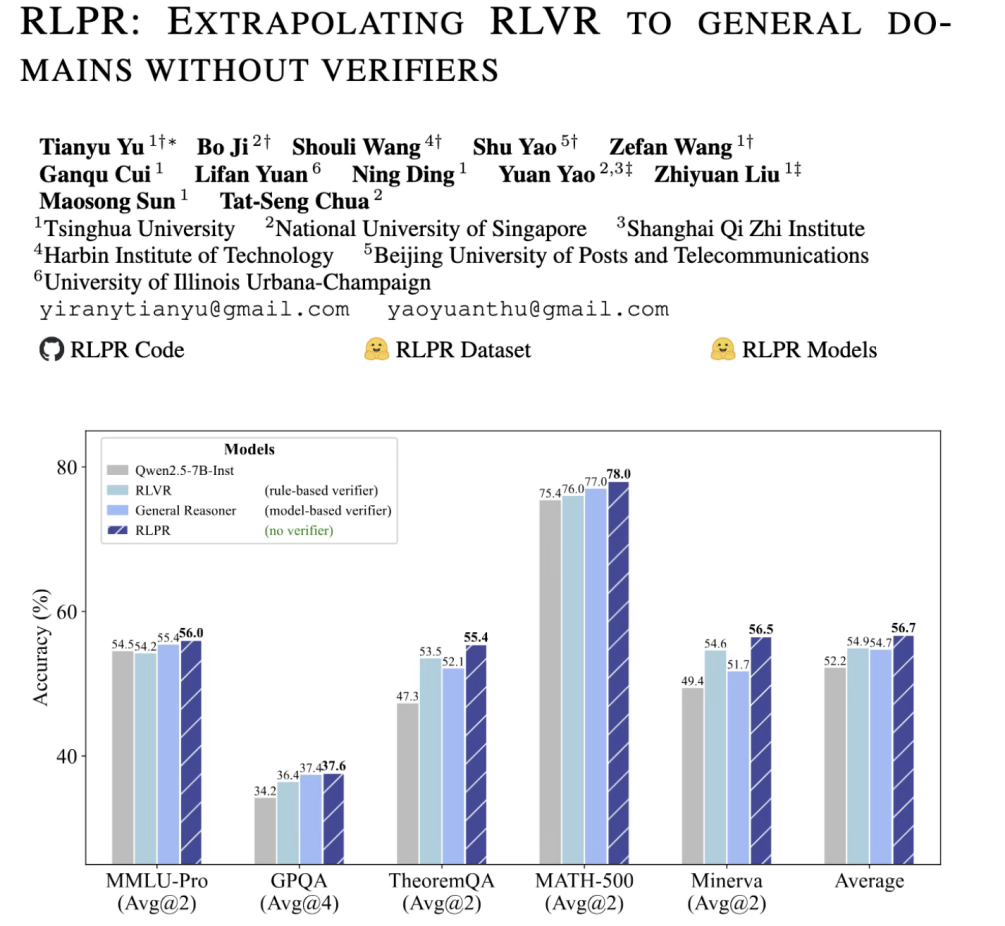
针对这一关键挑战,清华大学自然语言处理实验室提出了一项关键性技术——基于参考概率奖励的强化学习(Reinforcement Learning with Reference Probability Reward,RLPR)。
这项技术通过 Prob-to-Reward方法显著提高了概率奖励(Probability-based Reward,PR)的质量,相比基于似然度的基线方法取得了明显更佳的性能优势和训练稳定性。
同时,RLPR提出基于奖励标准差的动态过滤机制,进一步提升强化学习的稳定性和性能提升。目前 RLPR 相关代码、模型、数据、论文均已开源。
论文标题:RLPR: Extrapolating RLVR to General Domains without Verifiers
论文地址: https://github.com/OpenBMB/RLPR/blob/main/RLPR_paper.pdf
GitHub仓库:https://github.com/OpenBMB/RLPR
PR 为何有效?挖掘模型的内在评估
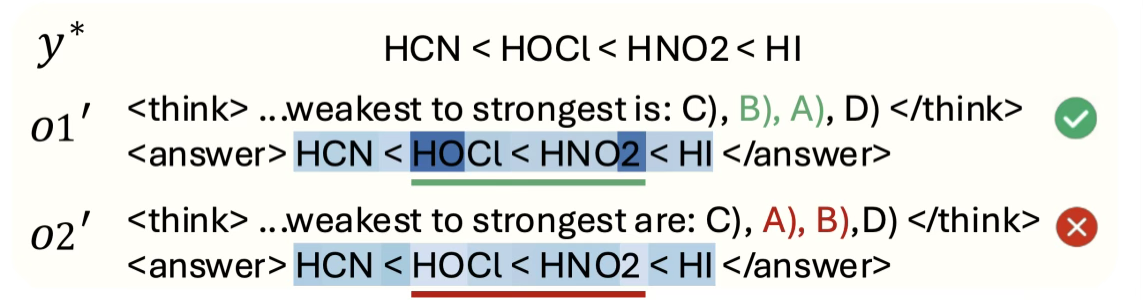
研究团队观察到,大语言模型(LLM)在推理过程中对于参考答案的生成概率直接反映了模型对于本次推理的质量评估。也就是说,模型的推理越正确,其生成参考答案的概通常就越高。
在论文中,研究团队给出了一个具体示例:当模型在输出 o2 中错误地把选项 A 排在了第二位时,可以观察到参考答案在第二个正确选项位置上的生成概率出现了显著下降。这一现象清晰地表明,PR能够精准捕捉模型对于自身推理质量的判断,并且与模型推理的正确性表现出高度相关性。
RLPR 核心特点
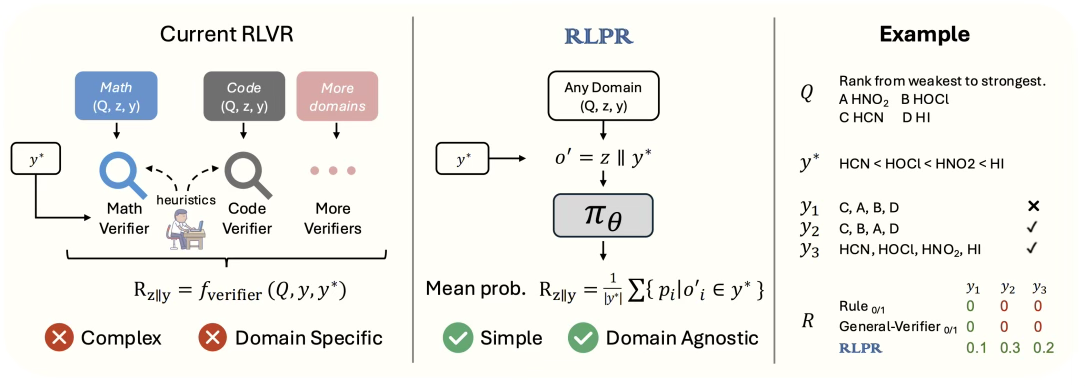
领域无关的高效奖励生成
现有 RLVR 方法通常需要投入大量的人力和工程资源,为每个领域编写特定的验证规则,相比之下,RLPR仅需要简单的一次前向传播(forward pass)就可以生成奖励分数。通过使用参考答案的生成概率均值作为奖励。这种方法能够有效地应对自然语言固有的复杂多样性。
如下图所示(右侧示例),基于规则匹配的方式无法识别出 y2 和 y3 和参考答案语义等价,而RLPR的 PR 机制准确地给予了这两个答案更高的分数。
奖励纠偏和动态过滤
基础的 PR 已经呈现出和回答质量很高的相关性,但是仍然受到问题和参考答案风格等无关因素的干扰(即存在偏差)。为此,研究团队提出构建一个不包含思维链过程(z) 的对照奖励,并通过做差的方式去除无关因素对于分数的影响,实现奖励纠偏。
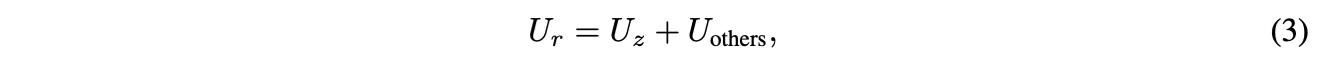
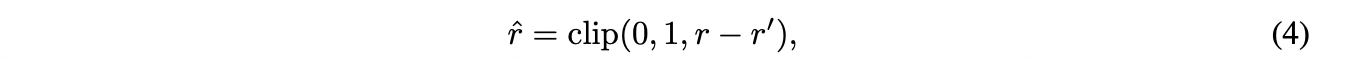
传统基于准确率(Accuracy Filtering)的样本过滤方法难以适用于连续的 PR 值。RLPR提出基于奖励标准差的动态过滤机制,保留那些取得较高奖励标准差的样本用于训练,有效提升了训练的稳定性和效果。考虑到训练过程中奖励的标准差会持续变化,RLPR进一步采用指数移动平均(EMA)的方式持续动态更新过滤阈值。
可靠的奖励质量和框架鲁棒性
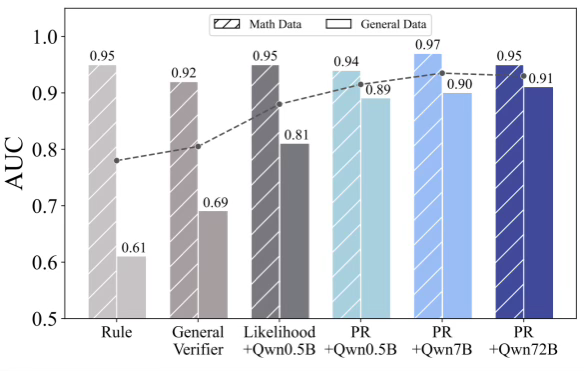
研究团队通过ROC-AUC指标定量评估了不同来源奖励的质量。结果表明,PR 在 0.5B 规模即取得了显著优于规则奖励和验证器模型奖励的质量。同时,通用领域奖励质量随着模型能力的增强可以进一步提高到0.91水平。
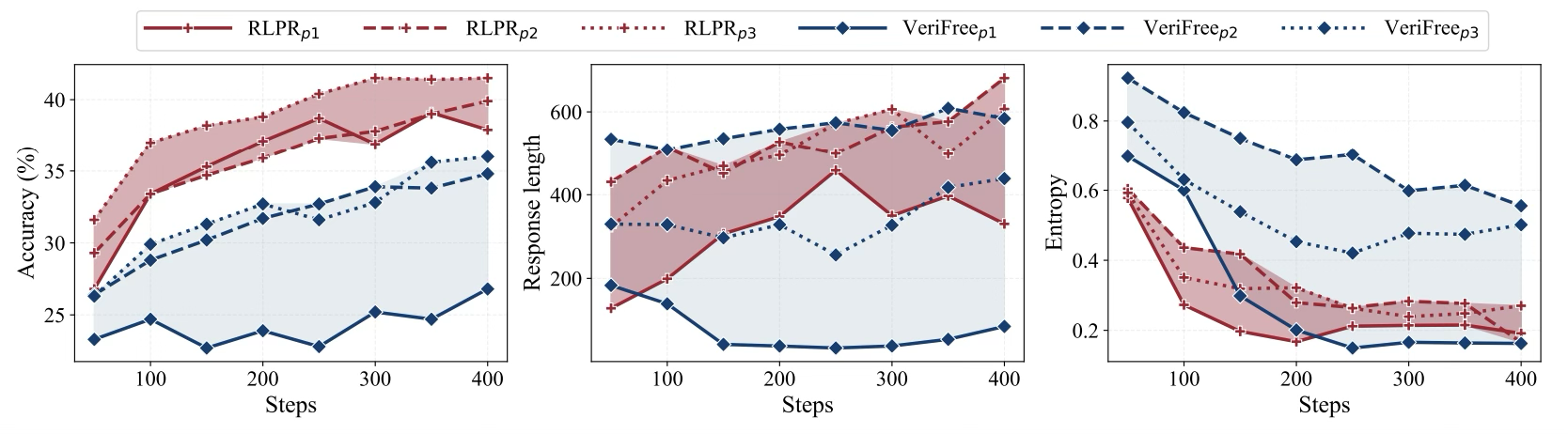
为了验证框架的鲁棒性,研究团队使用多种不同的训练模板结合 RLPR训练Qwen2.5 3B模型,并观察到RLPR在不同训练模板上都可以取得稳定的性能提升。
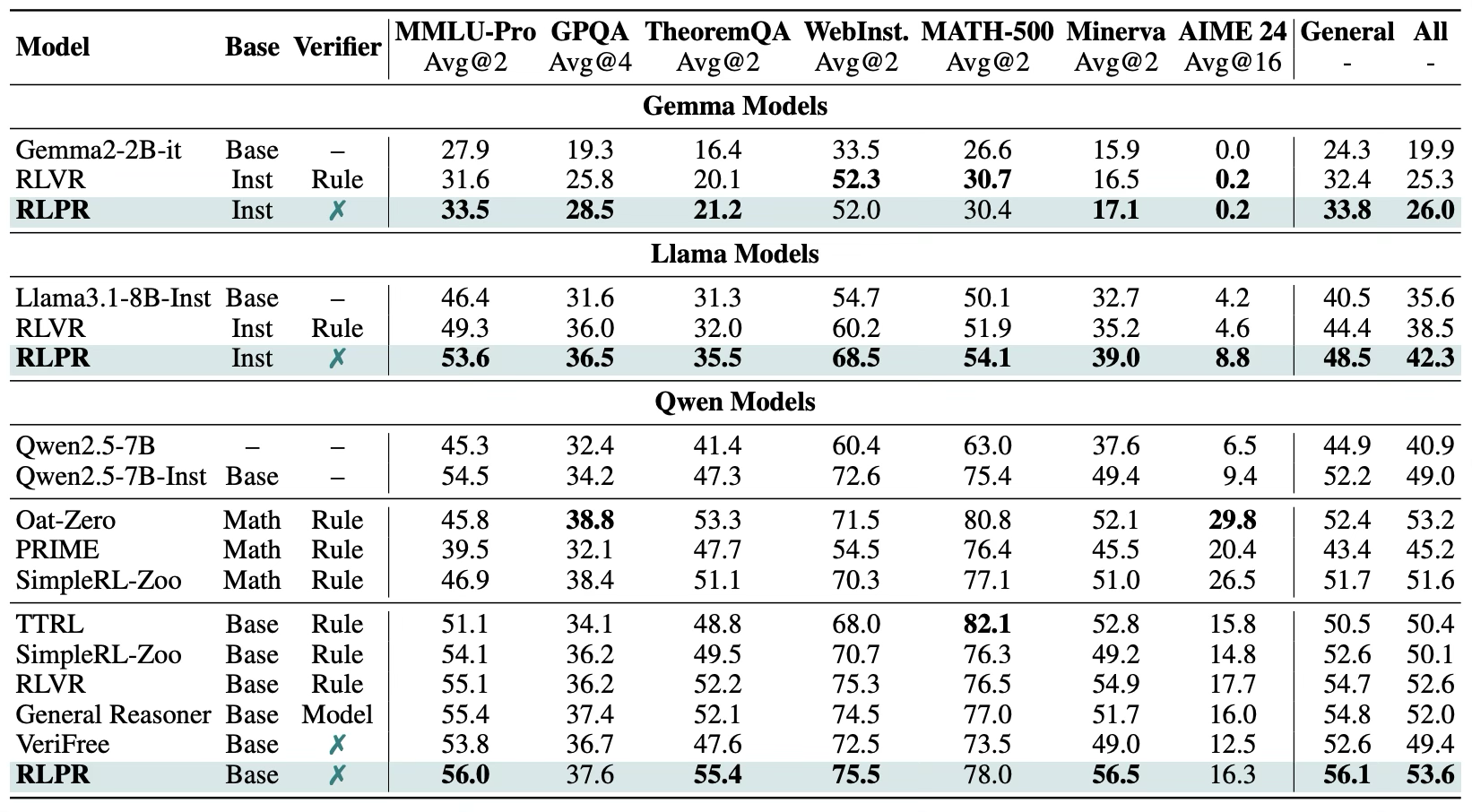
研究团队还进一步在 Gemma, Llama 等更多系列的基座模型上进行实验,验证 RLPR 框架对于不同基座模型均可以稳定提升模型的推理能力,并超过了使用规则奖励的RLVR基线。
总结
RLPR 提出了创新的 Prob-to-Reward奖励机制,解决了现有 RLVR范式的领域依赖问题。通过在 Gemma、Llama、Qwen 等主流模型系列上的广泛验证,RLPR 不仅证明了其卓越的有效性和相对于传统规则奖励的显著优势,更在推动强化学习(RL)向更大规模(scaling)发展的道路上,迈出了坚实而有力的一步。
更多研究细节,可参考原论文。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









