




观看地址:qingkelabs.github/io/talks
随着ChatGPT的流行,大语言模型(简称LLM)受到越来越多的关注。此类模式的出现,极大地提高了人们的工作效率。 然而,进一步广泛使用LLM的关键在于如何以低成本和高吞吐量地部署数十亿参数的模型。 为了提高大模型服务的吞吐量,让更多感兴趣的研究人员快速参与进来, 一种名为 LightLLM 的轻量级 LLM 推理服务框架应运而生。
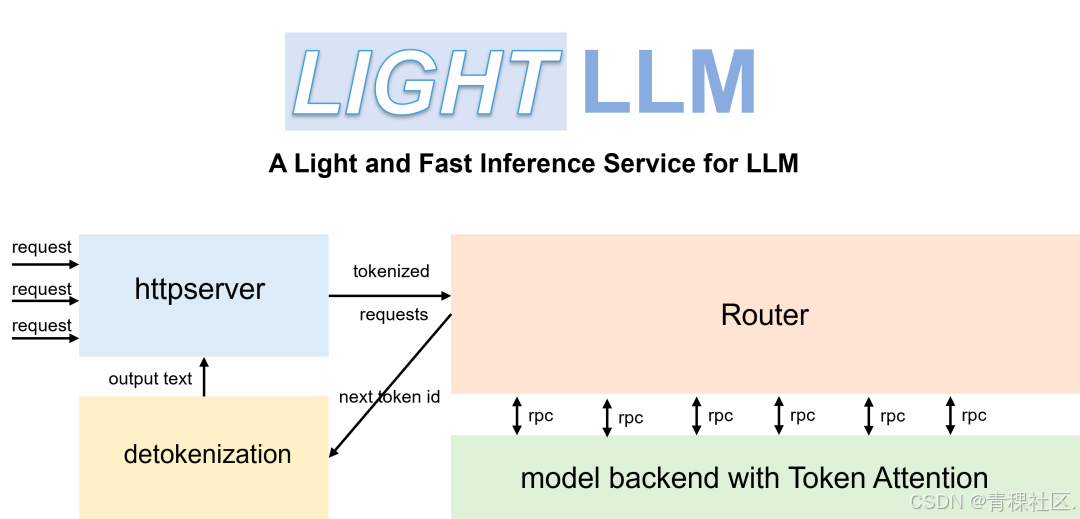
LightLLM 引入了一种更细粒度的kvCache管理算法,称为TokenAttention, 并设计了一个与TokenAttention高效配合的Efficient Router调度算法。 通过 TokenAttention 和 Efficient Router 的配合, LightLLM 在大多数场景下实现了比 vLLM 和 Text Generation Inference 更高的吞吐量, 甚至在某些情况下性能提升了 4 倍左右。
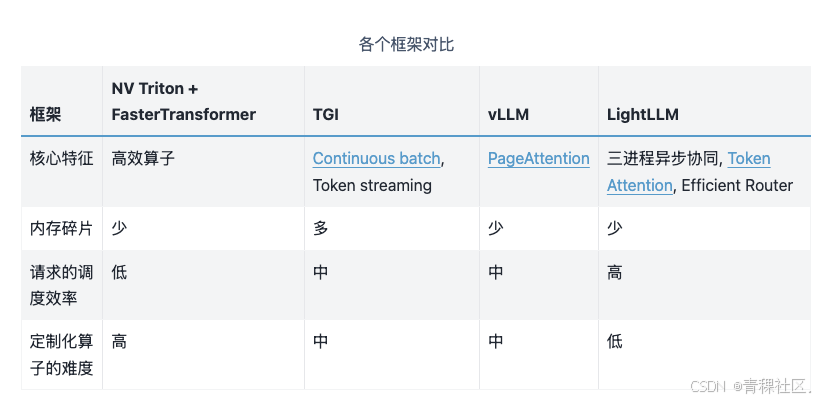
重要特性
-
多进程协同:分词、语言模型推理、视觉模型推理、分词等工作异步进行,大幅提高GPU利用率。
-
零填充:提供对跨多个模型的 nopad-Attention 计算的支持,以有效处理长度差异较大的请求。
-
动态批处理:能够对请求进行动态的批处理调度。
-
FlashAttention:结合 FlashAttention 来提高推理过程中的速度并减少 GPU 内存占用。
-
向量并行:利用多个 GPU 进行张量并行性从而加快推理速度。
-
Token Attention:实现了以token为单位的KV缓存内存管理机制,实现推理过程中内存零浪费。
-
高性能路由:结合Token Attention,对GPU内存以token为单位进行精致管理,优化系统吞吐量。
-
int8 KV Cache:该功能可以将最大token量提升解决两倍。现在只支持llama架构的模型。
LightLLM v1.0.0 的架构创新
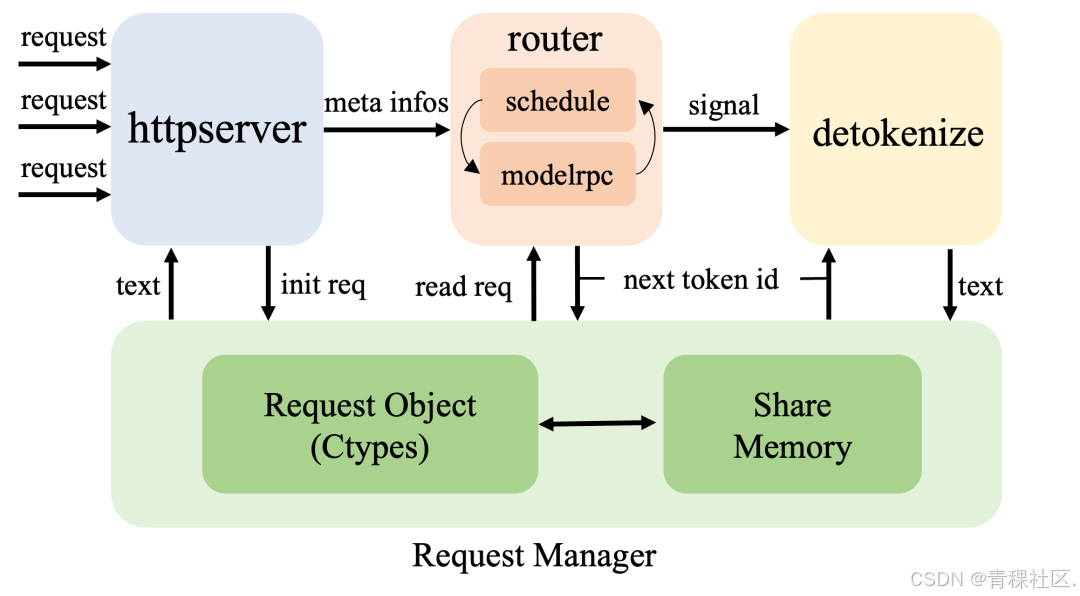
LightLLM 的新框架
跨进程请求对象
通过ctypes实现跨进程可访问的请求对象,显著降低高并发场景下的进程间通信开销。采用共享内存存储请求元数据,将必要数据传输量降至最低。
三进程架构演进
保留原有三进程设计,引入折叠式调度与模型推理机制,彻底消除旧版本路由层与模型RPC间的通信开销。
张量缓存管理器
新增CacheTensorManager类,统一管理Torch张量的分配与释放。实现运行时跨层张量共享,以及不同CUDA图之间的内存复用。实测表明,在8×80GB H100集群上,使用DeepSeek-v2模型可同时运行200个CUDA图而不会出现内存不足(OOM)。
DeepSeek 优化
LightLLM 针对 DeepSeek R1 进行了深度优化,在单机 H200 上达到了当前开源框架中的最佳性能。
由于 Prefill(计算密集型)和 Decode(内存密集型)的计算特性不同,LightLLM 对 DeepSeek MLA 进行了不同的优化。在 Prefill 阶段,LightLLM 解压缩 KV 缓存,而在 Decode 阶段,LightLLM 压缩查询(q)以实现最佳性能。此外,LightLLM 利用 OpenAI 的 Triton 实现了高性能 Decode MLA 和融合 MoE 内核。
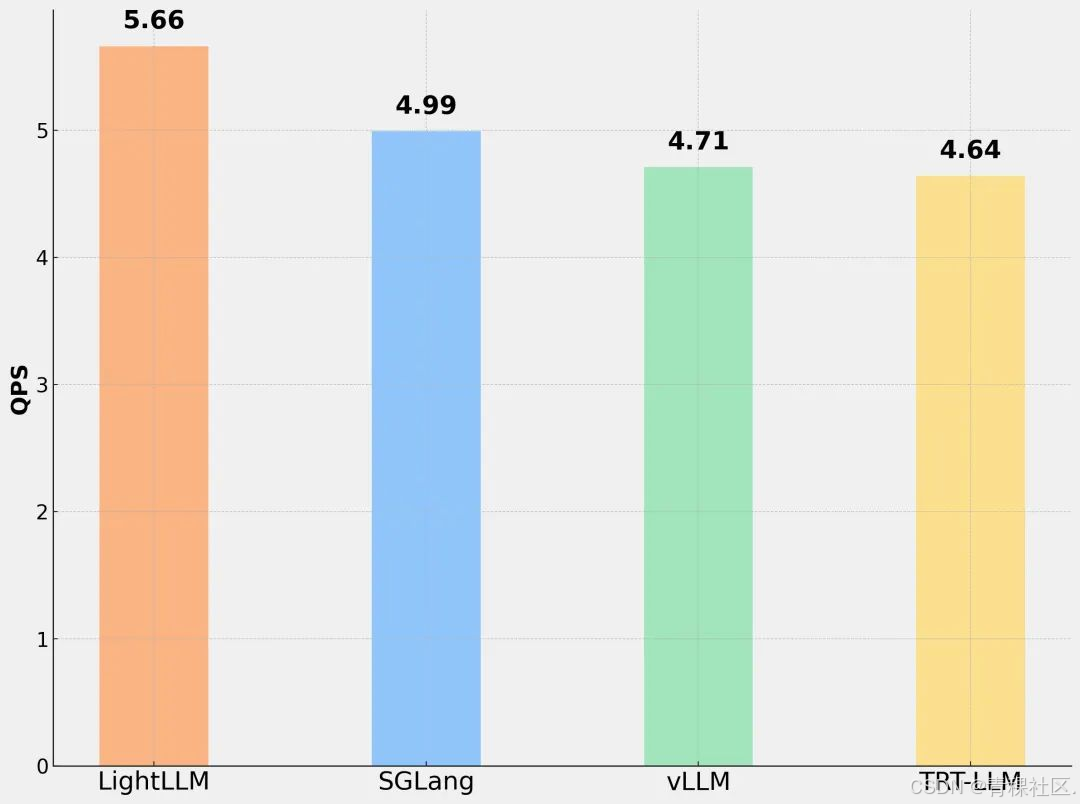
下图是LightLLM、sglang==0.4.3、vllm==0.7.2、trtllm==0.17.0在单机H200上的性能对比,使用DeepSeek-R1(num_clients = 100),测试数据输入长度为1024,输出服从均值为128的高斯分布,LightLLM取得了更好的性能。
3月8日上午11点,青稞Talk 第40期,商汤科技大模型工具体系团队研究员、LightLLM 核心开发人员白世豪,将直播分享《基于 LightLLM 的 DeepSeek R1/V3 模型部署实战》。
分享嘉宾
白世豪,商汤科技大模型工具体系团队研究员,LightLLM核心开发人员,主要负责大语言模型推理加速,探索更高效的大语言模型服务技术,在ASPLOS, IJCAI、AAAI、ICCV等期刊会议发表论文十篇。
主题提纲
基于 LightLLM 的 DeepSeek R1/V3 模型部署实战
1、LightLLM 框架及特性解读
2、PD 分离原型实现
3、针对 DeepSeek 系列模型的专项优化
4、DeepSeek R1/V3 部署实战
直播时间
3月8日(周六) 11:00 -12:00



















 2492
2492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









