




从DeepSeek-R1,聊聊过程奖励模型在强化学习中的挑战及隐式过程奖励模型PRIME
OpenAI o1 以及DeepSeek-R1 模型的发布证明了强化学习是通向高阶推理能力的必经之路,但开源社区对此还少有探索。使用PRM进行强化学习,其中有两个需要解决的关键问题:
-
• 如何高效、可扩展地获取精确奖励信号(尤其是密集奖励)?
-
• 如何构建有效的RL算法以充分释放这些信号潜力?
我们寻求通过高效的奖励建模和强化学习实现高级推理能力的可扩展途径。我们的工作源于隐式过程奖励建模 (PRM) 目标。无需任何过程标签,隐式 PRM 被训练为结果奖励模型 (ORM),然后用作 PRM。除了通过推理扩展提高模型性能外,隐式 PRM 的真正威力还在在线 RL 训练中得到展现。具体来说,它为 RL 带来了三个好处:
-
• 密集奖励:隐式PRM直接学习为每个token生成奖励的Q函数,无需额外价值模型即可缓解奖励稀疏性问题
-
• 可扩展性:仅需结果标签即可在线更新隐式PRM,通过带结果验证的在线策略轨迹直接更新PRM,有效缓解分布偏移与可扩展性限制
-
• 简洁性:隐式PRM本质即为语言模型,实践表明监督微调(SFT)模型本身即可作为优质初始PRM
在深入研究了强化学习来探索其关键算法设计和实现技术后,我们提出了基于可扩展过程奖励的在线强化学习方法 PRIME,通过implicit process reward成功解决了PRM在大模型强化学习中怎么用,怎么训,怎么扩展的三大本质问题,易用性和可扩展性极佳。

如上图所示,在 PRIME 中,策略模型和PRM都使用SFT模型进行初始化。对于每个RL迭代,策略模型首先生成输出。然后,隐式PRM和结果验证器对输出进行评分,隐式PRM在输出时通过结果奖励进行更新。最后,将结果奖励 和过程奖励 组合在一起,用于更新策略模型。
算法的伪代码如下:

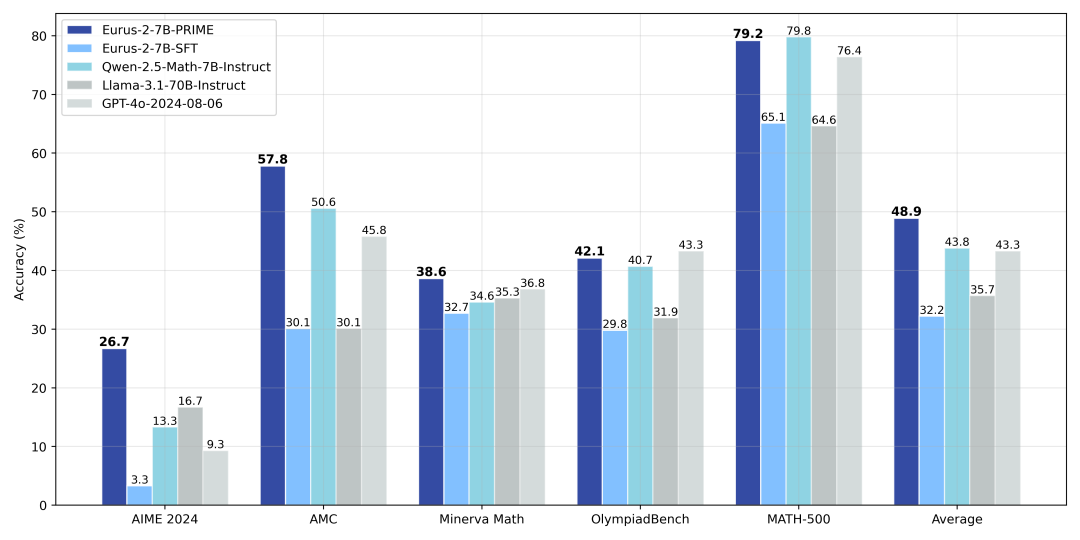
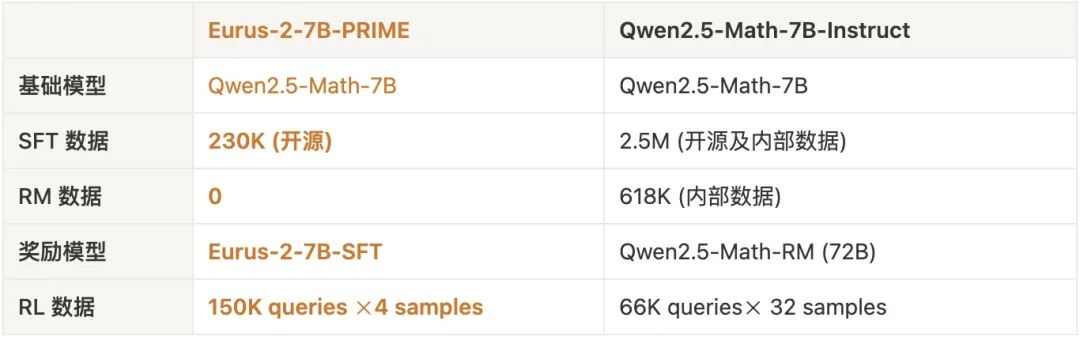
同时,从Qwen2.5-Math-7B-Base出发,我们还训练了Eurus-2,仅用 1/10于Qwen的开源数据,数学能力超过Llama3.1-70B, GPT-4o等大模型。其中,PRIME为模型带来了16.7%的绝对提升,远超我们已知的任何开源方案。
2月22日上午11点,青稞Talk 第39期,上海人工智能实验室青年科学家崔淦渠,将直播分享《PRIME: 结合隐式过程奖励的强化学习》。
分享嘉宾
崔淦渠,上海人工智能实验室青年科学家,博士毕业于清华大学计算机系,导师为刘知远副教授。研究方向为大语言模型的对齐与强化学习技术。在ICML, NeurIPS, ACL, KDD等国际人工智能顶级会议与期刊上发表论文十余篇,谷歌学术引用超9000次。
主题提纲
PRIME: 结合隐式过程奖励的强化学习
1、为什么强化学习是下一个 Scaling law
2、DeepSeek-R1:过程奖励模型在强化学习中的挑战
3、Implicit PRM与 PRIME 如何破局
成果链接
Paper:Process Reinforcement through Implicit Rewards
Abs:https://arxiv.org/pdf/2502.01456
Code:https://github.com/PRIME-RL/PRIME直播时间
2月22日(周六) 11:00 -12:00
参与方式
Talk 将在青稞·知识社区上进行,查看链接可以进行报名交流


















 1116
1116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









