




关注公众号:青稞AI,第一时间学习最新AI技术
🔥青稞Talk主页:qingkelab.github.io/talks
大语言模型(LLM)的最新进展以其卓越的涌现能力和推理能力推动我们走向通用人工智能。然而,大量的计算和内存要求限制了广泛采用。量化是一种关键的压缩技术,可以通过压缩和加速 LLM 来有效缓解这些需求,尽管存在潜在的准确性风险。许多研究的目的是尽量减少与量化相关的精度损失。然而,它们的量化配置各不相同,无法公平比较。

来自北航、商汤、南洋理工等团队联合推出的大模型压缩工具与基准LLMC,一个即插即用的压缩工具包,以公平、系统地探索量化的影响。 LLMC 集成了数十种算法、模型和硬件,提供了从整数到浮点量化、从 LLM 到视觉语言(VLM)模型、从固定位到混合精度、从量化到稀疏化的高度可扩展性。
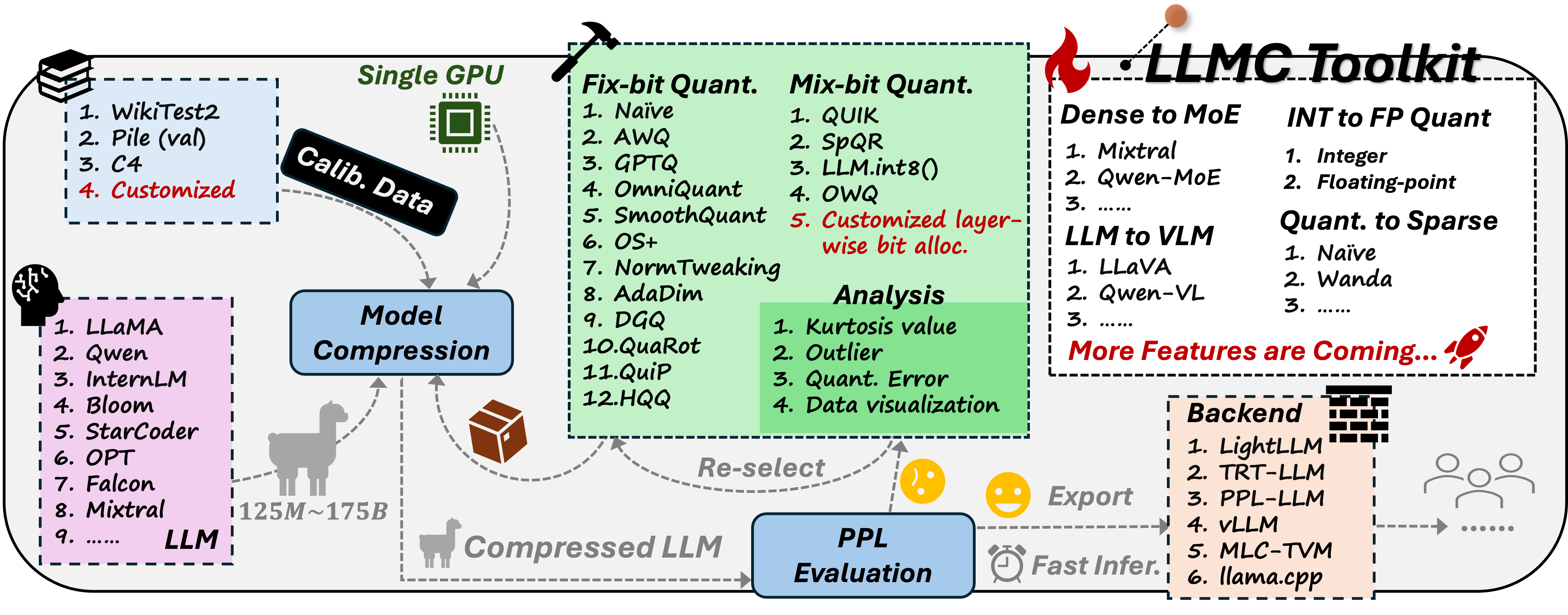
在这个多功能工具包的支持下,LLMC 基准测试涵盖了三个关键方面:校准数据、算法(三种策略)和数据格式,为用户的进一步研究和实践指导提供了新颖的见解和详细的分析。在使用 LLMC 对Llama 3.1进行量化压缩后,可以使得一张80G A100即可完成 Llama 3.1 405B 的校准和评估,从而实现以超低成本进行量化。
LLMC已开源,欢迎大家Star!
https://github.com/ModelTC/llmc
10月11日晚7点,青稞Talk 第25期,商汤科技算法实习生、香港科技大学准博士生黄雨石,将直播分享《LLMC:大语言模型的量化基准》。
Talk 信息
主讲嘉宾
黄雨石,本科毕业于北京航空航天大学,即将进入香港科技大学攻读计算机博士学位。研究方向为高效的AIGC模型,神经网络压缩与加速等,目前已在CVPR, EMNLP, ACM MM发表多篇论文。
主题提纲
LLMC:大语言模型的量化基准
1、大语言模型量化技术概述
2、大模型压缩工具 LLMC
3、基于 LLMC 的量化基准测试
- 校准数据
- 算法(三种策略)
- 数据格式
直播时间
10月11日(周五)19:00 - 20:00
参与方式
Talk 将在青稞·知识社区上进行,可以添加【ai_qingke113】对暗号:" 1011 ",报名进群!


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









