








👉目录
1 MCP 是什么?
2 从 API、LSP 到 MCP
3 MCP之前:各自为战的 AI 发展
4 MCP之后:标准化的 AI 发展
5 基础架构
6 核心架构
7 总结
本文系统性地介绍了MCP(Model Context Protocol)协议的设计理念、核心架构及技术实现,旨在通过标准化AI大模型与外部系统的交互方式,解决大模型工具调用和实时信息获取的行业痛点。文章通过对比API、LSP等历史协议,深入解析了MCP协议的三大核心组件与创新传输机制,并对协议的未来发展进行展望。
关注腾讯云开发者,一手技术干货提前解锁👇
鹅厂程序员面对面直播继续,每周将邀请鹅厂明星技术大咖讲解 AI 时代下的“程序员护城河”。更有蛇年公仔等精美周边等你来拿,记得提前预约直播~👇
01
MCP 是什么?
TL;DR
MCP协议的背后动机:现如今模型的能力很大程度上取决于使用者所提供的上下文,而过往大家在使用模型的时候,不管是通过 APP 还是通过 Chatbox 的形式来使用,需要频繁的复制/粘贴(果然键盘只需要ctrl c v三个按键就足够了~),基于此 MCP 协议应运而生~
MCP 解决了使用大模型的痛点:大模型只知道训练时学到的静态知识,无法获取动态的实时信息或执行具体的操作。
换句话说,AI 大模型是一位学识渊博但是光说不做的博士,他不会上网,不会使用工具,只能根据已有的知识来回答问题。
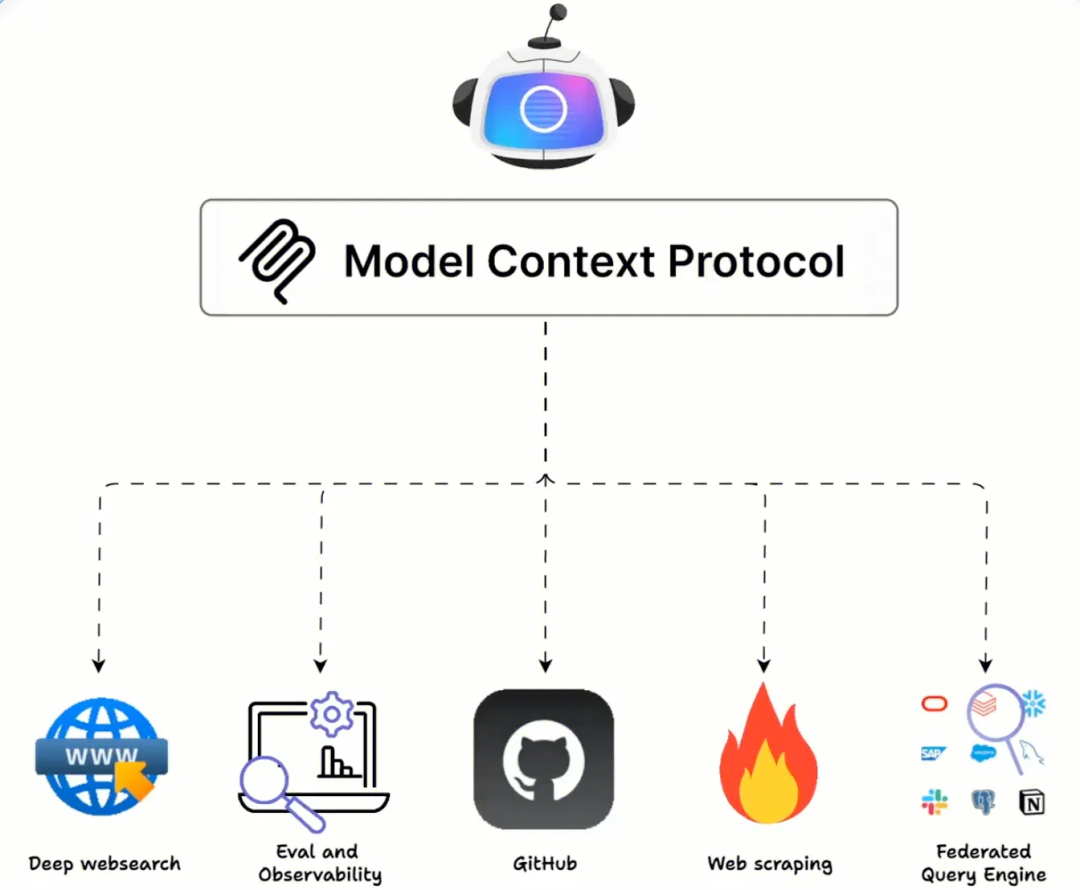
而MCP协议做的事情就是:告诉AI大模型有哪些工具(tools)和资源(resources)可以使用,以怎么样的工作流/提示(prompts)来使用,以通用统一协议的方式将AI大模型和外界进行连接(这也就是将其比喻为大模型USB通用接口的由来)。
02
从 API、LSP 到 MCP

要理解一个新的协议,可以思考它之前的协议和系统是如何工作的。
API(Application Program Interface,应用程序接口)
在远古的时代,工程师们为了标准化Web应用程序在前端和后端之间的交互方式,于是定义了一种前后端交互的协议,也就是API协议,即应用程序编程接口。API 可以将来自后端的请求转换为前端可以使用的数据,反过来也可以将前端的数据传输给后端。
API使得前端可以访问服务器、数据库和服务等内容。
LSP(Language Server Protocol,语言服务器协议)
直到2016年,LSP协议出现了,它标准化了IDE和开发工具之间使用的协议,提供了例如自动完成、转到定义、查找引用和查找实现这些IDE功能的统一通讯协议。
在LSP协议出现之前,各家IDE提供给用户的代码编辑功能(编辑文件、查找引用、工作区操作等),还有IDE的响应(自动补全、代码诊断等)这些功能的API都各不相同,乱的一批。
于是微软将上述这些IDE的功能都抽象为一系列的 行为事件,也就是LSP协议,使得兼容LSP的IDE去连接,并找出与编程语言的不同功能进行交互的方式。
比如在写一个GO微服务时,任何兼容LSP的IDE都可以连接到在GO编码时所有有关于GO的内容,这样IDE不再需要关心如何实现代码诊断,只需要关注如何在IDE界面上发起或响应 LSP 规定的行为事件即可。
MCP(Model Context Protocol,模型上下文协议)
而到了2024年11月底,Anthropic 推出了一种开放标准,即 MCP 协议,它标准化了 AI 应用程序与外部系统的交互方式,它通过三种主要方式和作为协议一部分的三个接口来实现,这三个接口分别是 prompt(提示)、tools(工具)和 resources(资源)。
03
MCP之前:各自为战的 AI 发展

在没有 MCP 协议之前,各家的 AI 产品在构建 AI 系统这一事情上并没有一个共识。每个团队会创建一个 AI 应用,他们通过自定义的方式连接到他们的上下文,这个自定义方式使用了他们自己的的提示逻辑,并使用不同的方式来引入工具和资源,然后以不同的方式协同访问这些工具和数据。如果一家公司内有多个团队,每个团队有自己的一套自定义的方式,那么可以想象整个行业也是这么做的,这就存在成百上千个自定义协议。
这就好比过去充电协议未统一时(虽然现在也还没有统一),管理各式各样的充电设备、充电协议、充电标准真的是很头疼的一件事。
04
MCP之后:标准化的 AI 发展

而现在有了MCP,模型可以和数据、文件系统、开发工具、Web 和浏览器自动化、生产力和通信、各种社区生态能力集成,实现协作工作能力。 而最大的优点在于:MCP 是开放标准,有利于服务商开发 API,避免重复造轮子,各家有了一个共识来使用一套标准来构建各自的产品,而后也为这些产品之间的联动打下了基础(这也是谷歌推出A2A协议想做的事)。
05
基础架构
说了这么多的概念,接下来该深入了解一些 MCP 协议的使用方式和核心架构了。
5.1 MCP 应用架构

上图是使用 MCP 协议构建一个完整应用的视图,可以看到包含一个 MCP Client(客户端)、一个 MCP Server(服务端),以及三个核心接口,接下来简要介绍一下它们。
客户端:MCP Client
MCP 客户端的作用是通过调用工具来查询资源,然后将相应的提示词嵌入其中,用模型相关的上下文来填充到提示词中。
服务端:MCP Server
MCP 服务端的作用是以任何客户端可以使用的方式,将工具、资源和提示词公开暴露给客户端,以供客户端选择调用。
“暴露”可以类比于是传统服务端,将自己的 IP:PORT 暴露出去,以待客户端连接。
工具:Tools
工具可能是大家在使用 MCP 服务的时候最常用的。在 Anthropic 官网是这么介绍的:Enable LLMs to perform actions through your server。很好理解,通过工具,LLM 可以与外部系统交互、执行计算并执行操作。这就解决了之前提到的大模型的痛点:无法执行具体的操作。
工具是由模型控制的,也就是说 MCP 服务端将工具公开暴露给 MCP 客户端中的模型,并由模型决定什么时候该调用这些工具。 所以工具的工作流程是这样的:
客户端向服务端询问有哪些工具。
服务端将工具的描述和使用方式返回给客户端。
接着客户端将工具的使用方式嵌入到提示词中,相当于告诉模型:你有这些工具可以使用,这些工具能做什么事,你该如何使用这些工具来更好的解决问题。
由模型决定什么时候使用工具。
资源:Resources
资源是提供给应用的数据,在 Anthropic 官网是这么介绍的:Expose data and content from your servers to LLMs。也很好理解,资源允许服务端提供给客户端可以获取的数据和内容,并将其作用于 LLM 的上下文。
资源是由应用控制的,客户端的应用来决定什么时候和如何使用资源。不同的 MCP 客户端会以不同的方式处理资源。在这之前,使用者大多时候都是通过复制粘贴、上传附件将资源提供给模型。而现在,资源为应用和服务端提供了一个交互接口来轻松地获取资源。
比如在安装各类 AI 应用时(如 Cursor、Cherry Studio、Cline等),应用会获取本机的一些信息(如操作系统、内核版本等),以便后续提供给模型,让模型更好的解决问题。
相比于工具 tools,目前并不是所有的第三方 MCP 客户端都支持资源的使用,这一点可以在 Anthropic 官方文档上看到各家 AI 产品对于 MCP 协议的支持情况:https://modelcontextprotocol.io/clients#feature-support-matrix (该表格有段时间没有更新了)
提示:Prompts
提示词相信大家并不陌生,毕竟大家都是提示词工程师~ 在 Anthropic 官网是这么介绍的:Create reusable prompt templates and workflows。在这之前不少用户已经这么做了,而 MCP 则是为这些可重复使用的提示模板和工作流程提供了一种方法来标准化和共享常见的模型交互提示词。
不难看出,提示词是由用户控制的,用户可以预定义一些提示词模板,用于与特定服务进行交互。
实际上很多 AI 应用在这一点上做得很好,比如各家产品的 @ 功能相信大家都并不陌生,当大家在@一个文档、网站、图片的时候,AI 应用会根据@的对象来使用相应的内置好的提示词模板,这里贴一个片段大家感受一下:
你以迭代方式完成给定任务,将其分解为清晰的步骤并有条不紊地完成它们。
分析用户的任务并设定明确、可实现的目标来完成它。按逻辑顺序排列这些目标的优先级。
按顺序完成这些目标,根据需要一次使用一个可用工具。每个目标应对应于你解决问题过程中的一个不同步骤。你将在进行过程中被告知已完成的工作和剩余的工作。
请记住,你拥有广泛的能力,可以访问各种工具,可以根据需要以强大而巧妙的方式使用这些工具来完成每个目标。在调用工具之前,在 <thinking></thinking> 标签内进行一些分析。首先,分析 environment_details 中提供的文件结构以获取上下文和见解,以便有效地进行。然后,考虑提供的工具中哪一个最适合完成用户的任务。接下来,检查相关工具的每个必需参数,并确定用户是否直接提供或给出了足够的信息来推断值。在决定是否可以推断参数时,请仔细考虑所有上下文,看看它是否支持特定值。如果所有必需参数都存在或可以合理推断,请关闭思考标签并继续使用工具。但是,如果缺少必需参数的值,则不要调用该工具(即使使用填充符填充缺失的参数),而是使用 ask_followup_question 工具要求用户提供缺失的参数。如果未提供可选参数,请勿索取更多信息。
完成用户任务后,必须使用 attempt_completion 工具向用户展示任务结果。你还可以提供一个 CLI 命令来展示你的任务结果;这对于 Web 开发任务尤其有用,例如你可以运行
open index.html用户可能会提供反馈,你可以利用这些反馈进行改进并重试。但不要进行毫无意义的来回对话,即不要以问题或提供进一步帮助的提议结束你的响应。
5.2 BETA 功能
除了上述内容,实际上 MCP 协议的作者还提供了 MCP 协议另一些功能,只不过对于这些功能的探索还处于早期阶段,目前大多数客户端都还没有支持这些功能,我称其为 MCP 的 BETA 功能,我们不妨一起来看看。
采样:Sampling
这个词第一眼会感到困惑,没关系我们来慢慢理解。无论是在网络协议、数据分析还是监控系统中,采样一般都代表“有选择性地收集部分数据”的过程。而 MCP 协议的采样功能是允许 MCP 服务端向客户端请求模型的生成结果,然后从结果中进行采样,进而实现复杂的功能。
在很多时候,实际上用户并没有将足够的上下文传递给服务端,让服务端去请求更多的信息。服务端可以使用不同的参数来向客户端请求模型(比如请求一个大模型还是小模型、模型的温度等),客户端收到采样请求后可以根据请求来直接通过调用,或者是修改请求内容甚至拒绝请求调用(可以预想到这是一个服务端向客户端发起的功能,可能会存在恶意调用)。请求模型调用完成后,客户端会对请求获得的上下文进行采样,然后发送回服务端,服务端因此获得了足够的信息。
采样这个功能实际给服务端开发者节省了很多事情,使得服务端本身不需要实现与模型之间的交互,也不需要托管模型,服务端可以通过采样来通过客户端来请求模型。
信息引导请求:Elicitations
采样 Sampling 能让服务端来采样模型,而 Elicitations 允许服务端通过客户端向用户请求补充信息,比如关键操作的确认、背景信息收集、决策选择等,相当于支持服务端采样用户了。
命名空间:Namespacing
可以想象一个场景,未来各家 MCP 服务提供商不可避免的会有一些命名上的冲突,比如工具名可能会一样,也许他们提供的功能内容上会有些许差异,但是这可能会造成冲突。
比如你希望模型调用的是 A 公司的 SayHello 工具,而模型调用的却是 B 公司的 SayHello 工具,这就引起困惑了,造成了二义性。目前暂时没有很好的方式来区分,一个解决方式是在服务端和工具名称之前加上前缀,例如 A - SayHello,不过作者还是希望这种机制能够成为协议中的一等公民。
注册中心:MCP Registry
随着MCP服务的生态体系日趋丰富,那么就需要一套统一的服务治理方案,MCP 服务注册中心就为此提供了一个很好的思路。MCP 注册服务为 MCP 服务器提供了一个集中式服务存储库,提供了用于管理 MCP 注册表项(列出、获取、创建、更新、删除)的 RESTful API,用于服务监控的 Check Point 等。
在作者的构思中,可以在协议设计层面为工具构建不同的逻辑组,按功能对工具进行聚合,比如将文档处理、表格计算等办公组件整合为 Office 套件,用户在使用的时候不必一个一个的添加,而是一次性订阅工具包即可。
06
核心架构
OK,聊了这么久概念,接下来该转场到技术细节的部分了~

6.1 消息协议:JSON-RPC 2.0
消息协议规定了消息格式标准,也就是服务客户双端之间约定了消息的格式
在 MCP 协议中规定了唯一的标准消息格式,也就是 JSON-RPC 2.0。JSON-RPC 2.0 大家都不陌生,它是一种轻量级的、用于远程过程调用(RPC)的消息交换协议,使用JSON作为数据格式。
比如在一次简单的计算器 MCP 工具调用过程中,JSON-RPC2.0 就使用以下格式:
{ "jsonrpc": "2.0", // 协议版本,固定为 "2.0" "method": "calculate", // 要调用的方法名 "params": { // 方法参数,可以是对象或数组 "expression": "1+1" }, "id": 1 // 请求标识符,用于匹配响应}当 MCP 服务端处理结束后,通过以下格式返回结果:
{ "jsonrpc": "2.0", // 协议版本,固定为 "2.0" "result": "2", // 调用结果 "id": 1 // 对应的请求标识符} 6.2 传输协议: Transports Layer
MCP 协议内置了两种标准传输实现,并在 2025.3.26 引入新的数据传输方式 Streamable HTTP。
标准输入/输出(STDIO)
stdio 传输通过标准输入和输出流实现通信。因为 stdio 模型要求 MCP 服务端运行在客户端本机上,所以对于本地工具栏、命令行工具这些场景比较适用。
stdio 模式需要遵循以下规则:
消息必须为UTF-8编码的JSON-RPC格式,以换行符\n分隔。
服务端通过stderr输出日志,客户端可选择处理或忽略。
严格禁止在stdout中写入非协议消息,避免解析错误。
stdio 模式的传输流程比较简单,看下图即可:

服务器发送事件(SSE)
SSE 是目前大家用的最多的模式,也是最饱受诟病的。SSE 传输支持服务器到客户端的流式传输,并使用 HTTP POST 请求来完成客户端到服务器的通信。
可以看到,SSE 模式使用的是 HTTP POST + SSE,为什么需要加上 SSE?
假如我们只使用 HTTP POST 来完成 MCP 工具调用,那是这样的:

而根据大多 AI 应用场景的特点,HTTP POST 的请求/响应模式采用的是同步阻塞机制,会带来以下问题:
同步阻塞模式:不适应长时间任务需求,长任务处理时客户端线程会挂起,比如复杂的工作流执行可能会使得客户端阻塞
短连接:大多 MCP 客户端会多次与服务端频繁地对话,来访问服务端的资源和工具,这就需要保持会话状态和连接,而默认的 HTTP Keep-Alive 通常小于 60s,存在连接超时风险。
服务端无法推送:服务端不能主动向客户端推送消息,数据流动必须由客户端触发。例如上面提到的 MCP 服务端的采样功能中,依赖于服务端主动推送的能力才可以实现。
流式输出:很多 AI 应用的场景需要流式输出。
基于上述这些主要原因,MCP 协议采用了带有 SSE(Server-Sent Events)的 HTTP 协议作为远程模式下的传输方式。
SSE(服务器发送事件) 是一种基于HTTP协议的单向通信技术,允许服务器主动实时向客户端推送消息,客户端只需建立一次连接即可持续接收消息。它的特点是:
单向传输(服务器→客户端)。
基于 HTTP 协议,借助一次 HTTP Get 请求建立连接。
适合实时消息推送场景(如进度更新、实时数据流等)。
通信过程如下:

一次完整的会话过程如下:
连接建立:客户端首先通过 GET 请求建立 SSE 连接,服务端“同意”,然后生成并推送唯一的 Session ID。
请求发送:客户端通过 HTTP POST 发送 JSON-RPC2.0 请求(请求中会带有 Session ID 和 Request ID 信息)。
请求接收确认:服务端接收请求后立即返回 202 (Accepted) 状态码,表示已接受请求。
异步处理:服务端应用框架会自动处理请求,根据请求中的参数,决定调用某个工具或资源。
结果推送:处理完成后,服务端通过 SSE 通道推送 JSON-RPC2.0 响应,其中带有对应的 Request ID。
结果匹配:客户端的 SSE 连接监听接收到数据流后,会根据 Request ID 将接收到的响应与之前的请求匹配。
重复处理:循环上述过程。
连接断开:在客户端完成所有请求后,可以选择断开 SSE 连接,会话结束。
总结:客户端通过 HTTP POST 发送请求,并通过 SSE 的长连接来异步获得服务端的响应结果。
由于 SSE 是一种单向通信的模式,所以它需要配合 HTTP POST 来实现客户端与服务端的双向通信。这是一种 HTTP POST(客户端->服务端)+ HTTP SSE(服务端->客户端)的伪双工通信模式。
为什么不使用 WebSocket?
上面提到,SSE 采用的是伪双工模式来通信,那么是否可以直接使用双工模式的 WebSocket 来进行通信。
官方团队曾认真探讨过是否应该将 WebSocket 作为远程通信的主要方式,并尝试在其基础上实现断线重连等功能。但最终决定暂时不采用 WebSocket,主要原因如下:
在以 RPC 风格实现 MCP 服务时(例如构建无状态且仅暴露基础工具的服务),若每次调用均依赖 WebSocket 连接,将不可避免地引入额外的网络开销和维护复杂度。
在浏览器环境中,WebSocket 无法像普通 HTTP 请求那样附加请求头(比如 Authorization)。
在 WebSocket 协议实现中,由于 HTTP 方法语义限制(仅 GET 支持直接升级),POST 等非 GET 请求需要采用二次握手机制进行协议升级。这种间接升级模式不仅引入了额外的延迟,还提高了协议状态管理的复杂度。
避免在 MCP 规范中增加 WebSocket 的可选支持,以减少客户端与服务器间可能的兼容性组合问题。(可能会破坏 MCP 协议的统一兼容)
尽管HTTP with SSE的模式带来了很多优点,但也引入了复杂性,存在以下问题:
不支持恢复连接:如果客户端和服务器之间的 SSE 连接中断了,就无法 “从端点继续”,只能重新开始新的连接,之前的上下文可能会丢失。
要求服务器保持高可用的长连接:服务器必须一直保持一个稳定、不中断的 SSE 长连接,否则通信就中断。
服务器只能通过 SSE 发送消息:服务器无法在已有的请求之外,主动地发送消息给客户端,除了通过专门的 /sse 通道。
具体的讨论可以看这里:https://github.com/modelcontextprotocol/modelcontextprotocol/pull/206
Streamable HTTP
基于上述问题,官方团队在 MCP 标准(2025-03-26)中,对目前的传输方式做了调整,改名为Streamable HTTP:

相比于 SSE 模式,其主要变动在于允许服务端根据需要来选择:可以使用简单的无状态模式,也可以按需选择支持目前的 HTTP with SSE 模式。
改动具体包括:
移除了专门的 /sse 端点,所有请求和接收 SSE 流都通过 /message 端点进行,一切通过统一的 /message 协议层处理。
当需要时,服务端可以选择将响应升级为 SSE 流,实现 流式传输 的能力,客户端也可直接通过 GET 请求初始化 SSE 流。
去中心化、无强制要求持续连接,支持 stateless 模式。
使用 Streamable HTTP 的好处在于:
更灵活,不强制使用流式传输,可以按需使用。
简单易用,支持无状态服务端。
兼容 HTTP 协议,不需要再引入额外的协议。
就像聊天一样,原来的 SSE 模式要求通信的时候电话不能挂断,而现在可以随时发消息给对方,然后等别人回复就可以了
07
总结
本质上 MCP 协议是规定了大模型与外界应用沟通的一套标准规范,需要注意的是,MCP 协议只提供统一的工具接口,而无法决定工具将被如何选择和组合。
一个可用的好用的 AI 产品应该是多个组件共同协作的结果:大语言模型(LLM)负责提供基础的自然语言理解与生成能力,智能体(Agent)框架承担任务分解与执行逻辑的协调功能,而模块化控制平台(MCP)则致力于提供标准化的工具调用接口。
-End-
原创作者|杨兹博
感谢你读到这里,不如关注一下?👇

📢📢来领开发者专属福利!点击下方图片直达👇


你认为MCP协议在AI发展中的作用是什么?欢迎评论留言补充。我们将选取1则优质的评论,送出腾讯云定制文件袋套装1个(见下图)。7月2日中午12点开奖。
























 273
273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









