



 字节跳动开源了通用分布式训练框架BytePS,该框架支持多种深度学习平台,如TensorFlow、Keras等,并在性能上超越现有框架。在相同条件下,BytePS的训练速度比Horovod+NCCL快100%。BytePS针对云和共享集群进行了优化,采用了一系列加速技术。
字节跳动开源了通用分布式训练框架BytePS,该框架支持多种深度学习平台,如TensorFlow、Keras等,并在性能上超越现有框架。在相同条件下,BytePS的训练速度比Horovod+NCCL快100%。BytePS针对云和共享集群进行了优化,采用了一系列加速技术。
问耕 发自 凹非寺
量子位 出品 | 公众号 QbitAI
字节跳动开源了通用分布式训练框架BytePS,这个框架支持TensorFlow、Keras、PyTorch、MXNet,可以运行在TCP或RDMA网络中。
官方介绍称,BytePS大大优于现有的开源分布式训练框架。例如,在相同的条件下,BytePS的训练速度是Horovod+NCCL的两倍。
BytePS也登上了GitHub趋势热榜。
性能表现
为了展示BytePS的性能,官方测试了两个模型:VGG16(通信密集型)和Resnet50(计算密集型),两个模型都以fp32精度进行训练。
训练使用了公有云上的虚拟机,每个机器有8个GPU,启用了NVLink。这些GPU都是Tesla V100 16GB型号GPU,batch size设置为64/每GPU。硬件之间以20Gbps的TCP/IP网络连接。
测试表明,与Horovod (NCCL)相比,BytePS在VGG16训练上的速度快100%,Resnet训练速度快44%。
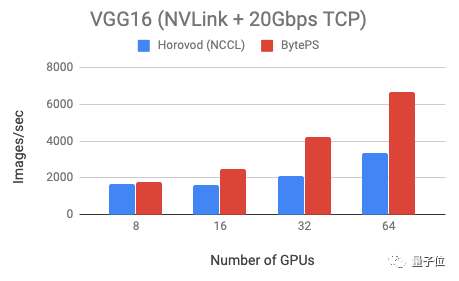
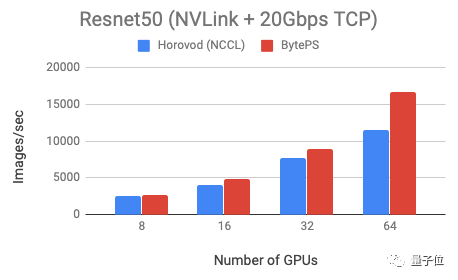
Horovod是Uber开源的深度学习工具,NCCL是英伟达发布的多卡通信框架。
原因解析
BytePS为什么比Horovod更强?
官方解释称,一个主要的原因是BytePS是专门为云和共享集群而设计,并且抛弃了MPI。MPI是一个跨语言的通讯协议,用于编写并行计算机。
MPI是为高性能计算机而生,对于使用同类硬件构建的集群以及运行单一任务更有效。但并不是云(或者内部共享集群)的最佳选择。
因此字节跳动团队重新思考了最佳的通信策略。简而言之,BytePS仅在机器内部使用NCCL,重新构建了机器内部的通信。
BytePS还集成了许多加速技术,例如分层策略、流水线、张量分区、NUMA感知本地通信、基于优先级的调度等等。
传送门
BytePS现已在GitHub上开源,地址如下:
https://github.com/bytedance/byteps
在GitHub上,还详细介绍了如何使用BytePS等相关信息。
目前BytePS还不支持纯CPU训练。
— 完 —
AI社群 | 与优秀的人交流

小程序 | 全类别AI学习教程


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !



















 61
61

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









