



ViLoMem团队 投稿
量子位 | 公众号 QbitAI
多模态推理又有新招,大模型“记不住教训”的毛病有治了。
南京理工大学联合百度等单位提出新方法ViLoMem,通过构建视觉流+逻辑流的双流语义记忆,让模型像人一样把视觉陷阱和推理错误分开存档,做到真正的“从错误中学习”。
在六个多模态基准中,ViLoMem让GPT-4.1 在MathVision上暴涨+6.48,小模型Qwen3-VL-8B在MMMU上提升 +4.38。
而且不需要任何微调,强模型积累下来的记忆还能直接迁移给小模型,起到类似”免费知识蒸馏”的效果。

整体来看,ViLoMem 做了三件关键的事:
把视觉错误和逻辑错误显式拆开存储;
为两种记忆分别设计生成、检索和更新机制;
通过增长-精炼机制控制记忆规模。
在不改动大模型参数的前提下,ViLoMem能在多个多模态基准上稳定拉升表现,尤其是在需要精细视觉理解的数学与真实场景推理任务上,为构建真正“会从经验中长记性”的多模态智能体提供了一条很有潜力的道路。
大模型的“金鱼记忆”
过去,大模型能背下全互联网,却很难记住自己刚犯过的错——这听上去有点好笑,但却是当前多模态大模型(MLLM)的真实写照。
在多模态解题任务里,大模型经常出现这样的场景——上一题刚刚栽在“把等腰三角形看成等边”上,下一题遇到类似图形,依然毫不犹豫地再犯一次。
也就是说,每道题都在“从零开始”,之前踩过的坑几乎没形成结构化经验。
现有的记忆增强方法通常会在模型外接一个“记忆库”,但大多只存储推理轨迹(trajectory),因此带来了两个核心问题。
一是简短性偏差(Brevity Bias),也就是经历过多轮压缩、总结之后,很多关键细节被抹平,最后只剩下一些“空洞结论”。
二是单模态盲区,即便任务本身是多模态的,这些方法也主要记录文本推理过程,很少追踪“到底是哪里看错了”。
但人类并不是这样记忆的。
认知科学研究表明,人类的语义记忆天生就是多模态整合的,既会记住“这道题要用勾股定理”(逻辑规则),也会记 “这个角看着像直角其实不是”(视觉经验)。
ViLoMem正是沿着这个方向,把视觉和逻辑错误拆开来专门建库。
双流语义记忆ViLoMem
为了解决上述问题,作者提出了一个即插即用的双流记忆框架ViLoMem(Visual-Logical Memory)。
用一句话概括这个框架就是,把“看错了什么”和“想错了什么”分开记忆。
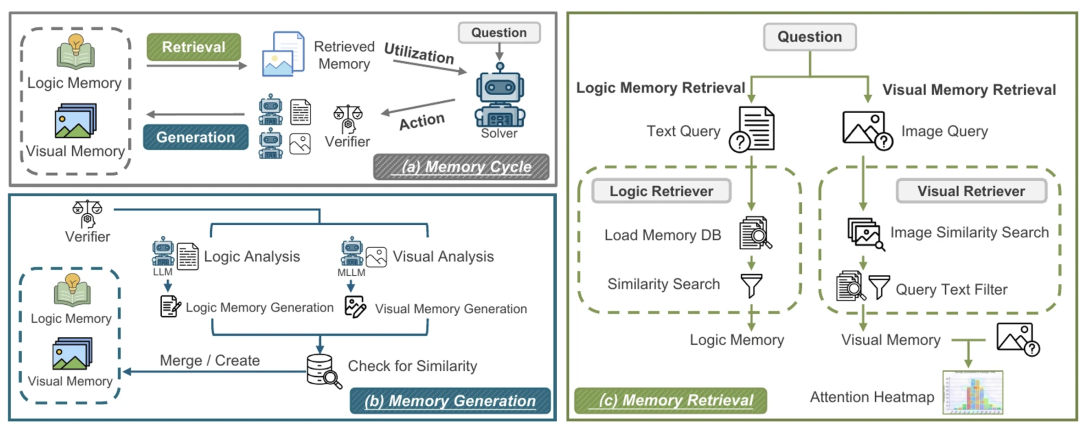
结构上,ViLoMem包含两个关键部分——记忆生成和记忆检索。
记忆生成:给每一次失败写下”错因小结”
当模型在某道题上翻车时,ViLoMem会并行启动两个分支。
一是视觉分析模块(MLLM),主要就是回答一个问题——这次是“眼睛”出了什么问题?
一旦确定是视觉层面的锅,系统会生成一条结构化的视觉指南(Visual Guideline),例如:
在判断物体材质时,应优先对比其与场景中已知金属物体的高光形态和纹理,而不是仅凭整体亮度做判断。
二是逻辑分析模块(LLM),这里关注的是推理链条哪一步出了问题?
对应的逻辑记忆可能长这样:
在涉及垂直平分线的几何问题中,只有位于平分线上的点才保证到线段两端点等距;除非有明确条件,否则不要默认某点在垂直平分线上。
为了增强记忆的通用性,新生成的记忆不会直接塞进库里,而是先和已有记忆做相似度匹配。
如果能够找到高度相似的条目,那就合并成更抽象、更通用的规则,找不到的话再新开一个记忆槽位。
这种Grow-and-Refine机制既避免记忆无限膨胀,又能让记忆从具体案例中不断抽象出更普适的语义模式。
记忆检索:视觉和逻辑两条路,各司其职
在处理新问题时,两类记忆的检索策略也不同。
视觉记忆采用了两阶段的检索模式,同时也引入了注意力图。
第一阶段是图像级相似度搜索,利用多模态嵌入,先在整个视觉记忆库里筛一批“看上去像”的候选样本;
第二阶段则是问题语义过滤,也就是通过文本嵌入,对这些候选样本进行问题相关性过滤,保证“问的问题也类似”。
在检索到合适的视觉记忆后,ViLoMem还会生成问题感知的注意力热力图,在图上高亮历史上最容易被忽视或看错的区域,相当于给模型发了一份“视觉踩坑指南”。
逻辑记忆的检索方式则是先理解题目,再找对应规则,其过程更偏向“题型分析”——
先让模型判断问题属于哪门学科、涉及哪些关键概念;
再基于分析结果构造查询向量,在逻辑记忆库中做语义匹配;
只保留相似度超过阈值的高相关记忆作为候选。
这种“先理解题目,再去库里翻笔记”的方式,比简单关键词匹配要干净得多。
六大基准全线提升
作者在六个多模态推理基准上系统评估了ViLoMem,结果不管大模型、小模型都能够吃到红利。
从任务维度看,数学类任务收益最大,例如GPT-4.1在 MathVision上+6.48,在MathVista上+2.61;
而从模型规模上看,小模型提升幅度更大,例如Qwen3-VL-8B在MMMU上+4.38,在RealWorldQA上+2.74。
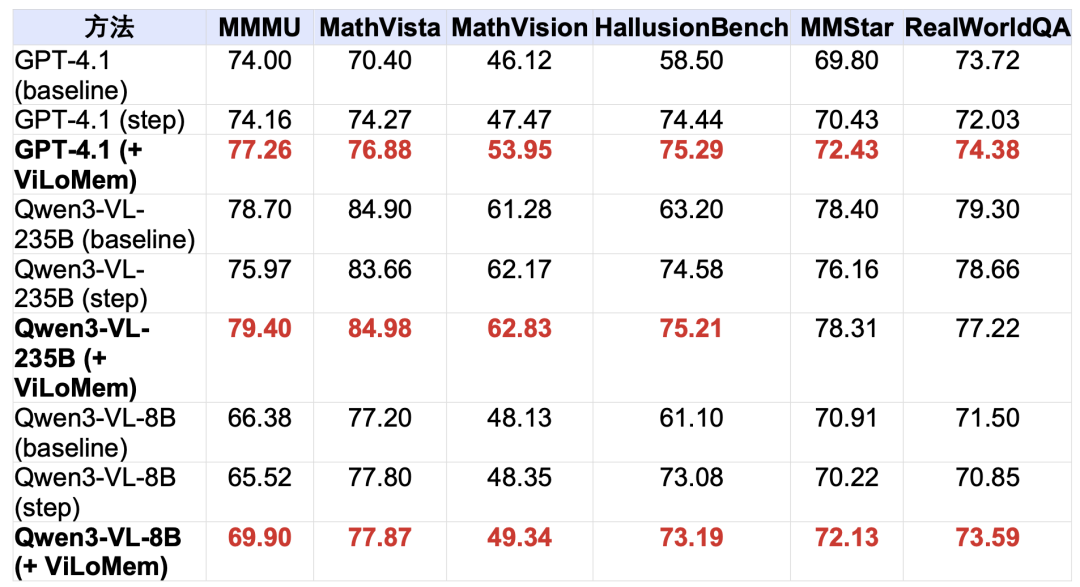
这一结果符合直觉,因为数学和视觉密集任务对“看准了再算”要求最高,双流记忆能有效阻断视觉错误向推理链条的级联传播。
作者还做了一个有意思的“跨模型记忆迁移”实验——让大模型“带小弟刷分”,也就是小模型直接使用大模型生成的记忆,看分数会发生什么变化。
结果显示,小模型拿着大模型的记忆成绩更好。

这意味着ViLoMem提供了一种“免微调的知识蒸馏”路径——强模型踩过的坑,可以直接变成弱模型的经验。
项目主页:https://vi-ocean.github.io/projects/vilomem/


















 8
8

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









