



MemVerse团队 投稿
量子位 | 公众号 QbitAI
一页纯文本的记忆是看不清世界的。
人与世界的交互天然是多模态的。一张产品设计图、一段用户操作录屏、一次包含语音和演示的线上会议,这些由图像、声音、视频构成的高维业务信息,正成为驱动AI智能体创造价值的关键来源。
当前绝大多数“长期记忆”系统在架构上仍设计为纯文本的记忆库。但智能体的“记忆”不应该是扁平的文本日志,而是一个能够记录并关联 “在何时、看到了何物、讨论了何事” 的多维体验图谱。这种跨模态、跨时间的记忆关联与融合能力,是智能体从被动工具进化为智能助手的关键要素。
为了攻克这一挑战,上海人工智能实验室正式开源MemVerse—首个面向智能体的通用多模态记忆框架。它突破性地将图像、音频、视频等多模态信息与文本对齐到统一的语义空间进行记忆,并首创 “双通路”架构与“记忆蒸馏” 技术,让智能体首次拥有了可成长、可内化、秒级响应的终身记忆能力。
从“文本堆叠”到“模态融通”:MemVerse实现多模态记忆的范式跃迁
Agent需要的不是更大的“硬盘”,而是一个会思考的“大脑”。
现有的LLM Agent,无论上下文窗口如何扩展,仍面临灾难性遗忘与模态割裂的双重困境。
传统方法在处理文本时尚可应对,一旦面对图像、视频等多模态信息流,便显得力不从心,通常只能进行机械的切片与检索,无法理解信息内在的时空逻辑与跨模态语义。
针对这一根本性挑战,上海人工智能实验室-数据前沿团队提出全新解决方案:多模态记忆系统MemVerse。
它从人类认知的经典记忆模型中汲取灵感,旨在构建一个包含中央协调器、双通路记忆与参数化蒸馏的完整闭环,实现从“被动数据检索”到“主动记忆运用”的范式转移。

仿生进化:为Agent构建“海马体-皮层”协同架构
MemVerse的核心是一个精密的三层仿生记忆架构,模拟了人类信息从暂存、结构化到内化的完整认知过程。
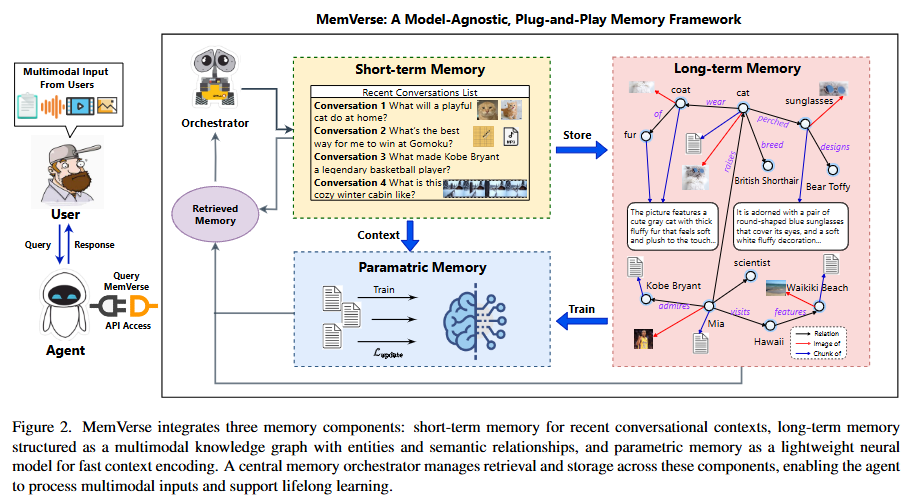
- 中央协调器(Orchestrator):作为系统的“前额叶”,它主动感知交互情境,智能决策记忆的读取、写入与更新,并动态调度不同记忆模块。这改变了传统Agent被动查询数据库的模式。
- 短期记忆(STM):采用滑动窗口机制,像“工作记忆”一样保持对话的即时连贯性,确保智能体不会“忘了上一句说了什么”。
- 长期记忆(LTM):构建多模态知识图谱,将记忆结构化为核心记忆(用户画像)、情景记忆(事件时间线)和语义记忆(抽象概念)。这使智能体能进行深度的关联推理,从根本上缓解“幻觉”问题。
- 参数化记忆与周期性蒸馏:这是MemVerse的高效来源。系统会定期将长期记忆中的高价值知识,通过轻量微调“蒸馏”到一个专用的小模型中,实现知识的参数化内化。相当于让智能体将常用知识转化为“肌肉记忆”,检索响应速度提升10倍以上,解决了结构化存储的性能瓶颈。
实测表现:多模态任务能力与效率的跨越式提升
在权威基准测试中,MemVerse证明了其架构的优越性:
ScienceQA(科学问答): 搭载MemVerse后,GPT-4o-mini的综合得分从76.82跃升至85.48,实现了接近9个百分点的跨越式提升。
这意味着,MemVerse能让一个轻量级商用模型获得堪比千亿参数大模型的深度认知能力,为开发高性价比的“小而强”智能体提供了关键技术路径。
MSR-VTT(视频检索): 得益于多模态知识图谱,MemVerse在视频细节回忆上的R@1召回率大幅超越了CLIP(29.7%)等传统方法,更显著超过了包括ExCae(67.7%)、VAST(63.9%)在内的专用大模型。
极致效率:通过高效的记忆压缩与知识“蒸馏”机制,MemVerse 在维持高精度的同时,能减少高达90%的Token消耗,大幅降低了长期记忆的运营成本与延迟。
凭借独特的双通道记忆设计,MemVerse 将关键记忆的提取速度提升至毫秒级。
开源与传送门:迈向通用智能体记忆的基石
MemVerse为构建具备终身学习能力的智能体提供了一套通用、可扩展的多模态记忆范式,较小的模型也能通过搭载MemVerse具备深度的记忆与推理能力。
目前,该项目已由上海人工智能实验室开源,欢迎开发者试用。
论文地址:https://arxiv.org/pdf/2512.03627
项目主页:https://dw2283.github.io/memverse.ai
GitHub:https://github.com/KnowledgeXLab/MemVerse


















 534
534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









