



闻乐 发自 凹非寺
量子位 | 公众号 QbitAI
距第二篇研究仅过去三天,Thingking Machines发布了第三篇研究博客。
核心作者是OpenAI联创之一John Schulman。
Thingking Machines创始人、OpenAI前CTO Mira Murati继续转发站台。

第三篇研究是关于LoRA参数的高效微调方法,题目为《LoRA Without Regret》,探究了LoRA匹配全量微调(FullFT)效率的条件,还给出了大幅降低调参难度的简化方案。

当前主流大模型动辄万亿参数,预训练数据达数十万亿token,但下游任务往往只需要小数据集、聚焦特定领域。
用FullFT更新所有参数,资源浪费严重。
而LoRA作为参数高效微调(PEFT)的核心方法,通过低秩矩阵A和B(总参数远少于原权重)捕捉微调信息,却始终面临一个争议:它真的能追上FullFT的性能吗?
John Schulman和Thingking Machines团队给出了肯定答案:只要抓准关键细节,LoRA不仅能和FullFT拥有相同的样本效率,还能达到一样的最终性能。
下面具体来看。
LoRA最优学习率是FullFT的10倍
研究团队通过多组实验提炼出三个核心发现:
在中小数据集中,LoRA与FullFT性能相当;
LoRA应用不能仅聚焦于注意力层,全能覆盖性能最优
LoRA的最优学习率为FullFT的10倍
首先,在中小数据集微调场景下,LoRA完全具备与FullFT抗衡的能力。
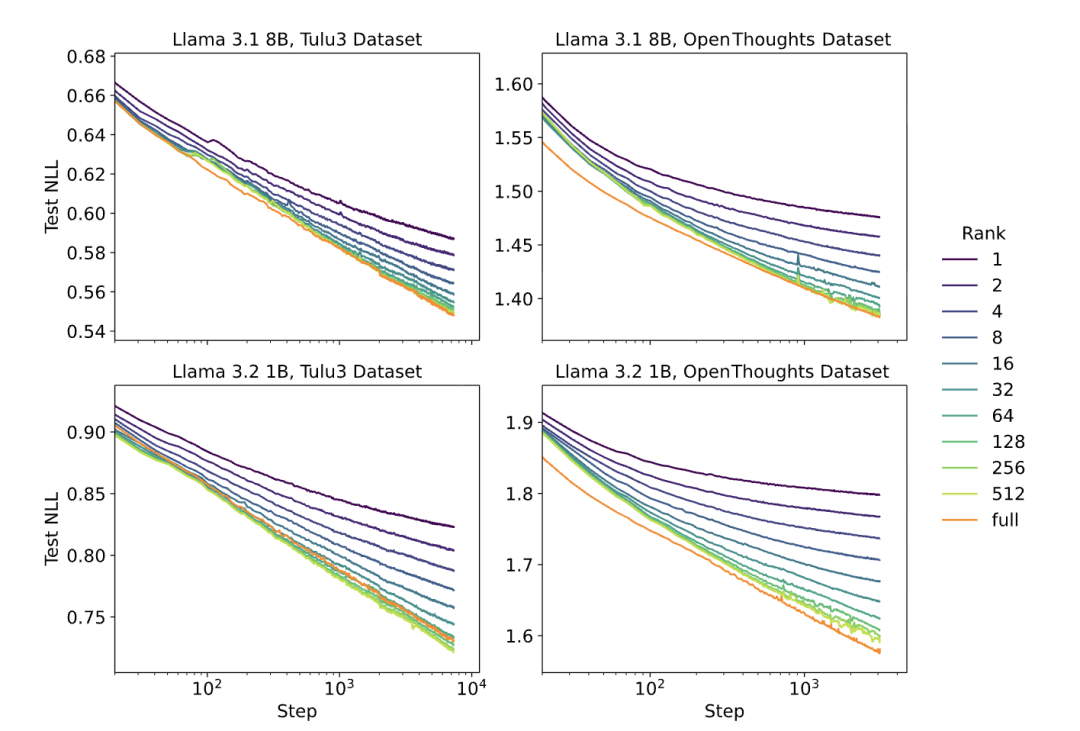
研究团队采用Llama 3、Qwen3系列模型,分别在聚焦指令跟随的Tulu3数据集和侧重推理任务的OpenThoughts3数据集上展开测试。
结果显示高秩LoRA(如秩512)的学习曲线与FullFT几乎完全重合,两者的损失值均随训练步数呈对数线性下降趋势;
只有当数据集规模远超LoRA自身容量时,其训练效率才会出现下滑,而这种极端情况在多数后训练场景中极少出现。
并且,在MATH、GSM等数学推理类强化学习任务中,即便将LoRA的秩降低至1,其性能依旧能与FullFT持平。
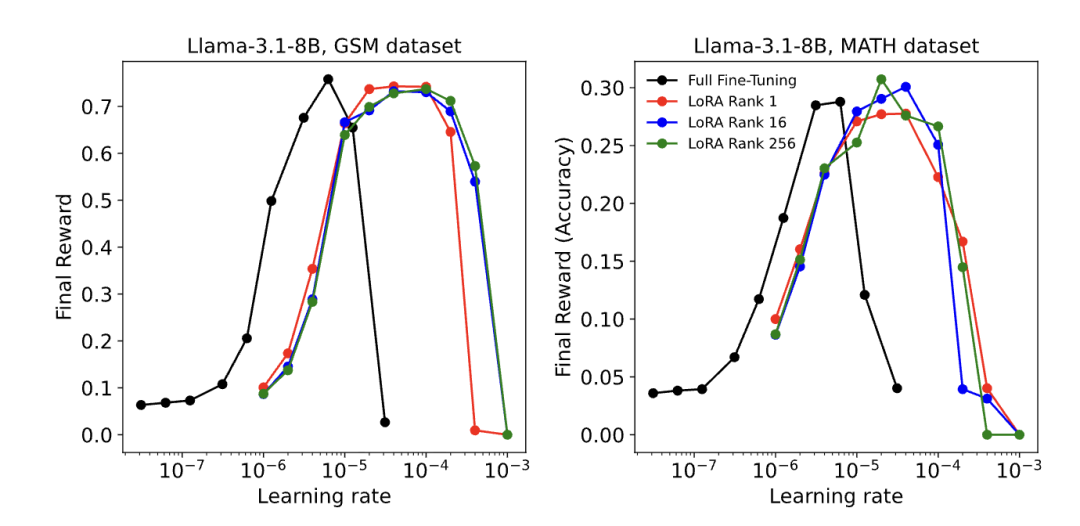
这一现象的背后,是强化学习的信息需求特性:每轮训练仅需依靠scalar优势函数吸收 O (1) 比特信息,而秩1 LoRA的参数容量早已满足这一需求,甚至存在大量冗余。

其次,在LoRA的应用层选择上,全层覆盖才是发挥其性能的关键,而非传统认知中仅聚焦注意力层。
过去不少研究习惯将LoRA仅应用于注意力矩阵,但此次实验结果却打破了这一固有思路。
仅作用于注意力层的LoRA表现明显落后,即便通过提升秩(如秩256)来匹配MLP层LoRA(秩128)的参数量,性能差距依然显著;
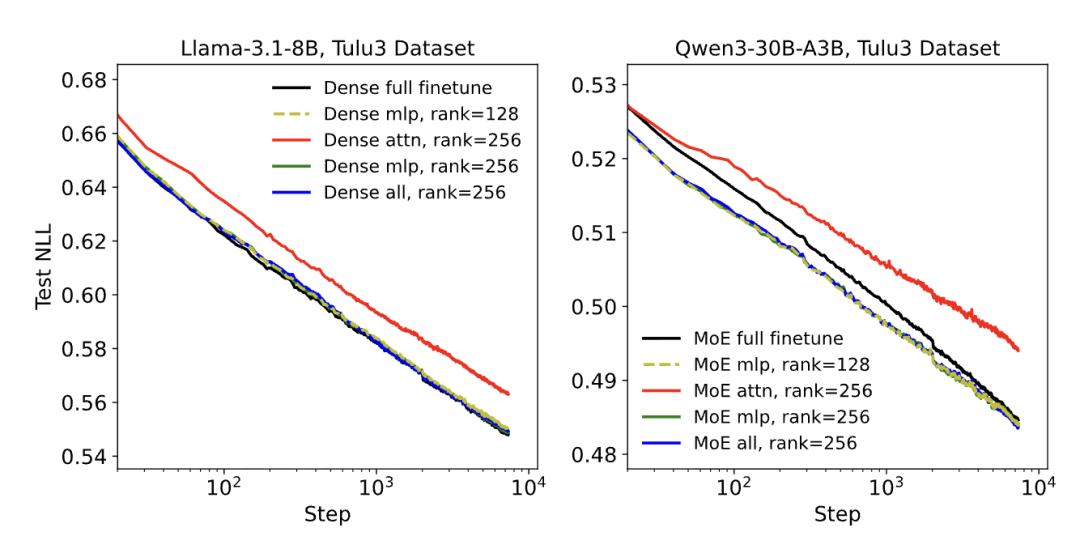
而当LoRA应用于模型所有层,尤其是参数占比最高的MLP层与MoE层时,性能得到极大提升,甚至仅在MLP层单独应用LoRA,效果就与“MLP层+注意力层”组合应用相差无几。
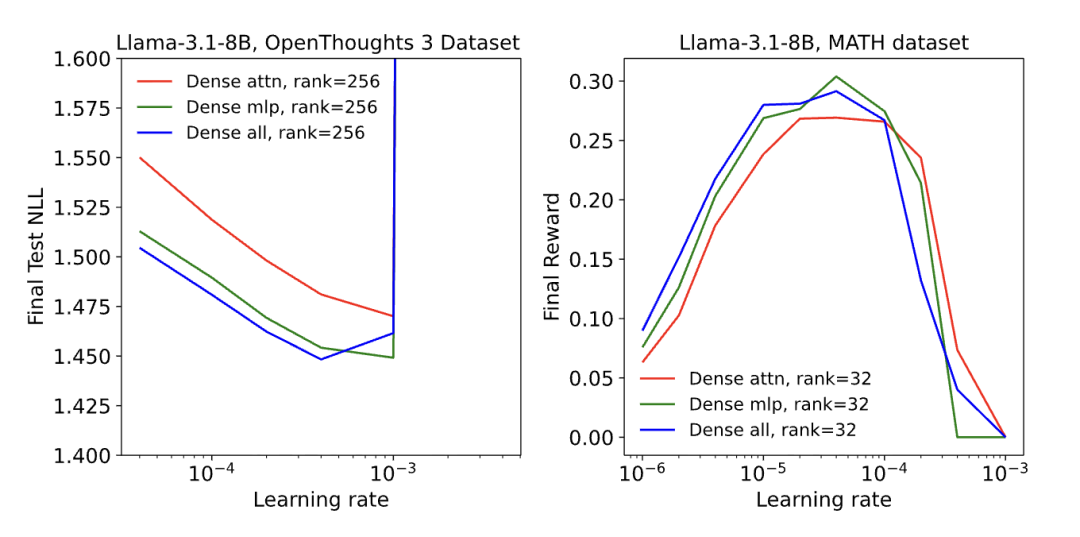
这一结果的逻辑的核心在于,模型梯度的主导权掌握在参数数量更多的层手中,只有实现全层覆盖,LoRA的优化动态才能真正接近FullFT,从而释放出与FullFT相当的性能。
最后,针对LoRA超参数难调试的痛点,研究团队给出了大幅降低调试难度的简化方案。
许多使用者曾因超参数调试复杂对LoRA望而却步,但研究发现,LoRA的最优学习率存在明确规律——始终约为FullFT的10倍。(为观察结果,团队表示还将进一步完善理论框架)
并且,这一比例在14个不同模型在Tulu3数据集的测试中几乎保持恒定。
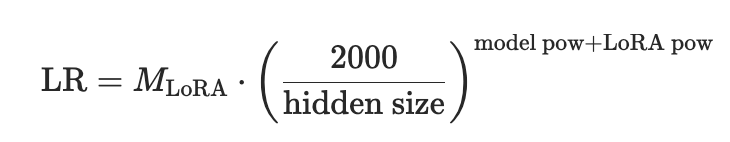
同时,得益于1/r 缩放因子的作用,不同秩LoRA的最优学习率差异极小,在秩4至秩512的范围内,变化幅度不足2倍,在短期训练任务中,甚至可直接忽略秩对最优学习率的影响。
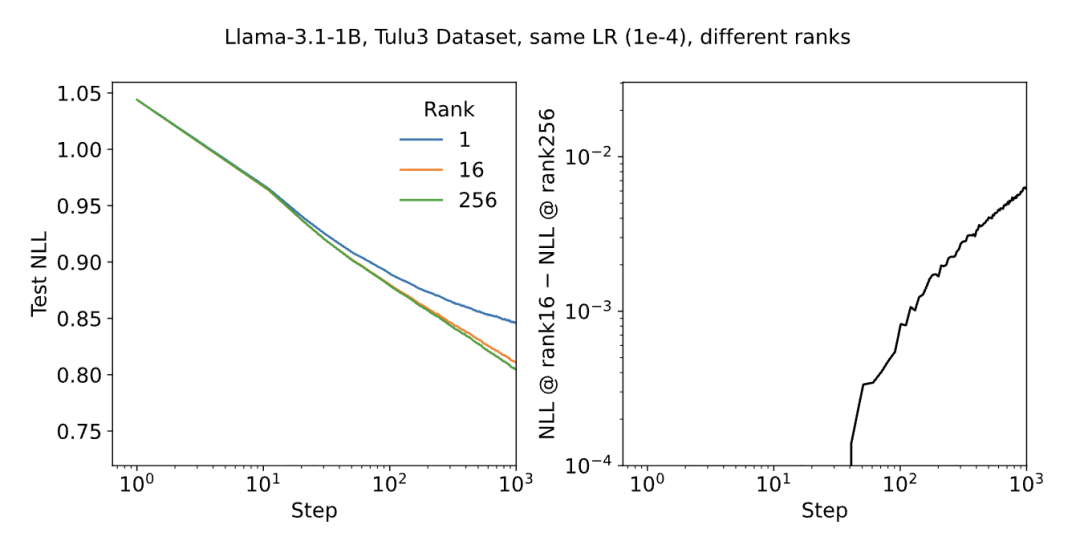
更具实用性的发现是,LoRA的4个潜在超参数中,有2个属于冗余参数,实际调试过程中只需重点关注“初始更新规模”与“A矩阵偏离初始状态的步数”两个维度。
这一发现直接将LoRA的调参难度降低了一半。
ChatGPT架构师John Schulman
这项研究的核心作者是OpenAI联创、跑去Anthropic不到半年又火速加入Thingking Machines的John Schulman。

John Schulman博士毕业于加州大学伯克利分校,师从强化学习大牛Pieter Abbeel
联合创立OpenAI后,他曾在OpenAI工作9年,领导了从GPT-3.5、GPT-4到GPT-4o的一系列对齐/后训练工作,被誉为ChatGPT架构师。
Google Scholar页面显示,John Schulman的学术引用将近14万。
其中,引用量最高的《Proximal policy optimization algorithms》是他的代表作,PPO算法也是ChatGPT核心技术RLHF中选用的强化学习算法。
当初离开OpenAI时,John Schulman公开提及自己的职业规划是渴望回归核心技术领域。
而这一想法也推动他最终加入Thinking Machines,现以首席科学家的身份开启新的工作阶段。
参考链接:
[1]https://x.com/thinkymachines/status/1972708674100765006
[2]https://thinkingmachines.ai/blog/lora/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!



















 58
58

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









